从一张风景照中就学会的SinGAN模型,究竟是什么神操作?| ICCV 2019最佳论文

作者 | 王红成,中国海洋大学-信息科学与工程学院-计算机技术-计算机视觉方向研究生,研二在读,目前专注于生成对抗网络的研究
编辑 | Jane
出品 | AI科技大本营(ID:rgznai100)
【导读】10 月 27 日-11 月 2 日,计算机视觉领域的顶级会议 International Conference on Computer Vision(ICCV)在首尔召开,10 月 29 日在大会上正式公布了最佳论文奖(Best Paper Award)由论文《SinGAN:从单张图像学习生成模型》(SinGAN: Learning a Generative Model from a Single Natural Image)获得,该论文介绍了一种无条件生成模型——SinGAN,它可以从单个自然图像中学习。该模型经过训练,可以捕获图像内斑块的内部分布,之后生成高质量、多样化的样本,视觉内容与原图像相同。用户研究证实,生成的样本通常可以假乱真,SinGAN 在各种图像处理任务中具有广泛的实用性。

论文地址:
https://arxiv.org/abs/1905.01164
代码地址:
https://github.com/tamarott/SinGAN
文章首先通过一张简单自然图片引入这些生成不同尺度的图片,接着作者提出了利用在一张简单自然的图像上的一种新的非条件生成网络。模型主要是学习不同尺度的图像块之间的某种关系,使用特殊的多尺度对抗学习模型,可以得到更为真实的图像,它是保留原图块分布的特点,在其基础上可以生成新的目标配置和结构。接下来我们来看看文章是如何学习图像块的某种关系和它的网络结构。
方法
首先,我们先从方法入手。目标是学习到一个非条件生成对抗模型,这种模型能够捕获输入的训练数据的内部数据关系(internal statistics),在观念上,这种模型和条件GAN的设置有点像,但是,此模型的训练数据是单一图像的图像块而不是整张图像。为了不仅仅做到纹理生成还要处理更多一般的自然图像,需要一种可以在图像的不同尺度下捕获复杂图像的结构数据,类似于需要获取全局属性(大型目标的形状与排布,图像的细节与纹理信息)。
为了达到上述目的,作者提出了一种基于层级的patch-GAN模型(Markovian discriminator)。如下图所示,模型的每个部分负责输入图像的不同尺度捕获图像块分布。这种层级GAN模型感受野小和有限的功能,可以防止网络记住整图的信息。虽然类似的网络结构被应用过,但这是首次应用在一张图像的内部学习上。
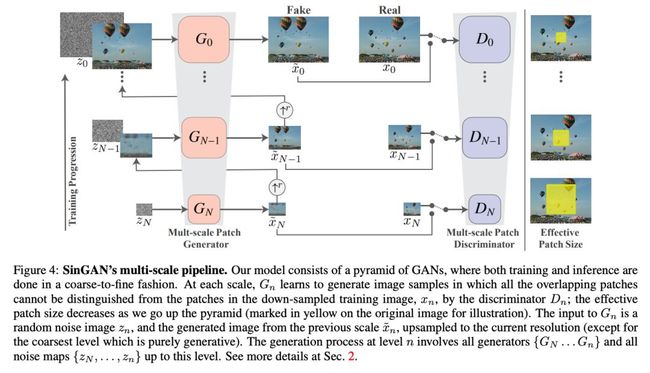
通过深入研究层次GAN的细节发现,训练过程是由下往上的(类似于金字塔,也就是文章所提到的由粗糙到精细的形式)。先由一个Z_N输入到G_N的生成器得到生成图像(这一步是单纯由噪声生成,其他生成器的输入都是由随机噪声图像z_n和上一层生成的
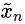 上采样到当前生成器尺寸组成),接着利用生成图像的图像块(每一层图像块的大小不一样,按照由粗糙到精细、由大到小)和当前层的图像块(由训练数据下采样得到)放入判别器中进行判断,直到两者不能被判别器区分。通过这种一层一层、由下往上的训练过程,得到最终的结果。
上采样到当前生成器尺寸组成),接着利用生成图像的图像块(每一层图像块的大小不一样,按照由粗糙到精细、由大到小)和当前层的图像块(由训练数据下采样得到)放入判别器中进行判断,直到两者不能被判别器区分。通过这种一层一层、由下往上的训练过程,得到最终的结果。
架构
模型是由金字塔形式大小的生成器
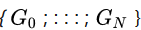 组成,训练数据
组成,训练数据
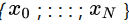 也是金字塔形式大小组成,训练数据是由一个
也是金字塔形式大小组成,训练数据是由一个
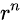 因子控制,一些r>0。根据每层
因子控制,一些r>0。根据每层
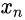 的图像块分布,相应层的生成器
的图像块分布,相应层的生成器
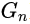 产生真实的图像实例。然后通过对抗学习,判别器
产生真实的图像实例。然后通过对抗学习,判别器
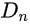 通过对生成器
通过对生成器
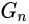 产生的图像块(生成图像的某一部分)进行判别,达到相对较好的状态(以目前来说达不到最终的纳什均衡点),最后完成训练过程。
产生的图像块(生成图像的某一部分)进行判别,达到相对较好的状态(以目前来说达不到最终的纳什均衡点),最后完成训练过程。
从刚刚的图中我们可以看到,每个尺度注入噪声后,先由粗糙的尺度开始生成图像,然后按照相应的顺序传递到相对应的生成器,最终生成精细的尺度;某一层的所有生成器和判别器有着相同的感受野,随着由下往上的生成过程,因此可以捕获尺度减小的结构信息。
再仔细地了解整个过程,在最粗糙的那个尺度下,仅将空间白噪声加入到生成器中,得到生成图像
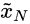 ,公式如下:
,公式如下:
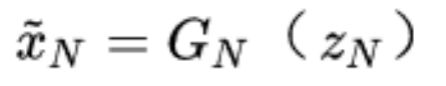
其相应的有效感受野为原始图像高度的1/2大小,于是
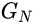 产生一般图像的布局和目标全局结构。在精细层(n
产生一般图像的布局和目标全局结构。在精细层(n
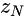 ,最终的生成图像
,最终的生成图像
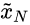 :
:
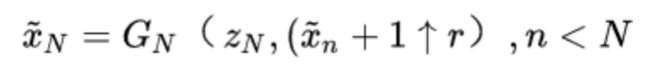
所有的生成器有着相似的结构,如下图所示:
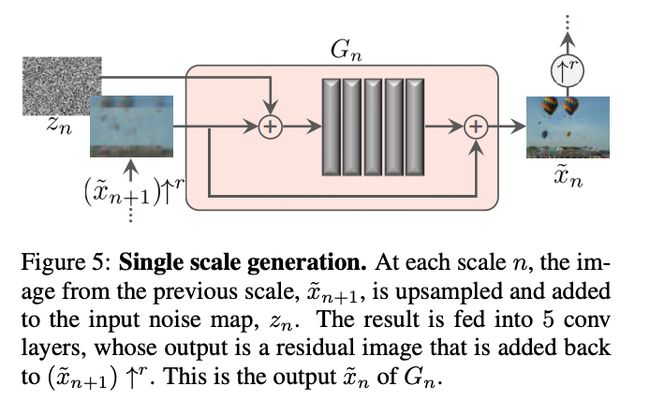
主要强调一点,噪声
加入到图像
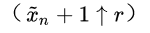 中,一起作为输入,又同时传递到卷积网络的输出
,这样保证送入到网络的噪声不会被忽略,因为之前的研究发现,当不通过这个形式训练生成器,生成器会将噪声信息给忽略,主要发生在有条件GAN中,感兴趣的话大家可以查阅相应的论文。
中,一起作为输入,又同时传递到卷积网络的输出
,这样保证送入到网络的噪声不会被忽略,因为之前的研究发现,当不通过这个形式训练生成器,生成器会将噪声信息给忽略,主要发生在有条件GAN中,感兴趣的话大家可以查阅相应的论文。
论文地址:
https://arxiv.org/abs/1703.10593
https://arxiv.org/abs/1511.05440
https://arxiv.org/abs/1711.11586
生成的图像的目标函数如下:
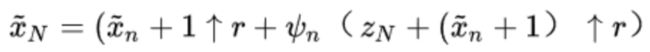
其中,
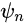 是一个全卷积网络,里面包含了5个卷积块,每个卷积块的结构由Conv(3 × 3)-BatchNorm-LeakyReLU结构组成,开始训练是在粗糙尺度上的每个卷积块,有32个卷积核,然后每4个尺度,增加2倍的卷积核。因为是全卷积网络的关系,在测试时,模型可以生成任意尺寸和比例的图像。
是一个全卷积网络,里面包含了5个卷积块,每个卷积块的结构由Conv(3 × 3)-BatchNorm-LeakyReLU结构组成,开始训练是在粗糙尺度上的每个卷积块,有32个卷积核,然后每4个尺度,增加2倍的卷积核。因为是全卷积网络的关系,在测试时,模型可以生成任意尺寸和比例的图像。
相关论文地址:
https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn.pdf
好了我们接下来聊聊它的应用吧。
Application
SinGAN在(1)Super-Resolution(超分辨率)、(2)Paint-to-Image(图画-图像转换)、(3)Harmonization(协调)、(4)Editing(编辑)、(5)Single Image Animation(单图动画)都可以用到。
在模型训练完成后,它的网络结构没有发生改变或进一步调参,并且所有的应用都是用相同的方法。所用的应用都是基于这样一个事实,即SinGAN生成的图像块(生成的图像)分布与训练的图像的图像块相同。这些操作的具体操作都是通过注入图像到某个尺度的生成金字塔中,然后将图像块和噪声(除了刚开始的粗糙层中)作为输入,生成相应的图像。只要生成的图像和训练用的图像块能够匹配就行。将图像注入到不同的尺度会得到不同的结果。
(1)Super-Resolution
通过因子s为输入的图像增加分辨率。怎么做的呢?先训练低分辨率图像,其中加入了一个重构损失,给了一个
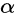 =100的权重,并且加入了金字塔尺度因子r。因为一些小结构倾向于在整个图的多个尺度反复出现,所以在测试时,作者通过因子r为低分辨率上采样,然后和噪声一起作为输入送到最后一个生成器
=100的权重,并且加入了金字塔尺度因子r。因为一些小结构倾向于在整个图的多个尺度反复出现,所以在测试时,作者通过因子r为低分辨率上采样,然后和噪声一起作为输入送到最后一个生成器
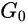 中。之后反复重复上述步骤k次,最终得到高分辨率的图像。如下图所示,由SinGAN模型得到结果在图像质量上,在internal methods方法中,取得了最好的结果。同样在external methods取得最好的结果。
中。之后反复重复上述步骤k次,最终得到高分辨率的图像。如下图所示,由SinGAN模型得到结果在图像质量上,在internal methods方法中,取得了最好的结果。同样在external methods取得最好的结果。

有趣的是,在一系列的方法比较中,SRGAN这种external method虽然在NIQE(perceptual quality)的分数微微高于SinGAN,但是看上去不如SinGAN取得的效果。
(2)Paint-to-Image
将一副剪贴画转化成一副类似真实图片的图像,怎么做的呢?如下图展示的那样,将剪贴画下采样,作为某个粗糙层(N-1,N-2)的输入。因为图像SinGAN保留画的全局结构,然后只要纹理和高频信息与原图一致,就能产生具有真实特征的图像。对比于其他几种图像风格转移的方法,就图像的质量而言,得到的结果是最好的。

(3)Harmonization
如何将一个粘贴过来的图像与背景图混合,还能得到不错的结果?先训练一张背景图,然后在测试时,注入粘贴的部分,得到最终的部分。为什么这样有用呢?因为模型把裁剪的注入目标的纹理和背景图的纹理进行匹配,在不同的尺度下,模型会在保留目标的结构和转移背景图的纹理之间取得一个好的平衡。

(4)Editing
通过对原图像部分区域的图像进行复制和粘贴的方式,对图像进行修改。和Harmonization的方法类似,通过这种方式,重新生成的纹理和无缝嵌入粘贴的部分,取得的结果要比Photoshop’s Content-Aware-Move上的结果更好。

(5)Single Image Animation
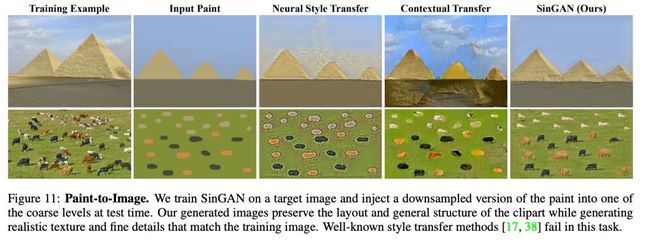
通过一张简单的图像,输出一段动画。怎么做到的呢?单一的一张图片,包含很多重复部分,在相同动态目标下的这一段时间内,揭示了不同的快照,就好像一群飞行的鸟的图像,就能揭示这只鸟的所有飞翔姿态。使用SinGAN模型,可以经历图形中所有目标表象的流形,可以通过一张简单的图像得到动态图像。作者发现,对于很多类型的图片,想要得到真实效果,要在z-space(噪声所在的空间)随机游走,以
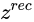 开始作为第一帧运用到所有的尺度上。
开始作为第一帧运用到所有的尺度上。
看了很多篇论文后,我总结了自己看论文的顺序,我喜欢先看完论文的方法和应用,因为我更加关注方法带来的启发和应用,又加上对这个领域有着相对的了解,对论文研究的问题已经有大概的了解,进而就便于我了解全文的情况。这里,我希望大家能找到自己的阅读习惯,大大提高学习的效率。
延伸
在我的个人阅读习惯引导下,研究完论文的方法、模型细节和应用后,再回过头来看论文Abstract、Introduction和Relation部分的内容,理解起来不仅顺畅多了,同时又能联系和引申到更多的研究工作中。
摘要中提出一个非条件的,可以通过一张简单图片学到信息的生成模型,模型可以学到一副图像上的图像块的内部分布,然后利用学到的信息,生成高质量、更多样性的样例,这些样例有着与原图相似的图像内容。SinGAN是一个包含金字塔模型的全卷积GAN模型,每一层GAN学到图像上不同尺度的图像块的分布,通过这种金字塔型的GAN网络,可以生成任意尺寸和比例的样例。这些样例有着相当大变化性,同样保留了训练图片的全局结构个精细的纹理。
是不是觉得看完摘要很熟悉的感觉?
Introduction中作者提到非条件GAN能生成更加真实、高质量的样例,但它只能被训练在特殊的数据集上,例如 faces,bedrooms上。但是,一直以来认为捕获多个目标类别的多样性数据集(ImageNet)的分布是一个主要的挑战,通常需要加上条件在输入上或者训练特殊的模型才能获取到那种分布。所以作者就提出SinGAN来应对这个挑战,成功捕获多个目标类别的具有多样性数据集的分布信息,并且不依赖于那些特殊的数据集。一直以来,构建图像块的内部分布是视觉任务、去噪声、去模糊、高分辨率、去雾和图像编辑任务最希望看到的。说明能学到图像块的内部分布,这些个问题都能不错的解决。然后作者受到一篇论文的工作的启发,可以在一个模型上解决不同的图像任务,也是SinGAN的多个不同应用。
是不是觉得读起来文章后,没有那么陌生了呢?
Related Work部分作者引入了一张图像的深度模型,是最近一些工作提出的方法,这些方法主要用在一些特殊的任务上,比如超分辨率,纹理扩充。作者对比了另外一篇论文,也是基于内部GAN网络的单图模型,但对方利用了条件GAN。相对比之下,此论文所有输入都是生成的,没有其他任何条件加入,因此可以应用到很多图像操作任务中。通常非条件GAN用来生成图像的纹理特征,当作用到非纹理的图片上,得不到有意义的实例,再与本文相比,就可以看到之间的差距了,根本不受到图像纹理的约束,对于任何自然图像都能得到不错的效果。(如下图所示)

可以看到SinGAN与单图纹理生成模型的结果对比。当运用在自然的图像上时,SinGAN包含了复杂纹理和非重复的全局结构,而另一方完全没有了全局的结构。
上面大多的内容主要是一些理论,文字的分析,还没有讲解文章的训练和结果的部分,接下来就好好看看这些结果,看作者说的对不对。
实验与结果
Training-SinGAN是一个多尺度结构的模型,按照从粗糙层到精细层这样的顺序训练模型,一旦某个GAN层训练好了,就固定它的参数。每层的GAN的loss如下所示:
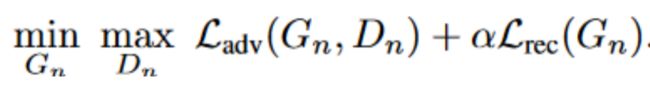
对抗损失
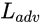 计算的是
计算的是
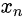 (自然图)的图像块与生成图像
(自然图)的图像块与生成图像
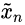 的图像块的分布的距离,它们要越近越好。
的图像块的分布的距离,它们要越近越好。
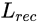 重构损失确保能产生
的一些噪声集,这个重构损失是能图像操纵的一个重要的原因。
重构损失确保能产生
的一些噪声集,这个重构损失是能图像操纵的一个重要的原因。
(1)Adversarial loss
每一层GAN的损失是WGAN-GP,衡量两个分布距离的损失。用传统的方式训练GAN会不稳定,利用WGAN-GP可以使训练更加稳定,最终的判别分数是由图像块判别图平均得来的。与单图应用与纹理GAN模型不同的是,作者计算的损失是全图的,并不是随机块的 。这种方式能让模型学习到边界位置信息,这个信息是很重要的一个特征。判别器
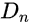 的架构与
的架构与
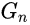 中的全卷积网络
中的全卷积网络
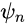 一样。判别器的
一样。判别器的
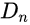 的图像块的尺寸(模型的感受野)为11x11。
的图像块的尺寸(模型的感受野)为11x11。
(2)Reconstruction loss
为了确定特殊的产生在粗糙层的第一张图x的噪声图集合,作者特别的选择了一个集合
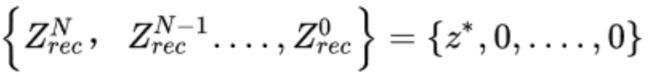
其中
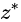 是一些固定的噪声图(除了使用过程,其它训练的时候保持固定)。当使用这些噪声图时,
是一些固定的噪声图(除了使用过程,其它训练的时候保持固定)。当使用这些噪声图时,
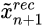 表示为在第n层生成的图像。且n
表示为在第n层生成的图像。且n
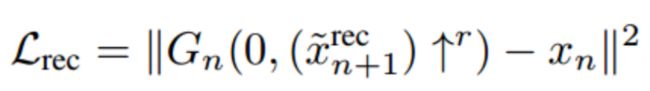
其中当n=N时,重构损失记为:
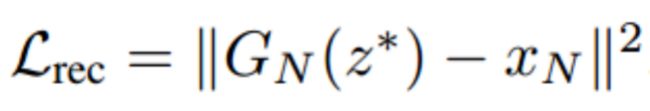
在训练时,第n层生成的图像
还有着另外一个角色,即决定每个尺度下噪声
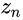 的标准偏差
的标准偏差
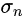 ,特别地,将
正比于
,特别地,将
正比于
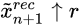 与
与
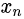 的均方根差(root mean squared error),意味着有多少图像的细节需要添加到当前尺度下。
的均方根差(root mean squared error),意味着有多少图像的细节需要添加到当前尺度下。
其实我个人认为在GAN这个方向上,对损失函数的设计也是很重要的,如果设计的不合理,损失不能收敛,不管方法多么优秀也不能得到希望的结果。
实验部分作者分别采取了定性与定量两方面来评估模型的好坏。先看定量分析,图像有着新的真实结构和目标构造,也保存了训练图像的内容信息,取得了不错的效果,模型成功地保存了全局目标结构,比如下图中的热气球和金字塔。同样,还有精细的纹理信息,因为网络有限的感受野,使得网络生成了一些图像块的新连接,这些连接根本不存在于原图中,但进一步的观察发现,很多图片的反射和阴影都生成的很真实。

作者指出,因为SinGAN的架构与分辨率无关,所以还可以使用高分辨率的图像进行训练。可以看到生成的图像结果很真实,结果惊人。

作者分别测试了训练过程和测试过程中尺度的影响,得出这样的结论。测试时,从粗糙层开始,n=N,斑马全局结构发生了巨大的变化;当从精细层开始,能保持住全局的结构信息,只改变了部分精细的图片特征,比如斑马的斑纹。

训练时,在小尺度下,粗糙层的有效感受野很小,有助于捕获精细的纹理信息,随着尺度增加,结构信息和全局的布置都保存的很好。
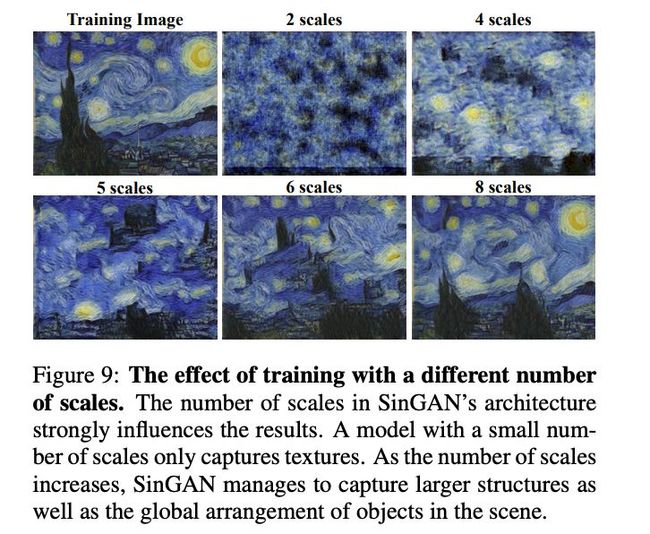
再看定量分析,分别用 (1) Amazon Mechanical Turk (AMT) perceptual study 和 (2) a new single-image version of the Fr ́echet Inception Distance (和以前用到的FID距离作了改变)。在不成对的图像对上,分不清楚的结果占比明显较大,也有进一步说明,困惑率与生成多样性图像有关;当图像的结构发生巨大的变化时,真实图像和生成的图像很难辨识。
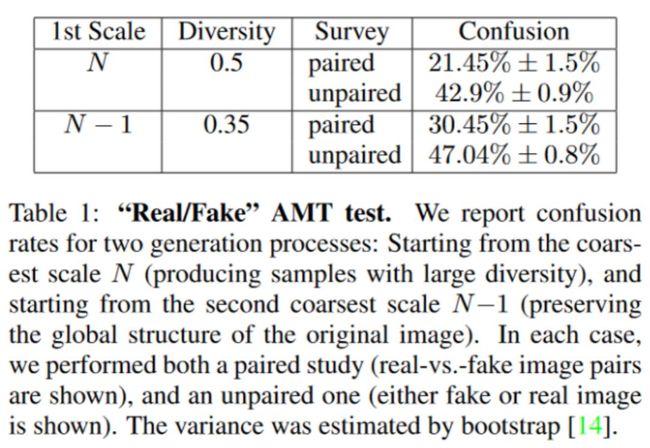
table 2的结果显示,随着尺度的增加(由下往上),SIFID是变小的,说明越往上,越逼真;同样作者记录了SIFID与AMT两者的相关性,发现两者有着强相关性,FIFID分数越小,困惑越大,这表明两者都是为了得到最好的结果而共同协作的。
结语
文章提出了一种新型的非条件生成模型SinGAN,此模型的学习对象就是一张简单的自然图像。通过对这篇论文的学习发现,模型可以学到很好的纹理信息,得到更加真实、难以区分的图像。但这个模型也不是十分完美的,它应用的场景主要针对内部学习,受限于语义。比如,当给出一张狗的图像,你得不到完全没有见过的新狗,只能得到更清晰的狗,或者其他样子的相同的狗,反正和目标图像的不同之处不是很突出。
(*本文为AI科技大本营投稿文章,转载请微信联系 1092722531)
◆
精彩推荐
◆
2019 中国大数据技术大会(BDTC)再度来袭!豪华主席阵容及百位技术专家齐聚,15 场精选专题技术和行业论坛,超强干货+技术剖析+行业实践立体解读,深入解析热门技术在行业中的实践落地。
6.6 折票限时特惠(立减1400元),学生票仅 599 元!
