序言
开一个新坑,缅怀最近快读吐了的重组和选择主导下的微生物中的进化。由于该领域其实还十分的新,所以其中有很多的词我会尽可能中英夹杂,以避免我翻译的主观性(还有错误)。另外顺序方面我会尽可能保证逻辑的连贯性,但是最大可能还是我想到哪里就写到哪了。
另外,以下大部分的内容我都是基于wiki翻译的,还会加上自己一些理解和补充,算是对中文材料的补充吧。
glossary
概念or现象
-
speciation
概念
物种形成是一个群落进化成为一个distinct的物种的过程-
分类
从地理模式上,是可以分成allopatric(异域)、peripatric(外域)、parapatric(邻域)、sympatric(同域)。前两者都是完全地理分隔,邻域则是部分分隔,同域则是无明显的地理分隔。
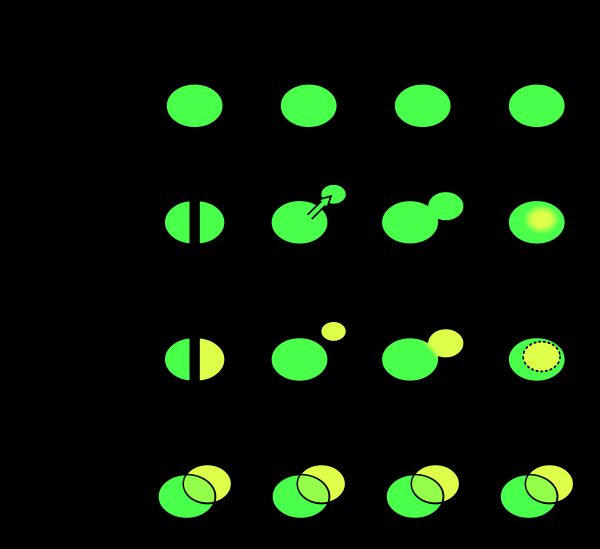 Comparision of allopatric, peripatric, parapatric and sympatric speciation
Comparision of allopatric, peripatric, parapatric and sympatric speciation 个人理解
物种形成的核心应该就是如何形成,以及如何维持分离,前者经常可以看到,但是后者也是十分重要的一个环节。当然分离不一定是一个完整的分离,如果分离(物种隔离/地理隔离)不完整的话,还是有可能继续的发生杂交的事件,甚至形成新的物种。
-
Exaptation
- 概念
扩展适应,指在进化过程中某条路径可能是由于某个蛋白质功能的改变。例如一个鸟类的羽毛开始为了保暖,后来进化出了辅助飞翔的功能。也可以叫preadaptation(预适应)
- 概念
-
Genetic hitchhiking/genetic draft/hitchhiking effect
- 概念
中文名很难听就不叫了,如果一个allele的频率改变不是因为自然选择,而是因为其邻近存在一个经受selective sweep的基因,这样的现象称之为hitchhiking(顺风车)。 - 易错
也可以叫genetic draft 而不是drift。虽然两者都是随机的进化过程。 - 个人理解
关于selective sweep可以看后面的词条和示意图。hitchhiking就是说由于基因不是一个个独立的个体,同在一个DNA单链上的相邻基因往往会同时的发生一些变化和转移,这样其中一个基因受选择的同时,也会对邻近的基因造成影响。(一人得道鸡犬升天),但是这个现象只有在早期的selective sweep时才很明显。
- 概念
-
Background selection
- 概念
背景选择,类似于hitchhiking。但恰好相反,即非有害的locus由于靠近有害的alleles,加上自然地负选择,从而导致自身基因频率的降低。 - 讨论
由于背景选择而导致的neutral variation的改变,可以通过在有害区域的总突变率的改变的指数函数来建模。
背景选择的总贡献(overall effect)更像是effective population size的减少,所以这个现象可以作为“当基因diversity与population size”无关的一种补充假设。
在高重组速率的区域中,中性的loci更像是可以“逃脱”这个效应。 - measure
可以通过测量,neutral variants与“基于突变率和genetic drift”的中性预测模型的偏移程度来定量衡量该效应的大小。
- 概念
-
selective sweep
- 概念
中文名大概可以叫“选择扫描”,也很难听。与上面的hitchhiking相对应,这个现象就是由于选择(selective),而导致DNA上邻近某个适应性突变的差异(variation)的减少或者消失的过程。 - 分类
大致上可以分成三种,其中。- classic or hard selective sweep,即一个非常占优势的突变的产生,会非常快的reducing genetic variation
- soft sweep,即原本就有一些中性的突变,但是由于环境的改变,但由于本来就存在多种variation,所以不会消除所有的差异。
- multiple origins soft sweep,2的加强版。
(有个毛线差异)
-
示意图
 HardSelectiveSweep
HardSelectiveSweep
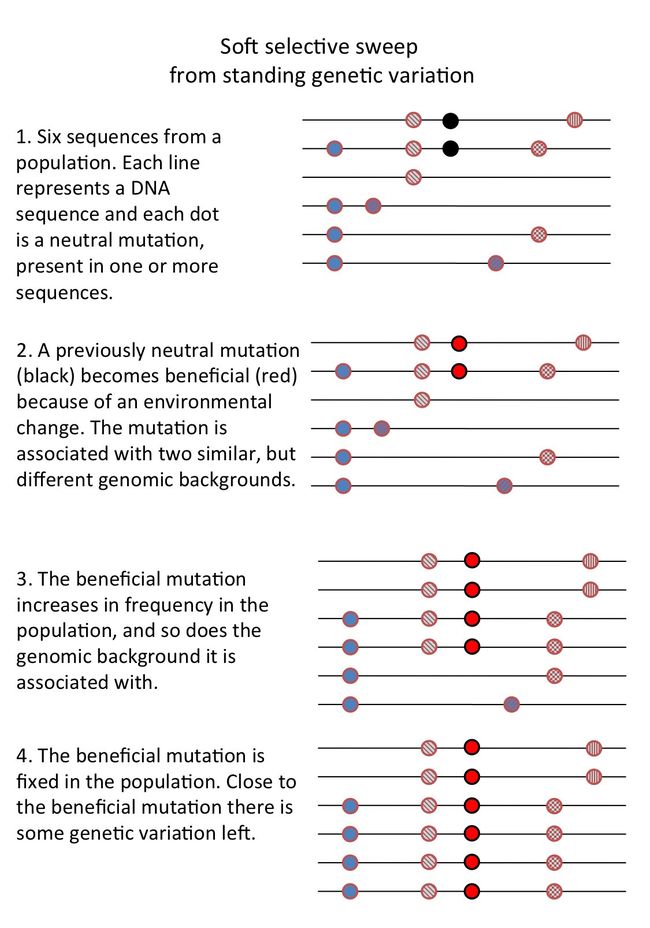 SoftSGVSelectiveSweep
SoftSGVSelectiveSweep - 个人理解和补充
邻近的基因之间的关系可以称之为linkage disequilibrium,但由于在自然的进化中,基因间的重组会导致haplotype中allele的reshuffling而导致没有单个haplotype可以dominate该群体。所以如果可以检测到很强的linkage disequilibrium的话,可以说存在一个最近的selective sweep。
该现象在与疾病相关的医院菌株间可能会发现较多。由于抗生素的使用、宿主与致病菌之间的“军备竞赛”使菌株经常遭受bottleneck。
- 概念
-
Introgression
- 概念
基因渗入,也可以叫做渗透性的杂交。基因上来说,就是两个基因在两个基因库(gene pool)之间的交流,一般需要与其中某个父代进行多次的回交(backcrossing)才能产生。是个长期的过程 - 讨论
与简单的杂交(hybridization)不同,introgression一般会造成复杂的父代基因的混合。
- 概念
-
negative selection/purify slection
- 概念
负选择,相较于正选择。可以去除在随机突变中产生的有害的基因多样性。
- 概念
-
Ecotype
- 概念
直译大概叫“生态型”,有时也叫“生态物种”(ecospecies),描述一个物种内部,出现的地理、群落、race上的显著基因差异,一般是为了适应特定的环境。
- 概念
-
Effective population size
- 概念
有效种群大小,在一个理想群体中,在随机漂变影响下,能够与野生群体产生相同的等位基因分布或者等量的同系繁殖的个体(individual)数量。(在某些简单的场景中,即能够繁衍的个体的数量,)但一般都比有效种群大小大很多。并且同样的一个群落由于讨论的东西不同,可以有不同的有效种群大小。 - 定量方法
有效种群大小一般以coalescence time(溯祖时间) 或者 平均逗留时间(sojourn) 来进行定量。
- within-species genetic diversity / mutation rate,称之为coalescent effective population size。(见coalescent time的定义) 由于理想的二倍体群落中,pairwise nucleotide diversity = 4 * 突变率 * effective population size
- 1/S_critical,其中被除数为selection coefficient(当选择比基因漂变强时)称之为selectioneffective population size
- 影响因素
- fluctuating population size
- breeding sex ratio
- Overlapping generations (降低Ne)
- spatial dispersion (Ne = 4π * dispersal distance的方差的平方 * 个体的密度)
- 方差与平均数的差异。由于有效种群大小是假定Poisson distribution of family (offspring) numbers。而Poisson又是假设方差和平均数相等
- 讨论
容易受到瓶颈效应的影响。有效种群大小(small = more drift, vice versa)。
- 概念
-
parallel evolution
- 概念
指两个进化上并不关联的两个物种,由于受到相同的进化压力而导致相似的进化路径 - 相似的词
convergent evolution(趋同进化)
- 概念

-
Reverse ecology
- 概念
通过基因组在没有先验假设(priori assumptions)的情况下研究生态的研究思路。 - 提出者
2007被Matthew Rockman提出 - 词源
由于reverse genetics是通过比较同个基因在不同表型下的不同序列来研究基因的功能。
- 概念
-
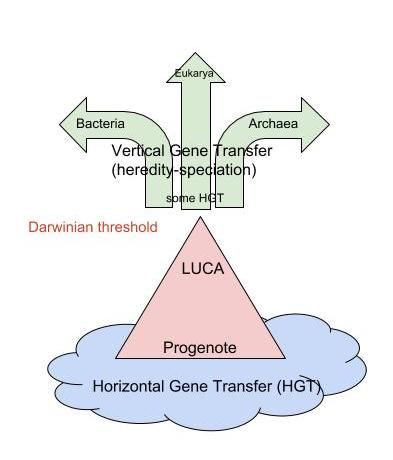
Darwinian threshold
- 概念
在进化过程中,第一个细胞将其基因的转移由主要是水平转移变化到垂直转移的转移时间段。这个过程开始于最近共同祖先开始难以被HGT并且变成一个可以被自然选择有效选择的带有垂直遗传能力的个体。自此开始,生命才有了现代的树结构的谱系。
- 概念
Metrics or test
由于以下涉及很多的方法、test、定量方法,原理方面尽量不说太多,毕竟每一个都是可以说很多很多包括计算的,这里主要讲,是什么,怎么算,代表什么,为什么等问题。
-
HKA test
- 目的
通过比较物种内部的多态性和物种之间的差异(divergence),判断观测到的差别(differences)是由于中性进化还是适应性进化导致的。作为McDonald-Kreitman test的前身。 - 解读
不打算解读了,因为下面的McDonald-Kreitman test更清晰直接一点。 - 计算方式

即对每个 locus(L),A样本中观测到的具有 多态性的位点上的差异的数目的 和,减去,多态性的期望的平方,然后除以方差。然后将该公式应用于样本B,
- 目的
-
McDonald-Kreitman test
- 目的:用于检测是否发生了适应性进化(adaptive evolution),并且检测替换中有多少导致了正选择。
- 为什么?
一般正/负选择都是影响非同义突变,如果负选择增强,那么非同义突变就会减少,但被选择掉的个体同时也会对多态性(polymorphism)也影响很大,所以最后会导致Dn/Ds < Pn/Ps(Pn, Dn变小,Ps也变小,Ds几乎不变)。相反,如果是正选择变强了的话,其对多态性(polymorphism)的影响很小,但对分化(divergence)影响就很大,最后导致Dn/Ds < Pn/Ps(Pn, Dn变大,Ps几乎不变,Ds变大) - 计算方法
比较组内两种(中性/非中性)的(polymorphism)变化,和物种间的(substitutions)。其中polymorphism即组内的比较,substitutions则是组间的比较,这里的组指物种。

其中零假设即Dn/Ds = Pn/Ps。如果负选择占优,即Dn/Ds < Pn/Ps,即有害的突变强影响了polymorphism。反之亦然。
并且也可以通过以上比例的换算,得出有多少成分的碱基替换fixed by natural selection。
其中α代表了proportion of substitutions driven by positive selection,取值范围为负无穷到1,负数为sampling error或者violations of the model. -
Tajima's D
目的:
Tajima's D 是定量两种genetic diversity之间的差值,即pairwise differences的平均数目和segregating sites的数目的差。
Tajima's D test是为了区分随机(中性)进化的DNA序列与非随机进化的DNA序列。其中包括directional selection or balancing selection-
核心:
- the mean pairwise difference (π)
- the number (S) of segregating sites
为什么这么算?
这里讲不完,看我的下一篇文章吧,希望可以尽快写完。-
计算方法
双倍体的基因组,基于neutral theory model,对于一个有着固定数目的群落来说,存在以下关系。

其中S为segragating sites的数目,N为有效种群大小,n为样本数目,i为index,θ为pairwise的差异。 但如果发生了 选择、地理变化、其它破坏中性模型的因素( 其中也包括了rate heterogeneity和introgression),那么就会破坏公式两边的相等,其中两边的差异就需要可以作为计算 Tajima's D*的关键。

d则是两个θ之间的差异,而分母则是variance.如果展开这个式子的话,就是
其中,
k代表了平均的SNP数目,pairwise的将两两之间的SNP加起来,再除以N中选2的所有可能性的数目(不考虑顺序)
S代表样本中总的polymorphisms的数目,即有多少个segragating sites
剩下的a1,e1......这些都是在neutral model中推导出来的,所以十分复杂,在这里就先简单的记住好了。也可以看 watterson estimator
我会开新的一篇文章专门讲一下这个过程的推导。
(一起学习)主要的文献就是1975的watterson在On the Number of Segregating Sites in Genetical Models without Recombination提到的kimura的一些补充和推导。- 如何解读
Value of Tajima's D Mathematical reason biological interpretation 1 biological interpretation 2 equal 0 两种对θ(pairwise差异的估计)相等,Average Heterozygosity = Segregating sites observed variation similar to expected variation No evidence of selection negative Fewer haplotypes(lower average heterozygosity) than segregating sites 少数的alleles频率很高 最近发生selective sweep, 在瓶颈效应后发生了种群扩张, 与某个sweep的基因相关联 positive More haplotypes than segregating sites 稀有的alleles频率低 平衡的选择(Balancing selection), 突然的种群收缩
- 如何解读
-
Fay and Wu's H
概念
类似于Tajima's D,是它的一种进阶版。-
进阶之处
在某种情境下是,如果某些alleles在不同群落之间的多态性很低。那么可能由三种原因造成。- 该序列受到很强的负选择,所以任何新的突变都是有害的并且会很快的呗消除掉
- 该序列刚刚经受selective sweep,所以所有的alleles变得同质性很强。而这个观测到的alleles则是少数派,突变时间很近。
- 刚刚经受了瓶颈效应,所以现在的个体都是从很少/一个共同祖先起源的。
这种情况下,计算Tajima's D会得到一个负数的值,但是无法区分是选择还是selective sweep造成的,所以需要Fay and Wu's H.
不仅仅考虑两个种群,而且考虑outgroup的物种数据,从而得知在这两个物种分开之前的祖先的状态。
-
Ka/Ks ratio
- 目的
用以判断在一堆的同源蛋白质编码基因上的突变是受neutral、purifying、beneficial那种主导。定义上来说很长the ratio of the number of nonsynonymous substitutions per non-synonymous site (pN) to the number of synonymous substitutions per synonymous site (pS),这里就不说中文了,如果对其中的per site有疑问,可以见我的另一篇文章用以判断选择压力的Ka/Ks的计算 - 同义词/易错词
Ka/Ks又叫做ω或者dN/dS - 解读
- 大于1,则是Positive or Darwinian selection (driving change) 使其发生突变
- 小于1,则是purifying or stabilizing selection (acting against change) 抵消/消除了突变
- 等于1,有可能no/neutral selection,但也可能是正负选择的相互抵消。
- 目的
-
Fst(fixation indexes)
目的
由遗传结构(genetic structure)计算种群的差异程度。算是Wright's F-statistics的特例。为什么这么算?
-
计算方法

其中p是整个群落中该allele的平均频率,σS的平方是该allele在不同 子群落(subpopulation)中频率的方差,并根据子群落的大小进行加权。σT的平方则是该allele在 整个群落中的方差。
其中如果mutation rate很低,也可以将Fst与溯祖时间( coalescent times)相联系上,从而用T0:子群落中祖先到个体的时间和T:整个群落祖先到个体的时间,来对Fst进行估计。

某种程度上说,Fst也可以理解成,相较于整个群体,从子群体中拿出随机两个个体能有多接近?
由于以上两种计算方式有点麻烦,也很难定量的得到需要的等式右边的变量。所以一种简单的估算如下:

在 between or within 不同的子群落中任选两个个体(individual),比较pairwise之间差异的平均数目。其中的bias会由于样本的数量太小、与群落差异大而造成 解读
Fst取值从0到1,0时认为是个完全随机交配的群体。1时则认为所有的遗传变异都可以被群落结构所解释,所以两个群落之间不分享任何遗传的差异。
Reference
维基百科 biodiversity的词条
Review 15 Krause
Population Genetics V: Effective population size, Ne
how to calculate Tajima's D
Tajima's D original paper
On the Number of Segregating Sites in Genetical Models without Recombination