Valse2018参会小结——生成对抗网络系列
目录
1 引言
2 面向人脸的生成对抗网络
2.1基于GAN的人脸生成及修复
2.2基于生成对抗网络的超分辨率重建
2.3基于生成对抗网络的人脸配准
2.4基于条件生成对抗网络的图像迁移—人脸属性
3 面向行人的生成对抗网络
3.1 基于GAN的行人检测
3.2 基于感知生成对抗网络PGAN的行人再识别
3.3 人体解析—人体姿态估计
3.4 基于不同ReID数据集的行人图片迁移PTGAN
4 面向医学影像的生成对抗网络
4.1 医学图像分割
4.2 医学图像分类
4.3 医学图像重构
4.4 医学图像识别
1 引言
近年来,深度学习在计算机视觉、自然语言处理等诸多应用领域中取得突破性进展。现有的深度学习的模型可大致分为卷积神经网络(Convolutional Neural Networks, CNNs)、循环神经网络(Recurrent Neural Networks, RNNs)、和生成对抗网络(Generative Adversarial Nets, GANs)等。现有深度学习方法对真实世界进行建模需要大量先验知识,而建模的好坏直接影响生成模型的性能。鉴于此问题,Goodfellow 所提出生成对抗网络GAN逐步受到广大学者和专家们的关注。GAN由生成网络和对抗网络组成,采用对抗训练机制进行训练,并使用优化器(如随机梯度下降(SGD,stochastic gradient descent),自适应时刻估计方法(Adam,Adaptive Moment Estimation)等)实现优化,二者交替训练,直到达到纳什均衡后停止训练。目前,GAN已成功应用于图像生成、图像分类、图像分割、图像理解,图像超分辨率等领域,同样,深度学习和增强学习的交叉应用不容忽视,诸多研究工作表明GAN能够与强化学习很好的结合。在应用落地方面,Google、Facebook和 Twitter 等知名人工智能企业纷纷投入大量精力研究和拓展GAN的应用。
本文首先介绍GAN在面向人脸、行人、医学影像等方面的最新研究进展,然后分析与总结GAN在建模、训练策略选择等方面值得借鉴之处,最后指出生成式对抗网络研究中亟待解决的问题。
2 面向人脸的生成对抗网络
在监控视频、移动多媒体应用等领域,人脸对象作为重要的研究对象,具有重要的研究意义。现有的面向人脸的技术主要分为预处理与后处理两个大的方向。其中人脸预处理包括人脸检测、人脸配准、人脸修复等方向,人脸后处理则包括人脸超分辨率重建、人脸属性转换、人脸美化、人脸识别等方向。下面将对这几类算法进行详细介绍。
2.1 基于GAN的人脸生成及修复
图像修复任务主要基于图像中已有信息,去还原图像中的缺失部分。传统算法主要采用图像块匹配(PatchMatch),从已给数据集中搜寻相似图片块(Patch)来进行图像补全和合成残缺图片,这类算法计算速度慢且效果较差。相比于这种方法,深度学习的方法采用“先验知识+CNN”的策略合成图像残缺部分的内容。为了解决图像修复问题,基于生成对抗网络的方法相继被提出,其中,CVPR 2017文献[1]最具有代表性,该方法的整体结构如下图所示,整个模型主要由三个模块构成:一个生成器(G,Generator),两个鉴别器(D,Discriminator),一个语义解析网络(SP,Semantic Parsing network),三个模块的损失函数分别对应于重建损失(a reconstruction loss)、对抗损失(global and local adversarial losses)、感知稀疏损失(a semantic parsing loss)。
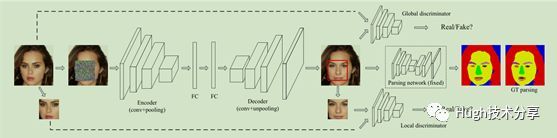
生成器G:采用一个VGG-19 的自动编码器得到人脸重建图像。该网络的编码层结构encoder与解码层decoder结构相对称,其优势在于:1)自动编码器的特征提取能力较强,2)残缺图片通过编码层encoder映射成隐藏特征,得到很好的隐式表达,3)编码器的使用能够避免图像重建过程中噪声的干扰。但是生成器生成的图像往往会非常模糊,仅获得粗略的人脸轮廓。
判别器D:为了解决以上问题,算法采用两个判别器(local discriminator和global discriminator)对生成图片的细节进行完善,使得生成的图片更加真实。其优势在于,局部判别器能够让生成器生成图片中补全的部分更加真实,而整体判别器则使得整个生成的图片看起来更加真实。但是,以上生成器与判别器的组合方式仍存在局限性,例如生成图像不包含人脸图像正确属性。
语义解析网络SP:受文献[2]启发,算法采用语义解析网络改进上述生成对抗网络生成的图片,其生成的人脸图像具有更加自然的形态。
2.2 基于生成对抗网络的超分辨率重建
受多种因素影响,视频监控中得到的人脸图像往往含有模糊、噪声、低分辨率、压缩失真等降质因素。大多数基于卷积神经网络的方法仅对正面人脸图像进行超分辨率重建,当面对不同姿态的低分辨率图像时,这些方法重建人脸图像的质量较大,呈现姿态不可控的现象。为了解决人脸姿态可控的问题,哈工大左旺孟老师提出一种指导人脸重建的网络(GFRNet, guided facerestoration network)。该方法的整体结构如下图所示,整个模型主要由两个模块构成:一个图像扭曲网络(WarpNet, warpingsubnetwork) 和一个重建网络(RecNet,reconstruction subnetwork)。
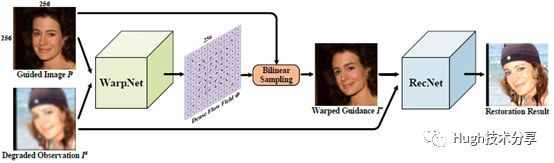
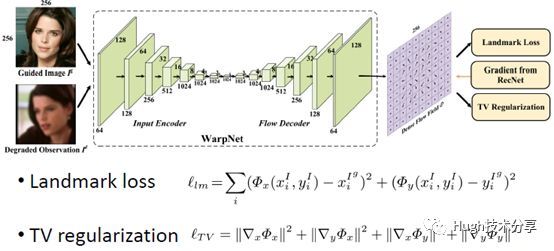
图像扭曲网络WarpNet:主要用于指导生成图像,使重建图像具有合适的姿态与表情。WarpNet具有encoder-decoder的网络结构,如下图所示,它还整合了landmark loss和TV regularizer。它的优势在于算法可以进行可控姿态下的人脸重建。
下图第一列是待处理图像,第二列是指导图像,通过观察可以看出,与传统的CNN方法(第三、四列)相比,GFRNet(最后一列)能够更好地重建人脸图像。

2.3 基于生成对抗网络的人脸配准
在人脸识别任务中,非正面人脸识别的性能较低,如何根据侧面照片合成正面人脸一直是个难题。为了解决人脸配准、人脸合成的问题,中科院自动化所(CASIA)提出了双路径GAN(TP-GAN,Two Path GAN)[3],该方法综合考虑了人脸整体和局部信息的整合,通过单一侧面照片合成正面人脸图像,取得了较好的结果。TP-GAN的结构示意图如下图所示,主要包括生成网络,判别网络和人脸识别网络。
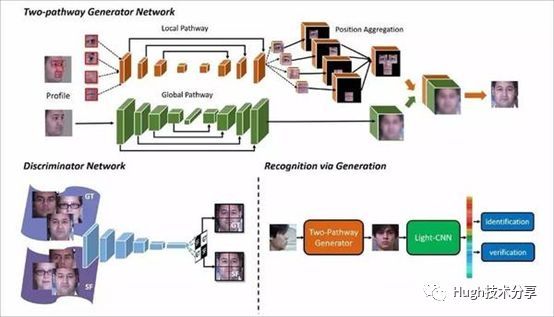
生成器包含两个路径,分别处理人脸全局信息及局部变换信息,通过融合特征图得到合成图像;而判别器则用于合成正面人脸与真实人脸图像;最后由人脸识别网络对生成图像进行人脸验证。
该方法的创新在于:它将从数据分布(对抗训练)得来的先验知识和人脸领域知识(对称性、身份保留损失)结合起来,将对抗性损失(adversarial loss)、对称性损失(symmetry loss)和身份保留损失(identity preserving loss)组合。这一损失的组合能够利用正面脸部的分布和预训练识别深度脸部模型(pre-trained discriminative deep face models),以此指导身份保留推理从正面脸部视图合成侧面照。如下图所示,TP-GAN能够将人脸图像的面部特征保留,包括胡须、眼镜,且将人脸遮挡的前额和脸颊部分恢复。

2.4 基于条件生成对抗网络的图像迁移—人脸属性
人脸图像含有多种属性信息,包括年龄、性别、微笑程度、情绪、颜值、视线、嘴部状态、头部姿态、眼睛状态、皮肤状态、人种等。在人脸属性编辑任务中,传统生成对抗网络的方法为了实现在k个不同的风格域上进行迁移,需要构建k∗(k−1)个生成器,人脸属性编辑更加精确,但多模型会造成图像编辑慢的问题。为了解决此问题,文献[4]提出一种属性生成对抗网络(AttGAN,Attribute GAN),AttGAN的结构示意图如下图所示,主要包括生成网络G,判别网络D。在算法实现过程中,该方法采用单组的生成器G和判别器D学习人脸图像在多个不同属性域中的转换。
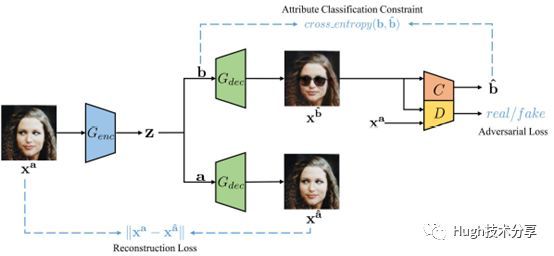
生成网络G:包含一个编码器和两个解码器。其中,两个解码器分别完成原图属性、目标属性人脸图像的重建;这样的网络有利于多属性人脸图像重新组合。
判别网络D:包括一个判别器和分类器。通过一个判别器决策重建图像真伪,通过属性约束网络调优属性生成的准确性。
如下图所示,该方法可实现多属性人脸图像的编辑,并且效果较好。

以上方法从图像生成、图像修补、超分辨率重建、人脸图像配准、人脸属性编辑等方法深入探索了生成对抗网络潜在的优势,为广大学者带来启示。
参考文献
[1]LiY, Liu S, Yang J, et al. Generative Face Completion[J]. 2017.https://github.com/Yijunmaverick/GenerativeFaceCompletion
[2]Yang,Jimei, et al. "Object contour detection with a fully convolutionalencoder-decoder network." Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition. 2016.
[3]Huang R, Zhang S,Li T, et al. Beyond Face Rotation: Global and Local Perception GAN forPhotorealistic and Identity Preserving Frontal View Synthesis[J].2017:2458-2467.
[4] Z.He, W. Zuo, M. Kan, S. Shan, X. Chen, Arbitrary Facial Attribute Editing: OnlyChange What You Want, arXiv:1711.10678, 2017.