数据聚合与分组运算
对数据集进行分组并对各组应用一个函数(无论是聚合还是转换),这是数据分析工作中的重要环节。在将数据集准备好之后,通常的任务就是计算分组统计或生成透视表
在本章中,你将会学到:
- 根据一个或多个键(可以是函数、数组或DataFrame列名)拆分pandas对象。
- 计算分组摘要统计,如计数、平均值、标准差,或用户自定义函数。
- 对DataFrame的列应用各种各样的函数。
- 应用组内转换或其他运算,如规格化、线性回归、排名或选取子集等。
- 计算透视表或交叉表。
- 执行分位数分析以及其他分组分析。
分组运算的第一个阶段,pandas对象(无论是Series、DataFrame还是其他的)中的数据会根据你所提供的一个或多个键被拆分(split)为多组。拆分操作是在对象的特定轴上执行的。例如,DataFrame可以在其行(axis=0)或列(axis=1)上进行分组。然后,将一个函数应用(apply)到各个分组并产生一个新值。最后,所有这些函数的执行结果会被合并(combine)到最终的结果对象中。结果对象的形式一般取决于数据上所执行的操作。图9-1大致说明了一个简单的分组聚合过程。

GroupBy技术
分组键可以有多种形式,且类型不必相同:
列表或数组,其长度与待分组的轴一样。
表示DataFrame某个列名的值。
字典或Series,给出待分组轴上的值与分组名之间的对应关系。
函数,用于处理轴索引或索引中的各个标签。
from pandas import Series,DataFrame
import pandas as pd
import numpy as np
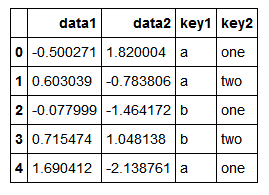
df=DataFrame({'key1':['a','a','b','b','a'],'key2':['one','two','one','two','one'],
'data1':np.random.randn(5),'data2':np.random.randn(5)})
df
按key1进行分组,并计算data1列的平均值。可以通过访问data1,并根据key1调用groupby
grouped=df['data1'].groupby(df['key1'])
grouped
变量grouped是一个GroupBy对象,接下来调用GroupBy的mean方法来计算分组平均值
grouped.mean()
key1
a 0.597727
b 0.318738
Name: data1, dtype: float64
如果一次传入多个数组,会得到不同的结果
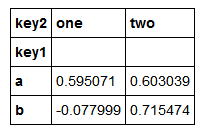
means=df['data1'].groupby([df['key1'],df['key2']]).mean()
means
key1 key2
a one 0.595071
two 0.603039
b one -0.077999
two 0.715474
Name: data1, dtype: float64
上面通过两个键对数据进行了分组,得到的Series具有一个层次化索引(由唯一的键对组成),下面进行调换
means.unstack()
以上的例子中分组键都是Series。其实,分组键可以是任何长度适当的数组
states=np.array(['Ohio','California','California','Ohio','Ohio'])
years=np.array([2005,2005,2006,2005,2006])
states
array(['Ohio', 'California', 'California', 'Ohio', 'Ohio'],
dtype='years
array([2005, 2005, 2006, 2005, 2006])
df['data1'].groupby([states,years]).mean()
California 2005 0.603039
2006 -0.077999
Ohio 2005 0.107602
2006 1.690412
Name: data1, dtype: float64
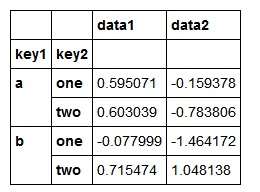
可以使用列名的字符串、数字或其他Python对象用作分组键
df.groupby('key1').mean()

df.groupby(['key1','key2']).mean()
groupby的size方法,可以返回一个含有分组大小的Series
df.groupby(['key1','key2']).size()
key1 key2
a one 2
two 1
b one 1
two 1
dtype: int64
对分组进行迭代
groupby对象可以产生一组二元元组(由分组名和数据块组成)
for name,group in df.groupby('key1'):
print(name)
print(group)
a
data1 data2 key1 key2
0 -0.500271 1.820004 a one
1 0.603039 -0.783806 a two
4 1.690412 -2.138761 a one
b
data1 data2 key1 key2
2 -0.077999 -1.464172 b one
3 0.715474 1.048138 b two
对于多重键的情况,元组的第一个元素将会是由键值组成的元组
for (k1,k2),group in df.groupby(['key1','key2']):
print(k1,k2)
print(group)
a one
data1 data2 key1 key2
0 -0.500271 1.820004 a one
4 1.690412 -2.138761 a one
a two
data1 data2 key1 key2
1 0.603039 -0.783806 a two
b one
data1 data2 key1 key2
2 -0.077999 -1.464172 b one
b two
data1 data2 key1 key2
3 0.715474 1.048138 b two
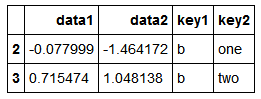
将这些数据片段做成一个字典
pieces=dict(list(df.groupby('key1')))
pieces
{'a': data1 data2 key1 key2
0 -0.500271 1.820004 a one
1 0.603039 -0.783806 a two
4 1.690412 -2.138761 a one, 'b': data1 data2 key1 key2
2 -0.077999 -1.464172 b one
3 0.715474 1.048138 b two}
pieces['b']
groupby默认是在axis=0上进行分组的,下面根据dtype对列进行分组
df.dtypes
data1 float64
data2 float64
key1 object
key2 object
dtype: object
grouped=df.groupby(df.dtypes,axis=1)
dict(list(grouped))
{dtype('float64'): data1 data2
0 -0.500271 1.820004
1 0.603039 -0.783806
2 -0.077999 -1.464172
3 0.715474 1.048138
4 1.690412 -2.138761, dtype('O'): key1 key2
0 a one
1 a two
2 b one
3 b two
4 a one}
选取一个或一组列
对于由DataFrame产生的GroupBy对象,如果用一个(单个字符串)或一组(字符串数组)列名对其进行索引,就能实现选取部分列进行聚合的目的
df.groupby('key1')['data1']
df['data1'].groupby(df['key1'])
对于大数据集,很可能只需要对部分列进行聚合。例如,在前面那个数据集中,如果只需计算data2列的平均值并以DataFrame形式得到结果,我们可以编写
df.groupby(['key1','key2'])[['data2']].mean()
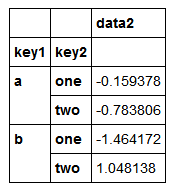
这种索引操作所返回的对象是一个已分组的DataFrame(如果传入的是列表或数组)或已分组的Series(如果传入的是标量形式的单个列名)
s_grouped=df.groupby(['key1','key2'])['data2']
s_grouped
s_grouped.mean()
key1 key2
a one -0.159378
two -0.783806
b one -1.464172
two 1.048138
Name: data2, dtype: float64
通过字典或Series进行分组
除数组以外,分组信息还可以其他形式存在,实例:DataFrame
people=DataFrame(np.random.randn(5,5),columns=['a','b','c','d','e'],
index=['Joe','Steve','Wes','Jim','Travis'])
people.loc[2:3,['b','c']]=np.nan #添加NA值
people
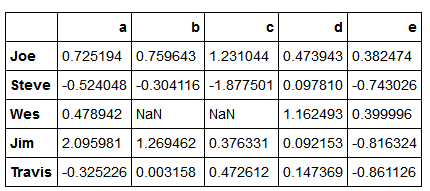
假设已知列的分组关系,并希望根据分组计算列的总计,首先把这个字典传给groupby
mapping={'a':'red','b':'red','c':'blue','d':'blue','e':'red','f':'orange'}
by_column=people.groupby(mapping,axis=1)
by_column.sum()
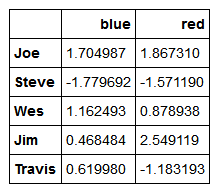
Series也有同样的功能,它可以被看做一个固定大小的映射。这个例子,如果用Series作为分组键,则pandas会检查Series以确保其索引跟分组轴是对齐的
map_series=Series(mapping)
map_series
a red
b red
c blue
d blue
e red
f orange
dtype: object
people.groupby(map_series,axis=1).count()
| blue | red | |
|---|---|---|
| Joe | 2 | 3 |
| Steve | 2 | 3 |
| Wes | 1 | 2 |
| Jim | 2 | 3 |
| Travis | 2 | 3 |
通过函数进行分组
任何被当做分组键的函数都会在各个索引值上被调用一次,其返回值就会被用作分组名称。
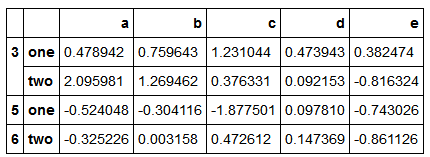
具体点说,以上的示例DataFrame为例,其索引值为人的名字。假设你希望根据人名的长度进行分组,虽然可以求取一个字符串长度数组,但其实仅仅传入len函数
people.groupby(len).sum()
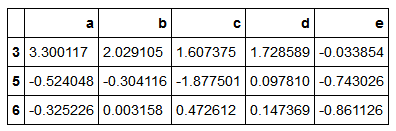
将函数跟数组、列表、字典、Series混合使用可以,因为任何东西最终都会被转换为数组
key_list=['one','one','one','two','two']
people.groupby([len,key_list]).min()
根据索引级别分组
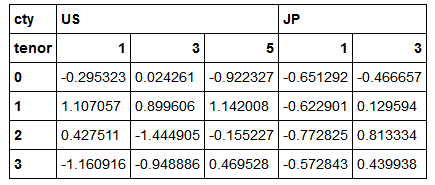
层次化索引数据集最方便的地方就在于它能够根据索引级别进行聚合。通过level关键字传入级别编号或名称
columns=pd.MultiIndex.from_arrays([['US','US','US','JP','JP'],
[1,3,5,1,3]],names=['cty','tenor'])
hier_df=DataFrame(np.random.randn(4,5),columns=columns)
hier_df
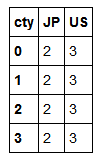
hier_df.groupby(level='cty',axis=1).count()
数据聚合
对于聚合,指的是任何能够从数组产生标量值的数据转换过程。
使用自己发明的聚合运算,还可以调用分组对象上已经定义好的任何方法。
例如,quantile可以计算Series或DataFrame列的样本分位数
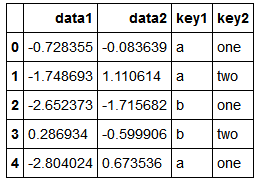
df=DataFrame({'key1':['a','a','b','b','a'],'key2':['one','two','one','two','one'],
'data1':np.random.randn(5),'data2':np.random.randn(5)})
df
grouped=df.groupby('key1')
grouped['data1'].quantile(0.9)
key1
a -0.932423
b -0.006997
Name: data1, dtype: float64
如果要使用你自己的聚合函数,只需将其传入aggregate或agg方法
def peak_to_peak(arr):
return arr.max()-arr.min()
grouped.agg(peak_to_peak)
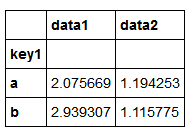
describe也可以使用,即使严格来讲,它们并非聚合运算
grouped.describe()
data1 data2
key1
a count 3.000000 3.000000
mean 0.746672 0.910916
std 1.109736 0.712217
min -0.204708 0.092908
25% 0.137118 0.669671
50% 0.478943 1.246435
75% 1.222362 1.319920
max 1.965781 1.393406
b count 2.000000 2.000000
mean -0.537585 0.525384
std 0.025662 0.344556
min -0.555730 0.281746
25% -0.546657 0.403565
50% -0.537585 0.525384
75% -0.528512 0.647203
max -0.519439 0.769023
注意:自定义聚合函数要比表9-1中那些经过优化的函数慢得多。这是因为在构造中间分组数据块时存在非常大的开销(函数调用、数据重排等)

为了说明一些更高级的聚合功能,将使用一个有关餐馆小费的数据集(在本书的GitHub库中)https://github.com/wesm/pydata-book/tree/1st-edition
通过read_csv加载之后,添加一个表示小费比例的列tip_pct
tips=pd.read_csv('pydata_book/ch08/tips.csv') #加载数据
tips[:8] #选取前8个数据集
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
5 25.29 4.71 Male No Sun Dinner 4
6 8.77 2.00 Male No Sun Dinner 2
7 26.88 3.12 Male No Sun Dinner 4
tips['tip_pct']=tips['tip']/tips['total_bill'] #添加“小费占总额百分比”的列
tips[:8]
total_bill tip sex smoker day time size tip_pct
0 16.99 1.01 Female No Sun Dinner 2 0.059447
1 10.34 1.66 Male No Sun Dinner 3 0.160542
2 21.01 3.50 Male No Sun Dinner 3 0.166587
3 23.68 3.31 Male No Sun Dinner 2 0.139780
4 24.59 3.61 Female No Sun Dinner 4 0.146808
5 25.29 4.71 Male No Sun Dinner 4 0.186240
6 8.77 2.00 Male No Sun Dinner 2 0.228050
7 26.88 3.12 Male No Sun Dinner 4 0.116071
面向列的多函数应用
我们已经看到,对Series或DataFrame列的聚合运算其实就是使用aggregate(使用自定义函数)或调用诸如mean、std之类的方法。然而,你可能希望对不同的列使用不同的聚合函数,或一次应用多个函数。
下面将练习各种实例
grouped=tips.groupby(['sex','smoker'])#根据sex和smoker对tips进行分组
grouped_pct=grouped['tip_pct'] #将函数名以字符串的形式传入
grouped_pct.agg('mean')
sex smoker
Female No 0.156921
Yes 0.182150
Male No 0.160669
Yes 0.152771
Name: tip_pct, dtype: float64
传入一组函数或函数名,得到的DataFrame的列就会以相应的函数命名
grouped_pct.agg(['mean','std',peak_to_peak])
mean std peak_to_peak
sex smoker
Female No 0.156921 0.036421 0.195876
Yes 0.182150 0.071595 0.360233
Male No 0.160669 0.041849 0.220186
Yes 0.152771 0.090588 0.674707
如果传入的是一个由(name,function)元组组成的列表,则各元组的第一个元素就会被用作DataFrame的列名(可以将这种二元元组列表看做一个有序映射)
grouped_pct.agg([('foo','mean'),('bar',np.std)])
foo bar
sex smoker
Female No 0.156921 0.036421
Yes 0.182150 0.071595
Male No 0.160669 0.041849
Yes 0.152771 0.090588
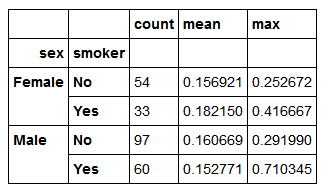
对于DataFram,定义一组应用于全部列的函数,或不同的列应用不同的函数。假设我们想要对tip_pct和total_bill列计算三个统计信息
functions=['count','mean','max']
result=grouped['tip_pct','total_bill'].agg(functions)
result

结果DataFrame拥有层次化的列,这相当于分别对各列进行聚合,然后用concat将结果组装到一起(列名用作keys参数)
result['tip_pct']
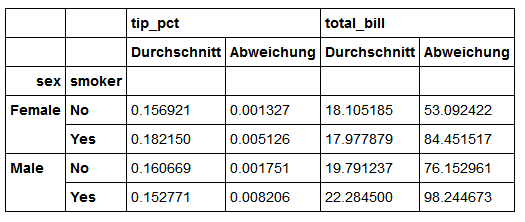
传入带有自定义名称的元组列表
ftuples=[('Durchschnitt','mean'),('Abweichung',np.var)]
grouped['tip_pct','total_bill'].agg(ftuples)
如果想要对不同的列应用不同的函数。具体的办法是向agg传入一个从列名映射到函数的字典
grouped.agg({'tip':np.max,'size':'sum'})
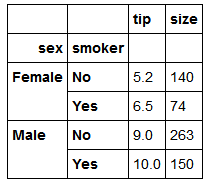
grouped.agg({'tip_pct':['min','max','mean','std'],'size':'sum'})

只有将多个函数应用到至少一列时,DataFrame才会拥有层次化的列。
以“无索引”的形式返回聚合数据
示例中的聚合数据都有由唯一的分组键组成的索引(可能还是层次化的)。由于并不总是需要如此,可以向groupby传入as_index=False以禁用该功能
对结果调用reset_index也能得到这种形式的结果
tips.groupby(['sex','smoker'],as_index=False).mean()

下一节学习分组级运算和转换。