其实在linux上环境都一样,只要是linux上,hadoop都是一样的,唯一的且别就是依赖软件的安装。
在这里下载:http://hadoop.apache.org/releases.html 下载binary,版本的,然后将下载的文件解压,放在你想要放的位置,你可以尽量放的简单一些,这样的话以后以后写路径会简单一些。
参考的官方安装教程:http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/SingleCluster.html
1。java的安装:
yaourt jdk
选择orcle的,openjdk的话个人觉得不太靠谱:
2.ssh的安装,一般的已经安装了,这个不说。
需要说明的是,需要开启ssh的服务:http://toxicbug.blog.163.com/blog/static/126890420119139205345/
让系统启动时自动启动openssh
#systemctl enable sshd
也可手动启动openssh,执行
#systemctl start sshd
运行之后最好重启一下,然后运行:
ssh localhost
看能否连接上去。
默认情况下其它电脑是不能通过ssh来访问archlinux的,需要修改两个文件来实现:
/etc/hosts.deny #默认拒绝所有连接
/etc/hosts.allow #默认没有任何允许连接,需要手动添加,例:
#vi /etc/hosts.allow
sshd:192.168.1.×:ALLOW #允许192.168.1.0-255的访问
最后重启openssh
#systemctl restart sshd
3.至于将java路径加入hadoop-env.sh这个文件中,可以参考官方文档。
我讲一下怎么找到路径:
whereis java

然后java的路径为:/usr/lib/jvm/java-7-jdk
4。单机版的是可以直接跑起来的。
sudo ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar wordcount ./input ./output
所看的教程集合:
http://blog.csdn.net/pipisorry/article/details/51331734
http://xiaofengmo.blog.51cto.com/10116365/1744079
http://blog.csdn.net/yang_mang/article/details/52833278
http://blog.csdn.net/u014449653/article/details/54017884
http://www.cnblogs.com/qinqiao/p/local-hadoop-wordcount.html
http://www.cnblogs.com/yangmang/p/6275578.html?utm_source=itdadao&utm_medium=referral
http://hadoop.apache.org/docs/r1.0.4/cn/quickstart.html#PseudoDistributed
分布式hadoop安装
环境:三个Ubuntu 16 service虚拟机系统。由于大部分服务器端的软件都装好了,毕竟把预设的全部都选上了。。环境是没什么大问题的。
官方:http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/ClusterSetup.html
我看的教程:
http://blog.csdn.net/xiaoxiangzi222/article/details/52757168
http://www.cnblogs.com/myresearch/p/hadoop-full-distributed-operation.html
http://www.powerxing.com/install-hadoop-cluster/
(大同小异)
记录一下使用的命令,意思应该在命令中:
wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz
tar -xzvf hadoop-2.6.5.tar.gz
service ssh start #为了测试ssh服务是不是开启了,虽然测试的命令应该是下一个
service ssh status
ssh localhost #尝试连接
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa #去掉ssh链接需要的三行密码
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
whereis java #找到java的安装位置,确认自己没装的就装一下吧~
ifconfig #inet addr 为ip地址 确定每个机器的ip并且记录下来
vim ./etc/hadoop/hadoop-env.sh #修改$JAVA_HOME的路径
#以下来自:http://blog.csdn.net/xiaoxiangzi222/article/details/52757168 所有机器都要操作
sudo vim /etc/hostname #master改为master,node改为node
sudo vim /etc/hosts #将集群的ip加进去ex:192.168.94.128 master
sudo addgroup hadoop
sudo adduser -ingroup hadoop hadoop
sudo vim /etc/sudoers
scp authorized_keys hadoop@node1:~/.ssh/ #在~/.ssh文件目录下将authorized_key传到另外一个节点上,以便除去密码登陆。当然这个key应当是mater节点所生成的。
#在hadoop文件夹中新建这些文件
mkdir dfs
mkdir dfs/name
mkdir dfs/data
mkdir tmp
#请务必将java环境在集群里面的所有的电脑上安装好,并且设置好路径,并且都一致,不然运行的时候可能会忘记安装,从而导致jps命令无法找到进程
http://blog.csdn.net/xiaoxiangzi222/article/details/52757168
something useful
install vmware tool on linux
sudo mount /dev/dvd /mnt
cd /mnt
cp VM......tar.gz somewhere
cd somewhere
sudo tar -xzvf vm文件后执行pl即可。
sudo ./vmware-install.pl
#一直按enter就行。
记录一个bug
slave没有datanode进程,首先是因为java没有配好
后来配好之后还是没有datanode进程,然后在slave的机器上面查log看到:

然后查找fatal 错误后面的文字:Initialization failed for Block pool
找到: http://www.bubuko.com/infodetail-290139.html
这篇文章,然后说是datanode的clusterID 和 namenode的clusterID 不匹配,然后指出原因是因为我运行了多次的bin/hdfs namenode -format 因为slave上的是不会随着更新的,然后我果断删掉了所有机器上的dfs文件夹,然后重新运行,果然好了。我比较无语。。当然我的做法是不对的,因为我没有跑什么东西,所以可以直接删除,但是如果你跑了东西,结果会在dfs里面,所以可以按照这个方法来更改:
http://www.linuxidc.com/Linux/2014-11/108822.htm
http://ty1992.blog.51cto.com/7098269/1335144/
分布式spark安装
scala环境的安装
下载taz的包,然后解压在想要放的位置,我放在了usr/scala里面,然后再修改/etc/profile这个文件,在后面加上:
#scala
export $SCALA_HOME=/usr/scala
export PATH=${SCALA_HOME}/bin:PATH

然后
source /etc/profile这个是必须的,然后可以运行scala命令试试,当让如果你和我一样悲剧的把scala写为scale,命令会提示你要安装csound-utils,然后你会发现这个根本装不上,遇到这个情况的话,直接把所有的scale改为scala,这个原因是因为没有找到scala命令,改正确就行。
scala的环境也是所有的机器都需要安装的。
我看的spark教程: http://www.cnblogs.com/purstar/p/6293605.html
其他教程: http://blog.csdn.net/hit0803107/article/details/52795241
安装好hadoop之后,spark的安装也显得比较简单,需要注意的是:很多教程都没有说,如果你是一个普通用户的话,你的权限是不可以让集群在类似/usr的目录下运行的,所以我直接是sudo chmod -R 777 spark将文件的权限更改掉。
安装caffee arch
我看的教程:http://www.jianshu.com/p/38dc4a2dff1f
安装cuda
yaourt -S cuda
选第一个。然后等待下载完。
如果你的opencl无法下载,一直404,那么更新一下软件源:
sudo vim /etc/pacman.conf
#Server = https://cdn.repo.archlinuxcn.org/$arch #加入这行代码,去掉前面的#
sudo pacman -Syy && sudo pacman -S archlinuxcn-keyring #更新
然后再重新安装就行依旧运行yaourt cuda。
安装nvidia :yaourt -S nvidia
然后重启~
由于gpu计算是一个大坑,nvcc的编译死活没有编译成功,并不知道错误在哪里。老师也说只用cpu only的模式就行。所以上面的好像没有什么卵用。
在这里https://dl.bintray.com/boostorg/release/1.64.0/source/ 下载
~$wget https://projects.archlinux.org/svntogit/packages.git/snapshot/packages-caf64e51065d8b8b4eaba12d415432ac8bce783b.tar.gz
#Rename the file
~$mv packages-caf64e51065d8b8b4eaba12d415432ac8bce783b.tar.gz boost-1.59.tar
$tar -xf ./boost-1.59.tar
$cd boost-1.59/repos/extra-x86_64
$makepkg boost-1.59/repos/extra-x86_64
$sudo pacman -U boost-1.59.0-3-x86_64.pkg.tar.xz boost-libs-1.59.0-3-x86_64.pkg.tar.xz
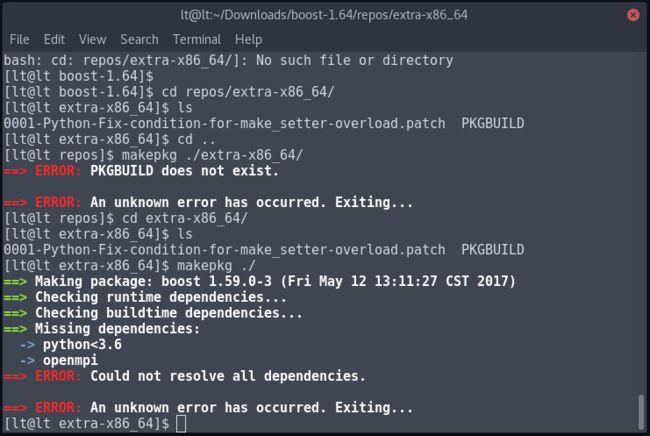
然后你会发现在makepkg的时候会缺少依赖,如下图:
然后安装openmpi
yaourt openmpi
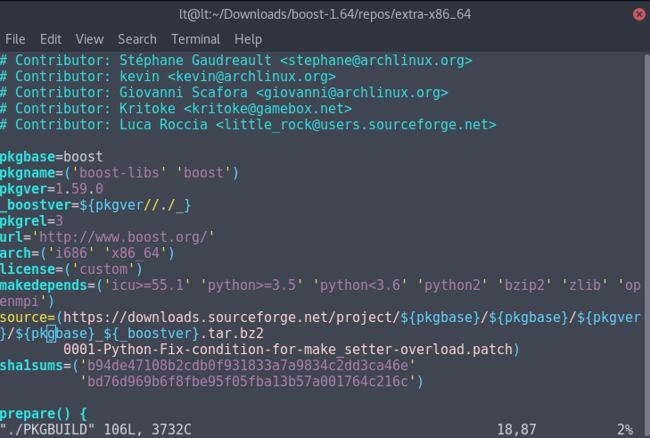
至于python的降级有点麻烦了,可以使用官网的从python3降到python3的修改文件的方式,意思是,你可以直接用yaourt python3,然后找到python3.5(至于我为什么知道是3.5的,因为pkgbuild告诉我的。如下图makedepends这一行)版本的,然后直接安装,然后更改那些文件,然系统认为python这个命令指向了python3.5
具体怎么改呢?
#找到所有的python的安装路径
[lt@lt extra-x86_64]$ whereis python
python: /usr/bin/python3.6m /usr/bin/python2.7-config /usr/bin/python3.6-config /usr/bin/python /usr/bin/python3.5m-config /usr/bin/python3.6 /usr/bin/python3.5-config /usr/bin/python3.6m-config /usr/bin/python3.5m /usr/bin/python3.5 /usr/bin/python2.7 /usr/lib/python3.6 /usr/lib/python3.5 /usr/lib/python2.7 /usr/include/python3.6m /usr/include/python3.5m /usr/include/python2.7 /usr/share/man/man1/python.1.gz
#然后根据更改python2的方式更改python3.5
然而使用python2.7也是可以的,然后你可以将python2.7改为默认的python版本,然后直接就可以用了。我更推荐这个方法。像这样:

忽略boost一切升级
sudo vim /etc/pacman.conf
找到
IgnorePkg
改成
IgnorePkg = boost boost-libs
安装 caffe
git clone https://github.com/BVLC/caffe.git
cp Makefile.config.example Makefile.config
make
多核cpu用户可以选择加多核并行编译参数,例如一个24(两颗E3 CPU)的服务器可以使用
make -j24
加速编译过程
检查会用到的测试命令:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /data/input /data/output/result
hdfs dfs -cat /data/output/result/part-r-00000
#spark
spark-shell
val file=sc.textFile("hdfs://master:9000/data/input/README.txt")
val rdd = file.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_)
rdd.collect()
rdd.foreach(println)
如果遇到了ssh localhost需要密码的话,就将/.ssh文件夹的权限改为700,/.ssh文件夹下的文件的权限改为600,然后重新试试
如果遇到安装软件的时候出现requested url returned 404,那么更新软件源仓库:pacman -Syy
xuehao:U201417268