导语:作为java领域最受欢迎的任务调度库之一,quartz为开发者提供了丰富的任务调度功能,比如让某段程序在每天18:00准时执行。本文将通过demo和源码,讲解quartz如何使用、主要功能有哪些、原理是什么,并挑选几段有用的源码片段进行解读。

1、quartz简介
quartz,即石英的意思,隐喻如石英表般对时间的准确把握。
quartz是一个由java编写的任务调度库,由OpenSymphony组织开源出来。那么问题来了,任务调度是个什么东西?举个栗子,现在有N个任务(程序),要求在指定时间执行,比如每周二3点执行任务A、每天相隔5s执行任务B等等,这种多任务拥有多种执行策略就是任务调度。而quartz的核心作用,是使任务调度变得丰富、高效、安全,开发者只需要调几个quartz接口并做简单配置,即可实现上述需求。
quartz号称能够同时对上万个任务进行调度,拥有丰富的功能特性,包括任务调度、任务持久化、可集群化、插件等。目前最新版本是2.2.3,从github[1]上看,2.2.4已在开发中。
quartz有竞品吗?有,那就是java Timer。quartz相对于java Timer的优势包括任务持久化、配置更丰富、线程池等等,详见官网[2]解释,两者在Spring上的用法可见这篇文章[^OpenSymphony Quartz和java Timer]。
接下来,笔者将从一个简单的demo开始,顺着demo里使用到的quartz接口,逐个分析quartz主要功能及其原理。限于篇幅,demo中未涉及的功能,本文不涉及,比如集群化等。最后,挑选2段对大家日常开发有用的源码进行解读。
读这篇文章有什么用
- 对一个任务调度系统产生初步的原理级了解
- 更正确地使用quartz
- 学到如何采用多线程进行任务调度的源码
- 学到如何避免GC的源码
- 精(xian)力(de)充(dan)沛(teng),随便找篇技术文读读
[^OpenSymphony Quartz和java Timer]: yaerfeng:Spring定时器配置的两种实现方式OpenSymphony Quartz和java Timer详解
2、使用代码demo[3]
本文的demo程序由2个java文件和quartz.properties组成,quartz.properties是可选的,因为quartz有默认配置。demo实现从当前时间开始,每隔2s执行一次JobImpl类的execute()方法。
- TestQuartz.java
/**
* 从当前时间开始,每隔2s执行一次JobImpl#execute()
* @author hlx
*/
public class TestQuartz {
public static void main(String[] args) throws SchedulerException, InterruptedException {
// 创建调度器
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
Scheduler scheduler = schedulerFactory.getScheduler();
// 创建任务
JobDetail jobDetail = JobBuilder.newJob(JobImpl.class).withIdentity("myJob", "jobGroup").build();
// 创建触发器
// withIntervalInSeconds(2)表示每隔2s执行任务
Date triggerDate = new Date();
SimpleScheduleBuilder schedBuilder = SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(2).repeatForever();
TriggerBuilder triggerBuilder = TriggerBuilder.newTrigger().withIdentity("myTrigger", "triggerGroup");
Trigger trigger = triggerBuilder.startAt(triggerDate).withSchedule(schedBuilder).build();
// 将任务及其触发器放入调度器
scheduler.scheduleJob(jobDetail, trigger);
// 调度器开始调度任务
scheduler.start();
}
}
- JobImpl.java
/**
* @author hlx
*/
public class JobImpl implements Job {
public void execute(JobExecutionContext context) {
System.out.println("job impl running");
}
}
- quartz.properties(可选)
#调度器名,默认名是QuartzScheduler
org.quartz.scheduler.instanceName: TestQuartzScheduler
#============================================================================
# Configure ThreadPool 配置线程池
#============================================================================
org.quartz.threadPool.class: org.quartz.simpl.SimpleThreadPool
org.quartz.threadPool.threadCount: 10
org.quartz.threadPool.threadPriority: 5
#============================================================================
# Configure JobStore 配置任务存储方式
#============================================================================
#相当于扫描频率
org.quartz.jobStore.misfireThreshold: 60000
org.quartz.jobStore.class: org.quartz.simpl.RAMJobStore
我们顺着注释看到,TestQuartz.main()依次创建了scheduler(调度器)、job(任务)、trigger(触发器),其中,job指定了JobImpl,trigger保存job的触发执行策略(每隔2s执行一次),scheduler将job和trigger绑定在一起,最后scheduler.start()启动调度,每隔2s触发执行JobImpl.execute(),打印出job impl running。
对于quartz.properties,简单场景下,开发者不用自定义配置,使用quartz默认配置即可,但在要求较高的使用场景中还是要自定义配置,比如通过org.quartz.threadPool.threadCount设置足够的线程数可提高多job场景下的运行性能。更详尽的配置见官网配置说明页。
如果让我们设计一个任务调度系统,会像quartz那样将job、trigger、scheduler解藕吗?quartz这样设计的原因,笔者认为有两点:
- job与trigger解藕,其实就是将任务本身和任务执行策略解藕,这样可以方便实现N个任务和M个执行策略自由组合,比较容易理解;
- scheduler单独分离出来,相当于一个指挥官,可以从全局做调度,比如监听哪些trigger已经ready、分配线程等等,如果没有scheduler,则trigger间会竞争混乱,难以实现诸如trigger优先级等功能,也无法合理使用资源。
下面,笔者将分别就job、trigger、scheduler进行原理分析。
3、job(任务)
job由若干个class和interface实现。
Job接口
开发者想要job完成什么样的功能,必须且只能由开发者自己动手来编写实现,比如demo中的JobImpl,这点无容置疑。但要想让自己的job被quartz识别,就必须按照quartz的规则来办事,这个规则就是job实现类必须实现Job接口,比如JobImpl就实现了Job。
Job只有一个execute(JobExecutionContext),JobExecutionContext保存了job的上下文信息,比如绑定的是哪个trigger。job实现类必须重写execute(),执行job实际上就是运行execute()。
JobDetailImpl类 / JobDetail接口
JobDetailImpl类实现了JobDetail接口,用来描述一个job,定义了job所有属性及其get/set方法。了解job拥有哪些属性,就能知道quartz能提供什么样的能力,下面笔者用表格列出job若干核心属性。
| 属性名 | 说明 |
|---|---|
| class | 必须是job实现类(比如JobImpl),用来绑定一个具体job |
| name | job名称。如果未指定,会自动分配一个唯一名称。所有job都必须拥有一个唯一name,如果两个job的name重复,则只有最前面的job能被调度 |
| group | job所属的组名 |
| description | job描述 |
| durability | 是否持久化。如果job设置为非持久,当没有活跃的trigger与之关联的时候,job会自动从scheduler中删除。也就是说,非持久job的生命期是由trigger的存在与否决定的 |
| shouldRecover | 是否可恢复。如果job设置为可恢复,一旦job执行时scheduler发生hard shutdown(比如进程崩溃或关机),当scheduler重启后,该job会被重新执行 |
| jobDataMap | 除了上面常规属性外,用户可以把任意kv数据存入jobDataMap,实现job属性的无限制扩展,执行job时可以使用这些属性数据。此属性的类型是JobDataMap,实现了Serializable接口,可做跨平台的序列化传输 |
JobBuilder类
// 创建任务
JobDetail jobDetail = JobBuilder.newJob(JobImpl.class).withIdentity("myJob", "jobGroup").build();
上面代码是demo一个片段,可以看出JobBuilder类的作用:接收job实现类JobImpl,生成JobDetail实例,默认生成JobDetailImpl实例。
这里运用了建造者模式:JobImpl相当于Product;JobDetail相当于Builder,拥有job的各种属性及其get/set方法;JobBuilder相当于Director,可为一个job组装各种属性。
4、trigger(触发器)
trigger由若干个class和interface实现。
SimpleTriggerImpl类 / SimpleTrigger接口 / Trigger接口
SimpleTriggerImpl类实现了SimpleTrigger接口,SimpleTrigger接口继承了Trigger接口,它们表示触发器,用来保存触发job的策略,比如每隔几秒触发job。实际上,quartz有两大触发器:SimpleTrigger和CronTrigger,限于篇幅,本文仅介绍SimpleTrigger。
Trigger诸类保存了trigger所有属性,同job属性一样,了解trigger属性有助于我们了解quartz能提供什么样的能力,下面笔者用表格列出trigger若干核心属性。
在quartz源码或注释中,经常使用fire(点火)这个动词来命名属性名,表示触发job。
| 属性名 | 属性类型 | 说明 |
|---|---|---|
| name | 所有trigger通用 | trigger名称 |
| group | 所有trigger通用 | trigger所属的组名 |
| description | 所有trigger通用 | trigger描述 |
| calendarName | 所有trigger通用 | 日历名称,指定使用哪个Calendar类,经常用来从trigger的调度计划中排除某些时间段 |
| misfireInstruction | 所有trigger通用 | 错过job(未在指定时间执行的job)的处理策略,默认为MISFIRE_INSTRUCTION_SMART_POLICY。详见这篇blog^Quartz misfire |
| priority | 所有trigger通用 | 优先级,默认为5。当多个trigger同时触发job时,线程池可能不够用,此时根据优先级来决定谁先触发 |
| jobDataMap | 所有trigger通用 | 同job的jobDataMap。假如job和trigger的jobDataMap有同名key,通过getMergedJobDataMap()获取的jobDataMap,将以trigger的为准 |
| startTime | 所有trigger通用 | 触发开始时间,默认为当前时间。决定什么时间开始触发job |
| endTime | 所有trigger通用 | 触发结束时间。决定什么时间停止触发job |
| nextFireTime | SimpleTrigger私有 | 下一次触发job的时间 |
| previousFireTime | SimpleTrigger私有 | 上一次触发job的时间 |
| repeatCount | SimpleTrigger私有 | 需触发的总次数 |
| timesTriggered | SimpleTrigger私有 | 已经触发过的次数 |
| repeatInterval | SimpleTrigger私有 | 触发间隔时间 |
TriggerBuilder类
// 创建触发器
// withIntervalInSeconds(2)表示每隔2s执行任务
Date triggerDate = new Date();
SimpleScheduleBuilder schedBuilder = SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(2).repeatForever();
TriggerBuilder triggerBuilder = TriggerBuilder.newTrigger().withIdentity("myTrigger", "triggerGroup");
Trigger trigger = triggerBuilder.startAt(triggerDate).withSchedule(schedBuilder).build();
上面代码是demo一个片段,可以看出TriggerBuilder类的作用:生成Trigger实例,默认生成SimpleTriggerImpl实例。同JobBuilder一样,这里也运用了建造者模式。
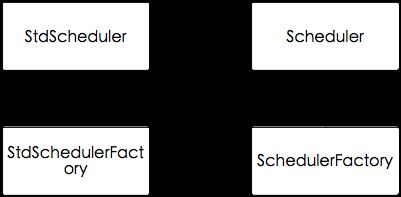
5、scheduler(调度器)
scheduler主要由StdScheduler类、Scheduler接口、StdSchedulerFactory类、SchedulerFactory接口、QuartzScheduler类实现,它们的关系见下面UML图。
// 创建调度器
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
Scheduler scheduler = schedulerFactory.getScheduler();
......
// 将任务及其触发器放入调度器
scheduler.scheduleJob(jobDetail, trigger);
// 调度器开始调度任务
scheduler.start();
上面代码是demo一个片段,可以看出这里运用了工厂模式,通过factory类(StdSchedulerFactory)生产出scheduler实例(StdScheduler)。scheduler是整个quartz的关键,为此,笔者把demo中用到的scheduler接口的源码加上中文注释做个讲解。
- StdSchedulerFactory.getScheduler()源码
public Scheduler getScheduler() throws SchedulerException {
// 读取quartz配置文件,未指定则顺序遍历各个path下的quartz.properties文件
// 解析出quartz配置内容和环境变量,存入PropertiesParser对象
// PropertiesParser组合了Properties(继承Hashtable),定义了一系列对Properties的操作方法,比如getPropertyGroup()批量获取相同前缀的配置。配置内容和环境变量存放在Properties成员变量中
if (cfg == null) {
initialize();
}
// 获取调度器池,采用了单例模式
// 其实,调度器池的核心变量就是一个hashmap,每个元素key是scheduler名,value是scheduler实例
// getInstance()用synchronized防止并发创建
SchedulerRepository schedRep = SchedulerRepository.getInstance();
// 从调度器池中取出当前配置所用的调度器
Scheduler sched = schedRep.lookup(getSchedulerName());
......
// 如果调度器池中没有当前配置的调度器,则实例化一个调度器,主要动作包括:
// 1)初始化threadPool(线程池):开发者可以通过org.quartz.threadPool.class配置指定使用哪个线程池类,比如SimpleThreadPool。先class load线程池类,接着动态生成线程池实例bean,然后通过反射,使用setXXX()方法将以org.quartz.threadPool开头的配置内容赋值给bean成员变量;
// 2)初始化jobStore(任务存储方式):开发者可以通过org.quartz.jobStore.class配置指定使用哪个任务存储类,比如RAMJobStore。先class load任务存储类,接着动态生成实例bean,然后通过反射,使用setXXX()方法将以org.quartz.jobStore开头的配置内容赋值给bean成员变量;
// 3)初始化dataSource(数据源):开发者可以通过org.quartz.dataSource配置指定数据源详情,比如哪个数据库、账号、密码等。jobStore要指定为JDBCJobStore,dataSource才会有效;
// 4)初始化其他配置:包括SchedulerPlugins、JobListeners、TriggerListeners等;
// 5)初始化threadExecutor(线程执行器):默认为DefaultThreadExecutor;
// 6)创建工作线程:根据配置创建N个工作thread,执行start()启动thread,并将N个thread顺序add进threadPool实例的空闲线程列表availWorkers中;
// 7)创建调度器线程:创建QuartzSchedulerThread实例,并通过threadExecutor.execute(实例)启动调度器线程;
// 8)创建调度器:创建StdScheduler实例,将上面所有配置和引用组合进实例中,并将实例存入调度器池中
sched = instantiate();
return sched;
}
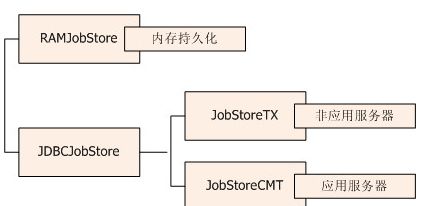
上面有个过程是初始化jobStore,表示使用哪种方式存储scheduler相关数据。quartz有两大jobStore:RAMJobStore和JDBCJobStore。RAMJobStore把数据存入内存,性能最高,配置也简单,但缺点是系统挂了难以恢复数据。JDBCJobStore保存数据到数据库,保证数据的可恢复性,但性能较差且配置复杂。
- QuartzScheduler.scheduleJob(JobDetail, Trigger)源码
public Date scheduleJob(JobDetail jobDetail,
Trigger trigger) throws SchedulerException {
// 检查调度器是否开启,如果关闭则throw异常到上层
validateState();
......
// 获取trigger首次触发job的时间,以此时间为起点,每隔一段指定的时间触发job
Date ft = trig.computeFirstFireTime(cal);
if (ft == null) {
throw new SchedulerException(
"Based on configured schedule, the given trigger '" + trigger.getKey() + "' will never fire.");
}
// 把job和trigger注册进调度器的jobStore
resources.getJobStore().storeJobAndTrigger(jobDetail, trig);
// 通知job监听者
notifySchedulerListenersJobAdded(jobDetail);
// 通知调度器线程
notifySchedulerThread(trigger.getNextFireTime().getTime());
// 通知trigger监听者
notifySchedulerListenersSchduled(trigger);
return ft;
}
- QuartzScheduler.start()源码
public void start() throws SchedulerException {
......
// 这句最关键,作用是使调度器线程跳出一个无限循环,开始轮询所有trigger触发job
// 原理详见“如何采用多线程进行任务调度”
schedThread.togglePause(false);
......
}
6、quartz线程模型

上图是笔者在eclipse中调试demo时的线程图,可以见到,除了第一条主线程外,还有10条工作线程,和1条调度器线程。
工作线程以{instanceName}_Worker-{[1-10]}命名。线程数目由quart.properties文件中的org.quartz.threadPool.threadCount配置项指定。所有工作线程都会放在线程池中,即所有工作线程都放在SimpleThreadPool实例的一个LinkedListWorkerThread是SimpleThreadPool的内部类,这么设计可能是因为不想继承SimpleThreadPool但又想调用其protected方法,或者想隐藏WorkerThread。线程池还拥有两个LinkedListavailWorkers和busyWorkers,分别存放空闲和正在执行job的工作线程。
调度器线程以{instanceName}_QuartzSchedulerThread命名。该线程将根据trigger找出要待运行job,然后从threadpool中拿出工作线程来执行。调度器线程主体是QuartzSchedulerThread对象。
{instanceName}指的是quart.properties文件中的org.quartz.scheduler.instanceName配置值,这里是TestQuartzScheduler。[1-10]表示从1到10的任意数字。
7、精彩源码解读
本节中,笔者从quartz源码中挑选了两段代码,之所以选择这两段代码,是因为它们实现了线程间通信、加锁同步、避免GC等功能,对工程师们很有帮助。
如何采用多线程进行任务调度
- QuartzSchedulerThread.java
// 调度器线程一旦启动,将一直运行此方法
public void run() {
......
// while()无限循环,每次循环取出时间将到的trigger,触发对应的job,直到调度器线程被关闭
// halted是一个AtomicBoolean类变量,有个volatile int变量value,其get()方法仅仅简单的一句return value != 0,get()返回结果表示调度器线程是否开关
// volatile修饰的变量,存取必须走内存,不能通过cpu缓存,这样一来get总能获得set的最新真实值,因此volatile变量适合用来存放简单的状态信息
// 顾名思义,AtomicBoolean要解决原子性问题,但volatile并不能保证原子性,详见http://blog.csdn.net/wxwzy738/article/details/43238089
while (!halted.get()) {
try {
// check if we're supposed to pause...
// sigLock是个Object对象,被用于加锁同步
// 需要用到wait(),必须加到synchronized块内
synchronized (sigLock) {
while (paused && !halted.get()) {
try {
// wait until togglePause(false) is called...
// 这里会不断循环等待,直到QuartzScheduler.start()调用了togglePause(false)
// 调用wait(),调度器线程进入休眠状态,同时sigLock锁被释放
// togglePause(false)获得sigLock锁,将paused置为false,使调度器线程能够退出此循环,同时执行sigLock.notifyAll()唤醒调度器线程
sigLock.wait(1000L);
} catch (InterruptedException ignore) {}
}
......
}
......
// 如果线程池中的工作线程个数 > 0
if(availThreadCount > 0) {
......
// 获取马上到时间的trigger
// 允许取出的trigger个数不能超过一个阀值,这个阀值是线程池个数与org.quartz.scheduler.batchTriggerAcquisitionMaxCount配置值间的最小者
triggers = qsRsrcs.getJobStore().acquireNextTriggers(
now + idleWaitTime, Math.min(availThreadCount, qsRsrcs.getMaxBatchSize()), qsRsrcs.getBatchTimeWindow());
......
// 执行与trigger绑定的job
// shell是JobRunShell对象,实现了Runnable接口
// SimpleThreadPool.runInThread(Runnable)从线程池空闲列表中取出一个工作线程
// 工作线程执行WorkerThread.run(Runnable),详见下方WorkerThread的讲解
if (qsRsrcs.getThreadPool().runInThread(shell) == false) { ...... }
} else {......}
......
} catch(RuntimeException re) {......}
} // while (!halted)
......
}
- WorkerThread.java
public void run(Runnable newRunnable) {
synchronized(lock) {
if(runnable != null) {
throw new IllegalStateException("Already running a Runnable!");
}
runnable = newRunnable;
lock.notifyAll();
}
}
// 工作线程一旦启动,将一直运行此方法
@Override
public void run() {
boolean ran = false;
// 工作线程一直循环等待job,直到线程被关闭,原理同QuartzSchedulerThread.run()中的halted.get()
while (run.get()) {
try {
// 原理同QuartzSchedulerThread.run()中的synchronized (sigLock)
// 锁住lock,不断循环等待job,当job要被执行时,WorkerThread.run(Runnable)被调用,job运行环境被赋值给runnable
synchronized(lock) {
while (runnable == null && run.get()) {
lock.wait(500);
}
// 开始执行job
if (runnable != null) {
ran = true;
// runnable.run()将触发运行job实现类(比如JobImpl.execute())
runnable.run();
}
}
} catch (InterruptedException unblock) {
......
}
}
......
}
总的来说,核心代码就是在while循环中调用Object.wait(),等待可以跳出while循环的条件成立,当条件成立时,立马调度Object.notifyAll()使线程跳出while。通过这样的代码,可以实现调度器线程等待启动、工作线程等待job等功能。
如何避免GC
Quartz里提供了一种方案,用来避免某些对象被GC。方案其实简单而实用,就是QuartzScheduler类创建了一个列表ArrayList,如果某对象被add进该列表,则意味着QuartzScheduler实例引用了此对象,那么此对象至少在QuartzScheduler实例存活时不会被GC。
哪些对象要避免GC?通过源码可看到,调度器池和db管理器对象被放入了holdToPreventGC,但实际上两种对象是static的,而static对象属于GC root,应该是不会被GC的,所以即使不放入holdToPreventGC,这两种对象也不会被GC,除非被class unload或jvm生命结束。
static变量所指对象在heap中,如果变量不再指向该对象,比如赋值为null,对象会被GC
-
https://github.com/quartz-scheduler/quartz ↩
-
http://www.quartz-scheduler.org ↩
-
https://github.com/star2478/java-quartz ↩