来源:InThirty
作者:白苏
简介:不务正业的智慧医疗产品经理一枚
源码:见评论区
目录
背景介绍
目标分析
准备工作
爬虫分析
爬虫小结
正文共6409字8图,预计阅读时间17分钟
背景介绍
工作关系,一直有在关注国内医药电商行业。
2018年9月,孵化自原1号店医药电商版块的1药店母公司在美国纳斯达克交易所挂牌上市,也将国内医药B2C电商这个概念再次推到了大众面前。本篇文章也是希望通过1药网这个国内医药电商巨头入手,以微知著,通过数据来看看医药电商是否逐渐在改变这一代人的购药习惯。
目标分析
所谓知己知彼,百战不殆,在爬虫工作开始之前,首先需要对我们的目标有个比较深入的了解,这能够极大地提升后面的工作效率,起到事半功倍的作用。
- 商品列表
1药网首页跟普通的B2C交易网站大同小异,从首页的分类上我们能够看出平台商品的大致分类情况,商品这块数据的抓取,也将会从分类入手。
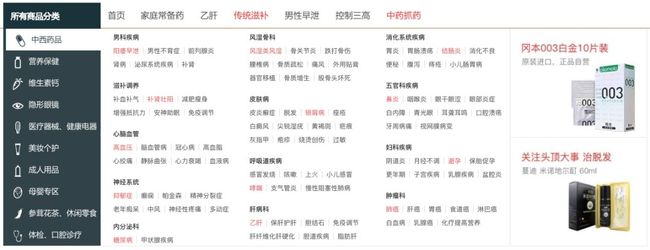
点击进入category页面之后,网站将所有一、二、三级分类全部展示出来了,而三级之后即对应具体的商品列表,所以商品数据的获取思路也就不言而喻了

- 商品详情
医药电商的商品详情还是有别于普通电商的,主要在于标准药品信息、药品说明书这两块,整个商品详情分四个部分:
- 商品信息
包含商品分类、图片、名称、商家、等等商品基本信息
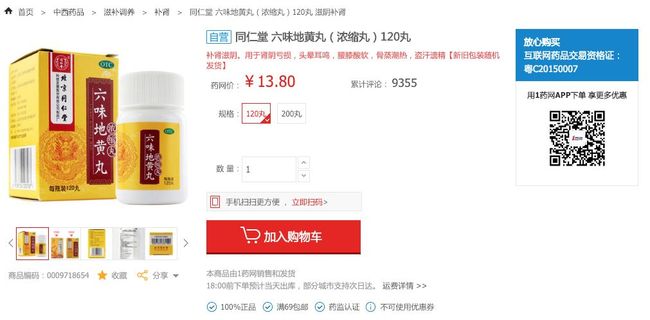
- 药品信息
包含批准文号、药品类型、规格等药品基本信息

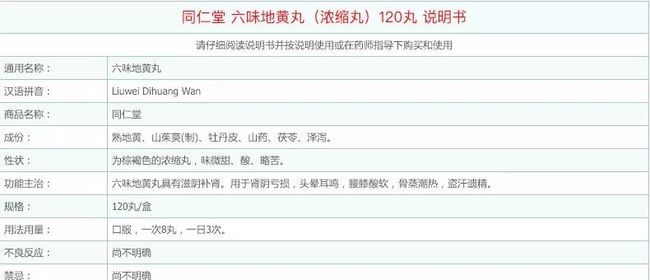
- 药品说明书
这块是药品的特殊信息,非药商品的话没有这一部分,具体分析见代码分析部分
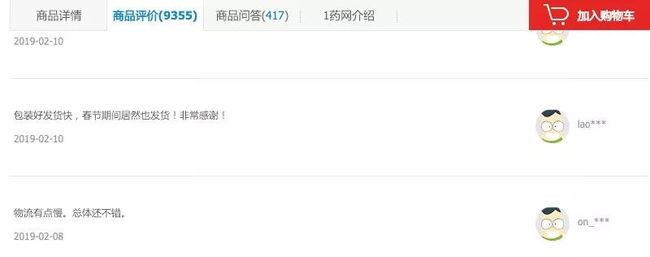
- 商品评价
由于从商品数据上没法看出一个商品的销售数据,所以只能另辟蹊径,通过评论数据来分析
准备工作
- 项目环境
Python3.7+macOS+Mongodb
数据存储方面的话选择的是Mongodb,因为本身我也不是开发人员,所以用什麽考虑自身顺手比较重要
- 爬虫框架
Pyspider+PhantomJS
1药网的商品数据部分是通过JS动态加载的,所以这里选用Pyspider这个爬虫框架,结合PhantomJS对付它绰绰有余
Requests+BeautifulSoup
原先评论数据也一起写了,但是跑起来之后发现一条商品对应的评论数会很多,对整体的效率影响很大,所以就单独出来另外爬
- 其它库
pymongo
Python下的Mongodb驱动
re
用于正则匹配
爬虫分析
- Pyspider介绍
安装相关的这里就不再细讲了,需要注意的一点是PhantomJS安装之后一定要配置好环境变量,win和mac的配置方式也不同,具体各位可以自行查阅相关文档。
全部安装完成之后,直接敲pyspider命令即可全模式启动,这个时候如果PhantomJS环境变量配置没问题的话,PhantomJS会一同启动。
没报错的话,浏览器输入127.0.0.1:5000即可访问pyspider控制台,页面如下图
点击Create,输入项目名称以及目标URL,即可创建一个新的爬虫项目,默认代码如下
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2019-02-13 18:07:19
# Project: 222
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://test.com', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}
以上代码就是官网的Quickstart实例,我就直接翻译文档解释一下
def on_start(self)是脚本的入口. 当点击run按钮的时候,它将被调用。self.crawl(url, callback=self.index_page)* 是这里最重要的API. 它将会添加一个爬虫任务到待爬列表. 大多数配置信息通过self.crawl的参数来指定。def index_page(self, response)获得一个Response* 对象.response.doc* 是一个pyquery对象(可以通过类似jQuery的API去提取元素)。def detail_page(self, response)返回一个字典对象作为结果。结果默认会被捕获进自带的resultdb,你可以通过on_result(self, result)方法去管理。商品部分代码分析
爬虫入口(on_start)
从网站的分类页面入手,获取到的response传给categories_page这个方法,
validate_cert=False
关闭证书验证
fetch_type='js'
动态加载
def on_start(self):
self.crawl('https://www.111.com.cn/categories/', callback=self.categories_page, validate_cert=False, fetch_type='js')
分类URL获取
通过css选择器选取各三级分类的URL信息,再将URL传给下一个方法处理
def categories_page(self, response):
for each in response.doc('.allsort em > a').items():
self.crawl(each.attr.href, callback=self.cagetory_list_page, validate_cert=False, fetch_type='js')
商品URL获取
由于商品列表是分页的,在获取商品URL的时候还需要处理分页,所以该方法中next即获取下一页的URL,并传给自身方法再次获取下一些的商品URL,直到没有下一页为止
def cagetory_list_page(self, response):
for each in response.doc('#itemSearchList a[target="_blank"][class="product_pic pro_img"]').items():
self.crawl(each.attr.href, callback=self.detail_page, validate_cert=False, fetch_type='js')
next = response.doc('#search_table > div.turnPageBottom > a.page_next').attr.href
self.crawl(next, callback=self.cagetory_list_page, validate_cert=False, fetch_type='js')
商品详情获取
篇幅问题,抽主要代码做思路分析,具体代码见Github。
首先通过css选择器获取详情页上的商品信息,其中关于药品说明书那一块,由于非药商品是没有的,而且有的话,字段也不一致,所以先通过标签判断是否存在,存在的话,再依次按照元素存到字典中
最后通过insert方法将整个商品信息字典插入到数据库
def detail_page(self, response):
goods_id = response.doc('#gallery_view > ul > li.item_number').text()
total_comments = response.doc('#fristReviewCount > span > a').text()
instructions = {}
if response.doc('#prodDetailCotentDiv > table > tbody > tr:nth-child(1) > th').text():
for i in range(3,22):
instructions_key = response.doc('#prodDetailCotentDiv > table > tbody > tr:nth-child({}) > th'.format(i)).text().split(" ")[0]
instructions_value = response.doc('#prodDetailCotentDiv > table > tbody > tr:nth-child({}) > td'.format(i)).text()
instructions[instructions_key] = instructions_value
url_id = re.findall('\d+',response.url)[1]
goods_data = {
'url_id': url_id,
'goods_id': goods_id,
'instructions': instructions,
}
self.insert_goods(goods_data)
数据插入
def __init__(self):
self.client = MongoClient('mongodb://localhost:27017')
self.drug = self.client.drug
def insert_goods(self,data):
collection = self.drug['goods']
collection.update({'goods_id':data['goods_id']},data,True)
- 评论部分代码分析
后面查看源码找到了商品评论部分的api,只有商品id和页码两个参数,于是就单独写了一个脚本专门爬评论,不过由于需要商品id,所以这部分工作需要上半部分完成之后才能进行
数据处理
由于爬虫的时候没有对数据进行清洗,所以先通过这个方法对一些字符处理一下
def dbmodify(self):
for data in self.collection.find({},{"goods_id":1,"goods_price":1}):
try:
_id = data['_id']
id = data['goods_id'].split(":")[1]
price = data['goods_price'].split("¥")[1]
self.collection.update({'_id': _id},{'$set':{'goods_id':id,'goods_price':price}})
print(_id, id, price)
except IndexError:
pass
获取商品ID
从数据库中取出没有被采集过评论的商品id(这里我特地设置了一个字段,用于断点续爬)
goods_list = []
for data in self.collection.find({'commspider': False}, {"url_id"}):
id = data['url_id']
goods_list.append(id)
获取商品评论信息
首先判断商品是否有品论信息,有的话再获取评论总页数,传给另外一个方法再去分页采集评论详情,并且将数据库中标记字段改为已采集
def getBaseArgument(self,goods_id):
base_url = 'https://www.111.com.cn/interfaces/review/list/html.action'
data = {
'goodsId': goods_id,
'pageIndex': 1,
'score': '1&_19020301'
}
try:
self.collection.update_one({'url_id': goods_id}, {'$set': {'commspider': True}})
requests.packages.urllib3.disable_warnings()
requests.adapters.DEFAULT_RETRIES = 5
# 设置连接活跃状态为False
s = requests.session()
s.keep_alive = False
r = s.get(base_url, params=data, timeout = 5,verify=False)
r.close()
soup = BeautifulSoup(r.text, 'html.parser')
if soup.find_all("div", class_="view_no_result"):
return "No Comments!"
else:
total_page_text = soup.find_all(text=re.compile(r'共\d+页'))[0]
pattern = re.compile(r'\d+')
total_page = pattern.findall(total_page_text)
return total_page[0]
except requests.exceptions.RequestException as e:
print(e)
分页采集评论详情
def getCommlist(self,goods_id, total_page):
base_url = 'https://www.111.com.cn/interfaces/review/list/html.action'
try:
for i in range(1, int(total_page)):
data = {
'goodsId': goods_id,
'pageIndex': i,
'score': '1&_19020301'
}
try:
requests.packages.urllib3.disable_warnings()
requests.adapters.DEFAULT_RETRIES = 15
# 设置连接活跃状态为False
s = requests.session()
s.keep_alive = False
r = s.get(base_url, params=data, timeout = 5,verify=False)
r.close()
soup = BeautifulSoup(r.text, 'html.parser')
for tr in soup.find_all("tr"):
comments = {}
try:
comments['goodsId'] = goods_id
comments['content'] = tr.find('p').text.strip()
comments['date'] = tr.find('p', attrs={'class': 'eval_date'}).text.strip()
self.comm_collection.insert_one(comments)
except:
print(goods_id + "Have some problem!\n")
print(comments)
except requests.exceptions.RequestException as e:
print(e)
except ValueError:
return "No Comments! Try next!"
爬虫小结
本项目共采集到商品数据2万条+(不排除出错),评论数据120万条+,由于本文内容较多,且各部分的阅读群体重合度不大,所以以系列文章的方式来写,关于数据分析过程以及分析结果将会在后期发布,如对另外两部分内容感兴趣的,可以关注原作者的个人公众号:Inthirty。