首先,结论是主线程确实阻塞了,但是主线程在初始化过程中由ActivityThread的main()方法中会创建一套消息循环组件包括Looper,MessageQueue,Handler,然后由MessageQueue中的next()调用底层MessageQueue,通过epoll进行阻塞,有主线程消息的时候通过发送消息激活主线程.
Looper 中的 loop() 方法是如何实现阻塞的呢?
大家有没有想过一个问题啊,就是loop是一个循环,不停的去轮询消息池,如果消息池为空呢,它还会工作吗?如果消息池为空就不会轮询了,就阻塞了,如果突然来了消息呢,怎么就又开始工作了呢(哈哈,这好像是个面试题)
好吧,让我们看看到底怎么处理这个问题的,其实关键就在心系两界的MessageQueue
MessageQueue(boolean quitAllowed) {
mQuitAllowed = quitAllowed;
nativeInit();
}
它通过转调 native 方法 nativeInit() 实现的,后者是定义在 android_os_MessageQueue.cpp 中:
static voidandroid_os_MessageQueue_nativeInit(JNIEnv* env, jobject obj) {
// NativeMessageQueue是MessageQueue在Native层的代表
NativeMessageQueue* nativeMessageQueue = newNativeMessageQueue();
......
// 将这个NativeMessageQueue对象设置到Java层保存
android_os_MessageQueue_setNativeMessageQueue(env,obj,nativeMessageQueue);
}
nativeInit函数在Native层创建了一个与MessageQueue对应的NativeMessageQueue对象,其构造函数如下:
[android_os_MessageQueue.cpp–>NativeMessageQueue::NativeMessageQueue()]
NativeMessageQueue::NativeMessageQueue() {
/* 代表消息循环的Looper也在Native层中呈现身影了。根据消息驱动的知识,一个线程会有一个
Looper来循环处理消息队列中的消息。下面一行的调用就是取得保存在线程本地存储空间
(Thread Local Storage)中的Looper对象 */
mLooper= Looper::getForThread();
if (mLooper == NULL) {
/* 如为第一次进来,则该线程没有设置本地存储,所以须先创建一个Looper,然后再将其保存到
TLS中,这是很常见的一种以线程为单位的单例模式*/
mLooper = new Looper(false);
Looper::setForThread(mLooper);
}
}
Native的Looper是Native世界中参与消息循环的一位重要角色。虽然它的类名和Java层的Looper类一样,但此二者其实并无任何关系。这一点以后还将详细分析。
提取消息
当一切准备就绪后,Java层的消息循环处理,也就是Looper会在一个循环中提取并处理消息。消息的提取就是调用MessageQueue的next()方法。当消息队列为空时,next就会阻塞。MessageQueue同时支持Java层和Native层的事件,那么其next()方法该怎么实现呢?具体代码如下:
final Message next() {
int pendingIdleHandlerCount = -1;
int nextPollTimeoutMillis = 0;
for (;;) {
......
// mPtr保存了NativeMessageQueue的指针,调用nativePollOnce进行等待
nativePollOnce(mPtr,nextPollTimeoutMillis);
synchronized (this) {
final long now = SystemClock.uptimeMillis();
// mMessages用来存储消息,这里从其中取一个消息进行处理
final Message msg = mMessages;
if (msg != null) {
final long when = msg.when;
if (now >= when) {
mBlocked = false;
mMessages = msg.next;
msg.next = null;
msg.markInUse();
return msg; // 返回一个Message给Looper进行派发和处理
} else {
nextPollTimeoutMillis = (int) Math.min(when- now,Integer.MAX_VALUE);
}
} else {
nextPollTimeoutMillis = -1;
}
......
/* 处理注册的IdleHandler,当MessageQueue中没有Message时,
Looper会调用IdleHandler做一些工作,例如做垃圾回收等 */
......
pendingIdleHandlerCount = 0;
nextPollTimeoutMillis = 0;
}
}
}
看到这里,可能会有人觉得这个MessageQueue很简单,不就是从以前在Java层的wait变成现在Native层的wait了吗?但是事情本质比表象要复杂得多,来思考下面的情况:
nativePollOnce()返回后,next()方法将从mMessages中提取一个消息。也就是说,要让nativePollOnce()返回,至少要添加一个消息到消息队列,否则nativePollOnce()不过是做了一次无用功罢了。
如果nativePollOnce()将在Native层等待,就表明Native层也可以投递Message,但是从Message类的实现代码上看,该类和Native层没有建立任何关系。那么nativePollOnce()在等待什么呢?
对于上面的问题,相信有些读者心中已有了答案:nativePollOnce()不仅在等待Java层来的Message,实际上还在Native还做了大量的工作。
下面我们来分析Java层投递Message并触发nativePollOnce工作的正常流程。
在Java层投递Message
MessageQueue的enqueueMessage函数完成将一个Message投递到MessageQueue中的工作,其代码如下:
final boolean enqueueMessage(Message msg, longwhen) {
......
finalboolean needWake;
synchronized (this) {
if(mQuiting) {
return false;
}else if (msg.target == null) {
mQuiting = true;
}
msg.when = when;
Message p = mMessages;
if(p == null || when == 0 || when < p.when) {
/* 如果p为空,表明消息队列中没有消息,那么msg将是第一个消息,needWake
需要根据mBlocked的情况考虑是否触发 */
msg.next= p;
mMessages = msg;
needWake = mBlocked;
} else {
// 如果p不为空,表明消息队列中还有剩余消息,需要将新的msg加到消息尾
Message prev = null;
while (p != null && p.when <= when) {
prev = p;
p = p.next;
}
msg.next = prev.next;
prev.next = msg;
// 因为消息队列之前还剩余有消息,所以这里不用调用nativeWakeup
needWake = false;
}
}
if(needWake) {
// 调用nativeWake,以触发nativePollOnce函数结束等待
nativeWake(mPtr);
}
returntrue;
}
上面的代码比较简单,主要功能是:
将message按执行时间排序,并加入消息队。
根据情况调用nativeWake函数,以触发nativePollOnce函数,结束等待。建议 虽然代码简单,但是对于那些不熟悉多线程的读者,还是要细细品味一下mBlocked值的作用。我们常说细节体现美,代码也一样,这个小小的mBlocked正是如此。
nativeWake函数分析
nativeWake函数的代码如下所示:
static voidandroid_os_MessageQueue_nativeWake(JNIEnv* env, jobject obj, jint ptr){
NativeMessageQueue* nativeMessageQueue = // 取出NativeMessageQueue对象
reinterpret_cast(ptr);
returnnativeMessageQueue->wake(); // 调用它的wake函数
}
void NativeMessageQueue::wake() {
mLooper->wake(); // 层层调用,现在转到mLooper的wake函数
}
//Native Looper的wake函数代码如下:
void Looper::wake() {
ssize_tnWrite;
do {
// 向管道的写端写入一个字符
nWrite = write(mWakeWritePipeFd, "W", 1);
} while(nWrite == -1 && errno == EINTR);
}
Wake()函数则更为简单,仅仅向管道的写端写入一个字符”W”,这样管道的读端就会因为有数据可读而从等待状态中醒来。
nativePollOnce函数分析
nativePollOnce()的实现函数是android_os_MessageQueue_nativePollOnce,代码如下:
static voidandroid_os_MessageQueue_nativePollOnce(JNIEnv* env, jobject obj,
jintptr, jint timeoutMillis)
NativeMessageQueue* nativeMessageQueue =
reinterpret_cast(ptr);
// 取出NativeMessageQueue对象,并调用它的pollOnce
nativeMessageQueue->pollOnce(timeoutMillis);
}
分析pollOnce函数:
void NativeMessageQueue::pollOnce(inttimeoutMillis) {
mLooper->pollOnce(timeoutMillis); // 重任传递到Looper的pollOnce函数
}
Looper的pollOnce函数如下:
inline int pollOnce(int timeoutMillis) {
returnpollOnce(timeoutMillis, NULL, NULL, NULL);
}
上面的函数将调用另外一个有4个参数的pollOnce函数,这个函数的原型如下:int pollOnce(int timeoutMillis, int* outFd, intoutEvents, void* outData)
其中:
timeOutMillis参数为超时等待时间。如果为-1,则表示无限等待,直到有事件发生为止。如果值为0,则无需等待立即返回。
outFd用来存储发生事件的那个文件描述符 。
outEvents用来存储在该文件描述符1上发生了哪些事件,目前支持可读、可写、错误和中断4个事件。这4个事件其实是从epoll事件转化而来。后面我们会介绍大名鼎鼎的epoll。
outData用于存储上下文数据,这个上下文数据是由用户在添加监听句柄时传递的,它的作用和pthread_create函数最后一个参数param一样,用来传递用户自定义的数据。
另外,pollOnce函数的返回值也具有特殊的意义,具体如下:
当返回值为ALOOPER_POLL_WAKE时,表示这次返回是由wake函数触发的,也就是管道写端的那次写事件触发的。
返回值为ALOOPER_POLL_TIMEOUT表示等待超时。
返回值为ALOOPER_POLL_ERROR,表示等待过程中发生错误。
返回值为ALOOPER_POLL_CALLBACK,表示某个被监听的句柄因某种原因被触发。这时,outFd参数用于存储发生事件的文件句柄,outEvents用于存储所发生的事件。
上面这些知识是和epoll息息相关的。
提示 查看Looper的代码会发现,Looper采用了编译选项(即#if和#else)来控制是否使用epoll作为I/O复用的控制中枢。鉴于现在大多数系统都支持epoll,这里仅讨论使用epoll的情况。
epoll基础知识介绍:
epoll机制提供了Linux平台上最高效的I/O复用机制,因此有必要介绍一下它的基础知识。
从调用方法上看,epoll的用法和select/poll非常类似,其主要作用就是I/O复用,即在一个地方等待多个文件句柄的I/O事件。
下面通过一个简单例子来分析epoll的工作流程。
/* ① 使用epoll前,需要先通过epoll_create函数创建一个epoll句柄。
下面一行代码中的10表示该epoll句柄初次创建时候分配能容纳10个fd相关信息的缓存。
对于2.6.8版本以后的内核,该值没有实际作用,这里可以忽略。其实这个值的主要目的是
确定分配一块多大的缓存。现在的内核都支持动态拓展这块缓存,所以该值就没有意义了 */
int epollHandle = epoll_create(10);
/* ② 得到epoll句柄后,下一步就是通过epoll_ctl把需要监听的文件句柄加入到epoll句柄中。
除了指定文件句柄本身的fd值外,同时还需要指定在该fd上等待什么事件。epoll支持四类事件,
分别是EPOLLIN(句柄可读)、EPOLLOUT(句柄可写),EPOLLERR(句柄错误)、EPOLLHUP(句柄断)。
epoll定义了一个结构体struct epoll_event来表达监听句柄的诉求。
假设现在有一个监听端的socket句柄listener,要把它加入到epoll句柄中 */
struct epoll_event
listenEvent; //先定义一个event
/* EPOLLIN表示可读事件,EPOLLOUT表示可写事件,另外还有EPOLLERR,EPOLLHUP表示
系统默认会将EPOLLERR加入到事件集合中 */
listenEvent.events=EPOLLIN;// 指定该句柄的可读事件
// epoll_event中有一个联合体叫data,用来存储上下文数据,本例的上下文数据就是句柄自己
listenEvent.data.fd=listenEvent;
/* ③ EPOLL_CTL_ADD将监听fd和监听事件加入到epoll句柄的等待队列中;
EPOLL_CTL_DEL将监听fd从epoll句柄中移除;
EPOLL_CTL_MOD修改监听fd的监听事件,例如本来只等待可读事件,现在需要同时等待
可写事件,那么修改listenEvent.events 为EPOLLIN|EPOLLOUT后,再传给epoll句柄*/
epoll_ctl(epollHandle, EPOLL_CTL_ADD, listener, &listenEvent);
/* 当把所有感兴趣的fd都加入到epoll句柄后,就可以开始坐等感兴趣的事情发生了。
为了接收所发生的事情,先定义一个epoll_event数组 */
struct epoll_event
resultEvents[10];
int timeout = -1;
while(1)
{
/* ④ 调用epoll_wait用于等待事件。其中timeout可以指定一个超时时间,
resultEvents用于接收发生的事件,10为该数组的大小。
epoll_wait函数的返回值有如下含义:
nfds大于0表示所监听的句柄上有事件发生;
nfds等于0表示等待超时;
nfds小于0表示等待过程中发生了错误*/
int nfds = epoll_wait(epollHandle, resultEvents, 10, timeout);
if (nfds == -1) {
// epoll_wait发生了错误
} else if (nfds == 0) {
//发生超时,期间没有发生任何事件
} else {
// ⑤resultEvents用于返回那些发生了事件的信息
for (int i = 0; i < nfds; i++) {
struct epoll_event&event = resultEvents[i];
if (event & EPOLLIN) {
/*⑥ 收到可读事件。到底是哪个文件句柄发生该事件呢?可通过event.data这个联合
体取得 前传递给epoll的上下文数据,该上下文信息可用于判断到底是谁发生了事件*/
......
}
.......//其他处理
}
}
}
epoll整体使用流程如上面代码所示,基本和select/poll类似,不过作为Linux平台最高效的I/O复用机制,这里有些内容供读者参考,
epoll的效率为什么会比select高?其中一个原因是调用方法。每次调用select时,都需要把感兴趣的事件复制到内核中,而epoll只在epll_ctl进行加入的时候复制一次。另外,epoll内部用于保存事件的数据结构使用的是红黑树,查找速度很快。而select采用数组保存信息,不但一次能等待的句柄个数有限,并且查找起来速度很慢。当然,在只等待少量文件句柄时,select和epoll效率相差不是很多,但还是推荐使用epoll。
epoll等待的事件有两种触发条件,一个是水平触发(EPOLLLEVEL),另外一个是边缘触发(EPOLLET,ET为Edge Trigger之意),这两种触发条件的区别非常重要。读者可通过man epoll查阅系统提供的更为详细的epoll机制。
pollOnce()函数分析
下面分析带4个参数的pollOnce()函数,代码如下:
int Looper::pollOnce(int timeoutMillis, int*outFd, int* outEvents,
void** outData) {
intresult = 0;
for(;;) { // 一个无限循环
// mResponses是一个Vector,这里首先需要处理response
while (mResponseIndex < mResponses.size()) {
const Response& response = mResponses.itemAt(mResponseIndex++);
ALooper_callbackFunc callback = response.request.callback;
if (!callback) {// 首先处理那些没有callback的Response
int ident = response.request.ident; // ident是这个Response的id
int fd = response.request.fd;
int events = response.events;
void* data = response.request.data;
......
if (outFd != NULL) * outFd = fd;
if (outEvents != NULL) * outEvents = events;
if (outData != NULL) * outData = data;
/ * 实际上,对于没有callback的Response,pollOnce只是返回它的
ident,并没有实际做什么处理。因为没有callback,所以系统也不知道如何处理 * /
return ident;
}
}
if(result != 0) {
if(outFd != NULL) * outFd = 0;
if (outEvents != NULL) * outEvents = NULL;
if (outData != NULL) * outData = NULL;
return result;
}
// 调用pollInner函数。注意,它在for循环内部
result = pollInner(timeoutMillis);
}
}
初看上面的代码,可能会让人有些丈二和尚摸不着头脑。但是把pollInner()函数分析完毕,大家就会明白很多。pollInner()函数非常长,把用于调试和统计的代码去掉,结果如下:
int Looper::pollInner(int timeoutMillis) {
if(timeoutMillis != 0 && mNextMessageUptime != LLONG_MAX) {
nsecs_t now = systemTime(SYSTEM_TIME_MONOTONIC);
......//根据Native Message的信息计算此次需要等待的时间
timeoutMillis = messageTimeoutMillis;
}
intresult = ALOOPER_POLL_WAKE;
mResponses.clear();
mResponseIndex = 0;
#ifdef LOOPER_USES_EPOLL // 只讨论使用epoll进行I/O复用的方式
structepoll_event eventItems[EPOLL_MAX_EVENTS];
// 调用epoll_wait,等待感兴趣的事件或超时发生
inteventCount = epoll_wait(mEpollFd, eventItems, EPOLL_MAX_EVENTS,
timeoutMillis);
#else
......//使用别的方式进行I/O复用
#endif
//从epoll_wait返回,这时候一定发生了什么事情
mLock.lock();
if(eventCount < 0) { //返回值小于零,表示发生错误
if(errno == EINTR) {
goto Done;
}
//设置result为ALLOPER_POLL_ERROR,并跳转到Done
result = ALOOPER_POLL_ERROR;
gotoDone;
}
//eventCount为零,表示发生超时,因此直接跳转到Done
if(eventCount == 0) {
result = ALOOPER_POLL_TIMEOUT;
gotoDone;
}
#ifdef LOOPER_USES_EPOLL
// 根据epoll的用法,此时的eventCount表示发生事件的个数
for (inti = 0; i < eventCount; i++) {
intfd = eventItems[i].data.fd;
uint32_t epollEvents = eventItems[i].events;
/ * 之前通过pipe函数创建过两个fd,这里根据fd知道是管道读端有可读事件。
读者还记得对nativeWake函数的分析吗?在那里我们向管道写端写了一个”W”字符,这样
就能触发管道读端从epoll_wait函数返回了 * /
if(fd == mWakeReadPipeFd) {
if (epollEvents & EPOLLIN) {
// awoken函数直接读取并清空管道数据,读者可自行研究该函数
awoken();
}
......
}else {
/ * mRequests和前面的mResponse相对应,它也是一个KeyedVector,其中存储了
fd和对应的Request结构体,该结构体封装了和监控文件句柄相关的一些上下文信息,
例如回调函数等。我们在后面的小节会再次介绍该结构体 * /
ssize_t requestIndex = mRequests.indexOfKey(fd);
if (requestIndex >= 0) {
int events = 0;
// 将epoll返回的事件转换成上层LOOPER使用的事件
if (epollEvents & EPOLLIN) events |= ALOOPER_EVENT_INPUT;
if (epollEvents & EPOLLOUT) events |= ALOOPER_EVENT_OUTPUT;
if (epollEvents & EPOLLERR) events |= ALOOPER_EVENT_ERROR;
if (epollEvents & EPOLLHUP) events |= ALOOPER_EVENT_HANGUP;
// 每处理一个Request,就相应构造一个Response
pushResponse(events, mRequests.valueAt(requestIndex));
}
......
}
}
Done: ;
#else
......
#endif
// 除了处理Request外,还处理Native的Message
mNextMessageUptime = LLONG_MAX;
while(mMessageEnvelopes.size() != 0) {
nsecs_t now = systemTime(SYSTEM_TIME_MONOTONIC);
const MessageEnvelope& messageEnvelope =mMessageEnvelopes.itemAt(0);
if(messageEnvelope.uptime <= now) {
{
sp handler = messageEnvelope.handler;
Message message = messageEnvelope.message;
mMessageEnvelopes.removeAt(0);
mSendingMessage = true;
mLock.unlock();
/ * 调用Native的handler处理Native的Message
从这里也可看出Native Message和Java层的Message没有什么关系 * /
handler->handleMessage(message);
}
mLock.lock();
mSendingMessage = false;
result = ALOOPER_POLL_CALLBACK;
}else {
mNextMessageUptime = messageEnvelope.uptime;
break;
}
}
mLock.unlock();
// 处理那些带回调函数的Response
for (size_t i = 0; i < mResponses.size();i++) {
const Response& response = mResponses.itemAt(i);
ALooper_callbackFunc callback = response.request.callback;
if(callback) {// 有了回调函数,就能知道如何处理所发生的事情了
int fd = response.request.fd;
int events = response.events;
void* data = response.request.data;
// 调用回调函数处理所发生的事件
int callbackResult = callback(fd, events, data);
if (callbackResult == 0) {
// callback函数的返回值很重要,如果为0,表明不需要再次监视该文件句柄
removeFd(fd);
}
result = ALOOPER_POLL_CALLBACK;
}
}
returnresult;
}
看完代码了,是否还有点模糊?那么,回顾一下pollInner函数的几个关键点:
首先需要计算一下真正需要等待的时间。
调用epoll_wait函数等待。
epoll_wait函数返回,这时候可能有三种情况:
发生错误,则跳转到Done处。
超时,这时候也跳转到Done处。
epoll_wait监测到某些文件句柄上有事件发生。
假设epoll_wait因为文件句柄有事件而返回,此时需要根据文件句柄来分别处理:
如果是管道读这一端有事情,则认为是控制命令,可以直接读取管道中的数据。
如果是其他FD发生事件,则根据Request构造Response,并push到Response数组中。
真正开始处理事件是在有Done标志的位置。
首先处理Native的Message。调用Native Handler的handleMessage处理该Message。
处理Response数组中那些带有callback的事件。
上面的处理流程还是比较清晰的,但还是有个一个拦路虎,那就是mRequests,下面就来清剿这个拦路虎。
添加监控请求
添加监控请求其实就是调用epoll_ctl增加文件句柄。下面通过从Native的Activity找到的一个例子来分析mRequests。
static jint
loadNativeCode_native(JNIEnv* env, jobject clazz,jstring path,
jstringfuncName,jobject messageQueue,
jstringinternalDataDir, jstring obbDir,
jstringexternalDataDir, int sdkVersion,
jobject jAssetMgr,jbyteArray savedState)
{
......
/ * 调用Looper的addFd函数。第一个参数表示监听的fd;第二个参数0表示ident;
第三个参数表示需要监听的事件,这里为只监听可读事件;第四个参数为回调函数,当该fd发生
指定事件时,looper将回调该函数;第五个参数code为回调函数的参数 * /
code->looper->addFd(code->mainWorkRead,0,
ALOOPER_EVENT_INPUT,mainWorkCallback, code);
......
}
Looper的addFd()代码如下所示:
int Looper::addFd(int fd, int ident, int events,
ALooper_callbackFunccallback, void* data) {
if (!callback) {
/ * 判断该Looper是否支持不带回调函数的文件句柄添加。一般不支持,因为没有回调函数
Looper也不知道如何处理该文件句柄上发生的事情 * /
if(! mAllowNonCallbacks) {
return -1;
}
......
}
#ifdef LOOPER_USES_EPOLL
intepollEvents = 0;
// 将用户的事件转换成epoll使用的值
if(events & ALOOPER_EVENT_INPUT) epollEvents |= EPOLLIN;
if(events & ALOOPER_EVENT_OUTPUT) epollEvents |= EPOLLOUT;
{
AutoMutex _l(mLock);
Request request; // 创建一个Request对象
request.fd = fd; // 保存fd
request.ident = ident; // 保存id
request.callback = callback; //保存callback
request.data = data; // 保存用户自定义数据
struct epoll_event eventItem;
memset(& eventItem, 0, sizeof(epoll_event));
eventItem.events = epollEvents;
eventItem.data.fd = fd;
// 判断该Request是否已经存在,mRequests以fd作为key值
ssize_t requestIndex = mRequests.indexOfKey(fd);
if(requestIndex < 0) {
// 如果是新的文件句柄,则需要为epoll增加该fd
int epollResult = epoll_ctl(mEpollFd, EPOLL_CTL_ADD, fd, &eventItem);
......
// 保存Request到mRequests键值数组
mRequests.add(fd, request);
}else {
// 如果之前加过,那么就修改该监听句柄的一些信息
int epollResult = epoll_ctl(mEpollFd, EPOLL_CTL_MOD, fd, &eventItem);
......
mRequests.replaceValueAt(requestIndex, request);
}
}
#else
......
#endif
return1;
}
处理监控请求
我们发现在pollInner()函数中,当某个监控fd上发生事件后,就会把对应的Request取出来调用。
pushResponse(events, mRequests.itemAt(i));
此函数如下:
void Looper::pushResponse(int events, constRequest& request) {
Responseresponse;
response.events = events;
response.request = request; //其实很简单,就是保存所发生的事情和对应的Request
mResponses.push(response);//然后保存到mResponse数组
}
根据前面的知识可知,并不是单独处理Request,而是需要先收集Request,等到Native Message消息处理完之后再做处理。这表明,在处理逻辑上,Native Message的优先级高于监控FD的优先级。下面来了解如何添加Native的Message。
Native的sendMessage
Android 2.2中只有Java层才可以通过sendMessage()往MessageQueue中添加消息,从4.0开始,Native层也支持sendMessage()了。sendMessage()的代码如下:
void Looper::sendMessage(constsp& handler,
constMessage& message) {
//Native的sendMessage函数必须同时传递一个Handler
nsecs_tnow = systemTime(SYSTEM_TIME_MONOTONIC);
sendMessageAtTime(now, handler, message); //调用sendMessageAtTime
}
void Looper::sendMessageAtTime(nsecs_t uptime,
constsp& handler,
constMessage& message) {
size_t i= 0;
{
AutoMutex _l(mLock);
size_t messageCount = mMessageEnvelopes.size();
// 按时间排序,将消息插入到正确的位置上
while (i < messageCount &&
uptime >= mMessageEnvelopes.itemAt(i).uptime) {
i += 1;
}
MessageEnvelope messageEnvelope(uptime, handler, message);
mMessageEnvelopes.insertAt(messageEnvelope, i, 1);
// mSendingMessage和Java层中的那个mBlocked一样,是一个小小的优化措施
if(mSendingMessage) {
return;
}
}
// 唤醒epoll_wait,让它处理消息
if (i ==0) {
wake();
}
}
MessageQueue总结
1.消息处理的大家族合照MessageQueue只是消息处理大家族的一员,该家族的成员合照如图
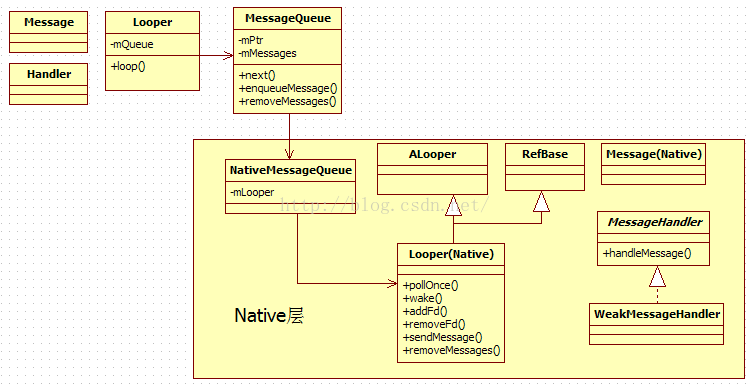
结合前述内容可从图中得到:
Java层提供了Looper类和MessageQueue类,其中Looper类提供循环处理消息的机制,MessageQueue类提供一个消息队列,以及插入、删除和提取消息的函数接口。另外,Handler也是在Java层常用的与消息处理相关的类。
MessageQueue内部通过mPtr变量保存一个Native层的NativeMessageQueue对象,mMessages保存来自Java层的Message消息。
NativeMessageQueue保存一个native的Looper对象,该Looper从ALooper派生,提供pollOnce和addFd等函数。
Java层有Message类和Handler类,而Native层对应也有Message类和MessageHandler抽象类。在编码时,一般使用的是MessageHandler的派生类WeakMessageHandler类。注意 在include/media/stagfright/foundation目录下也定义了一个ALooper类,它是供stagefright使用的类似Java消息循环的一套基础类。这种同名类的产生,估计是两个事先未做交流的Group的人写的。
2.MessageQueue处理流程总结
MessageQueue核心逻辑下移到Native层后,极大地拓展了消息处理的范围,总结一下有以下几点:
MessageQueue继续支持来自Java层的Message消息,也就是早期的Message加Handler的处理方式。MessageQueue在Native层的代表NativeMessageQueue支持来自Native层的Message,是通过Native的Message和MessageHandler来处理的。
NativeMessageQueue还处理通过addFd添加的Request。处理逻辑上看,先是Native的Message,然后是Native的Request,最后才是Java的Message。