版本记录
| 版本号 | 时间 |
|---|---|
| V1.0 | 2018.10.07 星期日 |
前言
很多做视频和图像的,相信对这个框架都不是很陌生,它渲染高级3D图形,并使用GPU执行数据并行计算。接下来的几篇我们就详细的解析这个框架。感兴趣的看下面几篇文章。
1. Metal框架详细解析(一)—— 基本概览
2. Metal框架详细解析(二) —— 器件和命令(一)
3. Metal框架详细解析(三) —— 渲染简单的2D三角形(一)
4. Metal框架详细解析(四) —— 关于GPU Family 4(一)
5. Metal框架详细解析(五) —— 关于GPU Family 4之关于Imageblocks(二)
6. Metal框架详细解析(六) —— 关于GPU Family 4之关于Tile Shading(三)
7. Metal框架详细解析(七) —— 关于GPU Family 4之关于光栅顺序组(四)
8. Metal框架详细解析(八) —— 关于GPU Family 4之关于增强的MSAA和Imageblock采样覆盖控制(五)
9. Metal框架详细解析(九) —— 关于GPU Family 4之关于线程组共享(六)
10. Metal框架详细解析(十) —— 基本组件(一)
11. Metal框架详细解析(十一) —— 基本组件之器件选择 - 图形渲染的器件选择(二)
Device Selection and Fallback for Compute Processing - 计算处理的设备选择和后退
演示如何使用多个GPU并有效执行计算密集型仿真。
本篇是macOS相关,要是看关于iOS的请忽略这篇文章。
Overview - 概览
macOS支持具有多个GPU的系统,使Metal应用程序能够提高计算能力。 一个例子是iMac Pro,它具有内置的独立GPU并连接到多个外部GPU。 外部GPU可以比内置GPU更强大,因此它们是计算密集型工作负载的绝佳选择。 但是,为了利用这种增加的功能,Metal应该准备安全地处理添加和删除任何外部GPU以实现更强大的执行。 无论一个GPU还是多个GPU可用于系统,Metal应用程序应始终表现良好。
Sample Simulation Modes - 样本模拟模式
此示例执行N-body模拟,并在模拟进展到完成时连续呈现模拟的中间结果的子集。 模拟完成后,样品将所有N-body粒子渲染到最终状态,呈现全套最终结果。
该示例以两种模式之一运行,具体取决于系统可用的GPU数量。
Simulation with a single Metal device - 使用单个Metal设备进行模拟。 当只有一个Metal设备可用时,样本执行模拟并连续呈现中间结果。 计算模拟和图形渲染由同一设备在同一线程上执行。
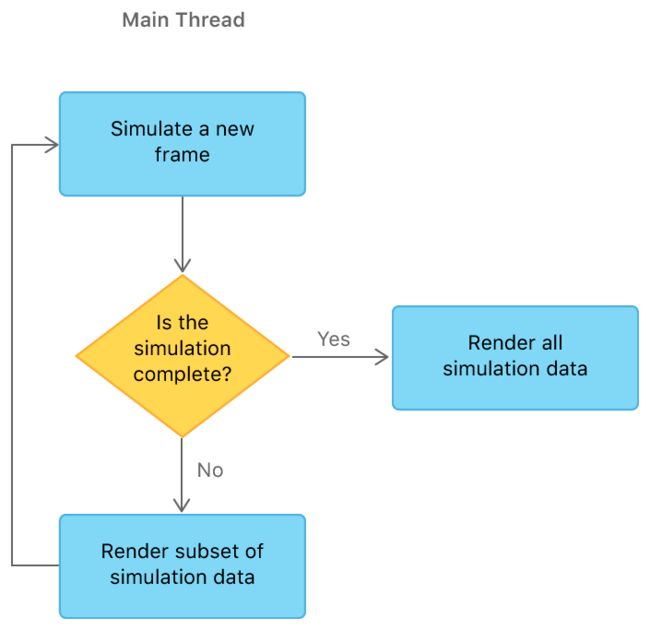
Simulation with multiple Metal devices - 使用多个Metal设备进行仿真。当有多个Metal设备可用时,该示例会产生第二个线程,以分隔两个GPU之间的计算处理和图形渲染工作。 线程并发和重复运行,共享数据如下:
- 模拟线程生成中间结果并将其传输到系统内存。
- 渲染线程 - 主线程 - 消耗并呈现系统内存的中间结果。 (所有图形渲染都发生在主线程上。)
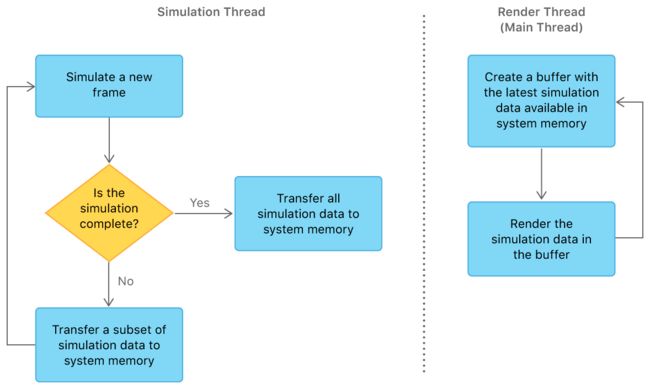
线程不会彼此等待;他们以不同的速度独立工作。 模拟线程尽可能快地运行,渲染线程的运行速度与显示器的帧速率一样快。
Handle External GPU Notifications - 处理外部GPU通知
当外部GPU连接到系统时,此示例在外部GPU上执行计算模拟,并在内置GPU上执行图形渲染。否则,该示例在单个内置GPU上执行计算和图形工作。
当样本收到外部GPU移除通知时,它会将所有计算模拟数据从外部GPU传输到应用程序的视图控制器,后者会将数据传输到内置GPU。此动态响应可确保有效保留和传输计算模拟的结果,以便在新GPU上继续处理。它还确保不会丢弃正在进行的工作,并且不会重新开始模拟。
当示例收到外部GPU添加的通知时,它首先使用内置GPU完成当前模拟,然后使用外部GPU启动下一次模拟。
此示例实现了 Device Selection and Fallback for Graphics Rendering示例中描述的许多技术。有关处理外部GPU通知的信息,请参阅该示例的以下部分:
- 设置GPU弹出策略
- 注册外部GPU通知
- 响应外部GPU通知
- 从通知中取消注册
Transfer Simulation Data Between Devices - 在设备之间传输模拟数据
此示例使用两个单独的类来编码Metal命令:用于计算命令的AAPLSimulation和用于图形命令的AAPLRenderer。 该示例使用模拟类创建计算管道,初始化N-body数据集并执行模拟。 该示例使用渲染器类创建渲染管道并绘制模拟生成的N-body数据。 (该示例使用AAPLViewController类来分隔模拟和渲染器类之间的工作。)
当示例在单个设备上运行时,视图控制器将连续执行模拟和渲染器工作。 对于每个帧,它们都将命令编码到相同的MTLCommandBuffer,并且它们都通过相同的MTLBuffer共享N-body粒子的位置。

当示例在多个设备上运行时,视图控制器将模拟工作分配给一个设备,渲染器工作到另一个设备。 模拟在单独的模拟线程上循环重复执行。 对于每次迭代,它会更新N-body粒子的位置,并将此数据blits到由系统内存支持的新MTLBuffer。 该示例将此系统内存支持传递给视图控制器,然后视图控制器将其传递给渲染器。 渲染器在主线程的循环中重复执行。 对于每次迭代,它创建一个新的MTLBuffer,由模拟线程填充的相同系统内存支持,并根据最新的可用位置数据呈现N-body粒子。
注意:
MTLBuffer不能直接在不同设备之间传输;其数据必须通过系统内存传输。
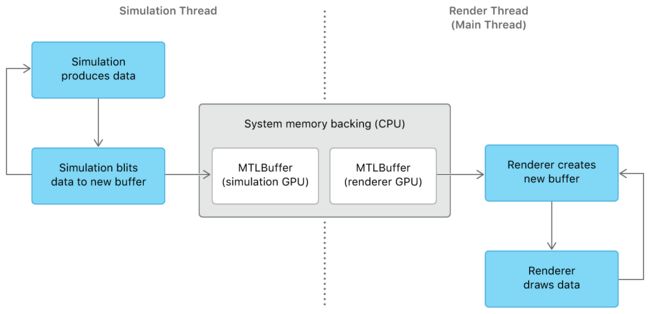
Allocate System Memory for a Buffer - 为缓冲区分配系统内存
该示例调用vm_allocate函数来分配页面对齐的缓冲区updateAddress,由系统内存支持。 然后该示例调用newBufferWithBytesNoCopy:length:options:deallocator:方法创建一个新的MTLBuffer,_updateBuffer,由用于前一个缓冲区的相同系统内存支持。
void *updateAddress;
kern_return_t err = vm_allocate((vm_map_t)mach_task_self(),
(vm_address_t*)&updateAddress,
updateDataSize,
VM_FLAGS_ANYWHERE);
assert(err == KERN_SUCCESS);
_updateBuffer[i] = [_device newBufferWithBytesNoCopy:updateAddress
length:updateDataSize
options:MTLResourceStorageModeShared
deallocator:nil];
由于应用程序直接负责管理此系统内存,因此该示例调用initWithBytesNoCopy:length:deallocator方法将updateAddress缓冲区包装在NSData对象中。 此方法允许样本注册解除分配器deallocProvidedAddress,以便在应用程序不再有对缓冲区的引用时释放系统内存。
// Block to deallocate memory created with vm_allocate when the NSData object is no
// longer referenced
void (^deallocProvidedAddress)(void *bytes, NSUInteger length) =
^(void *bytes, NSUInteger length)
{
vm_deallocate((vm_map_t)mach_task_self(),
(vm_address_t)bytes,
length);
};
// Create a data object to wrap system memory and pass a deallocator to free the
// memory allocated with vm_allocate when the data object has been released
_updateData[i] = [[NSData alloc] initWithBytesNoCopy:updateAddress
length:updateDataSize
deallocator:deallocProvidedAddress];
后记
本篇主要讲述了计算处理的设备选择,感兴趣的给个赞或者关注~~~
