前面的章节重点关注词:如何识别它们,分析它们的结构,分配给他们词汇类别,以及获得它们的含义。我们还看到了如何识别词序列或n-grams中的模式。然而,这些方法只触碰到支配句子的复杂约束的表面。我们需要一种方法处理自然语言中显著的歧义。我们还需要能够应对这样一个事实,句子有无限的可能,而我们只能写有限的程序来分析其结构和发现它们的含义。
本章的目的是要回答下列问题:
我们如何使用形式化语法来描述无限的句子集合的结构?
我们如何使用句法树来表示句子结构?
语法分析器如何分析一个句子并自动构建句法树?
一路上,我们将覆盖英语句法的基础,并看到句子含义有系统化的一面,只要我们确定了句子结构,将更容易捕捉。
PS:书中的讲解顺序个人感觉比较难以理解,下面我会以自己的理解顺序来重新调整
一、文法简述
文法(语法)是用于描述语言的语法结构的形式规则。任何一种语言都有它自己的文法,我们最常接触的文法自然语言里有主谓宾这样的文法一样。(文法好像还分为句法和词法,不去纠结这个,我们正常来说都是在处理句法)
使用文法有很多显而易见的好处(毕竟大家都是有9年义务教育的人,都懂的),但在计算机中进行文法分析还需要解决两个主要的问题,其一是文法在计算机中的表达与存储方法,以及语料数据集;其二是文法解析的算法。
1. 文法在计算机中的表达与存储方法
在计算机中,我们可以用树状结构图来表示,如下图所示,S表示句子;NP、VP、PP是名词、动词、介词短语(短语级别);N、V、P分别是名词、动词、介词。

实际存储的时候上述的树可以表示为(S (NP (N Boeing)) (VP (V is) (VP (V located) (PP (P in) (NP (N Seattle))))))。
同时,互联网上已经有成熟的、手工标注的语料数据集,例如The Penn Treebank Project (Penn Treebank II Constituent Tags)。
2. 文法解析的算法
如何描述文法,有两种主流观点,其中一种是短语结构文法,英文术语是:Constituency = phrase structure grammar = context-free grammars (CFGs)。
这种短语语法用固定数量的rule分解句子为短语和单词、分解短语为更短的短语或单词等更小的单元。一个是取自WSJ语料库的短语结构树示例:

另一种是依存结构,用单词之间的依存关系来表达语法。如果一个单词修饰另一个单词,则称该单词依赖于另一个单词:
这一部分是接下来的重点
二、上下文无关文法(Context-Free Grammer)
CFG是一个四元组:G =(N,T,P,S),其中
- N是非终结符(Nonterminals)的有限集合
- T是终结符(Terminals)的有限集合,且N∩T=Φ
- P是产生式(Productions)的有限集合,形如:A→α,其中A∈N(左部),α∈(N∪T)*(右部),若α=ε,则称A→ε为空产生式(也可以记为A →)
- S是非终结符,称为文法的开始符号(Start symbol)
使用CFG可以很快速准确地定义简单的算术表达式,例如N = {E} T = {+,*,(,),-,id} S = E四元组,S = E表明文法从E开始,也就是WSJ语料库的短语结构树中的S,那么产生式有这几种:E → E + E; E → E * E; E →(E); E → -E; E → id。
抽象地数学表示是这样的,简单来说,其实N就是就是NP、VP、PP和N等的集合,T就是我们的单词。
定义这样的四元组,主要是为了使用分析树表示文法,也就是我们上面所看到的树的结构。
分析树的定义:
- 根由开始符号所标记
- 每个叶子由一个终结符、非终结符、或ε标记
- 每个内部结点由一个非终结符标记
- 若A是某内部节点的标记,且X1,X2,…,Xn是该节点从左到右所有孩子的标记,则A→X1X2…Xn是一个产生式。若A→ε,则标记为A的结点可以仅有一个标记为ε的孩子
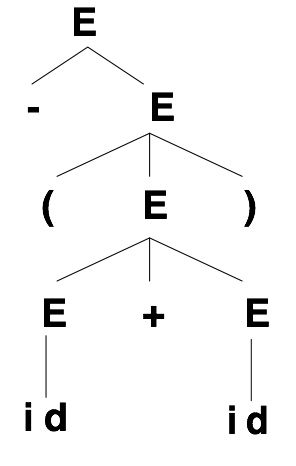
其实抛开这些文绉绉的定义,我觉得最重要的一点就是:要求产生式的左部有且仅有一个非终结符
1. 递归下降解析器
一种最简单的分析器将一个文法作为如何将一个高层次的目标分解成几个低层次的子目标的规范来解释。顶层的目标是找到一个 S。S→NP VP 产生式允许分析器替换这个目标为两个子目标:找到一个 NP,然后找到一个 VP。每个这些子目标都可以再次被子目标的子目标替代,使用左侧有 NP 和 VP 的产生式。最终,这种扩张过程达到子目标,如找到词 telescope。这样的子目标可以直接与输入序列比较,如果下一个单词匹配就取得成功。如 果没有匹配,分析器必须备份,并尝试其它选择:
import nltk
from nltk import CFG
grammar1 = nltk.CFG.fromstring("""
S -> NP VP
VP -> V NP | V NP PP
PP -> P NP
V -> "saw" | "ate" | "walked"
NP -> "John" | "Mary" | "Bob" | Det N | Det N PP
Det -> "a" | "an" | "the" | "my"
N -> "man" | "dog" | "cat" | "telescope" | "park"
P -> "in" | "on" | "by" | "with"
""")
rd_parser = nltk.RecursiveDescentParser(grammar1)
sent = 'Mary saw a dog'.split()
for t in rd_parser.parse(sent):
print(t)
可以调用nltk.app.rdparser()来查看分析过程:

递归下降分析是一种自上而下分析。自上而下分析器在检查输入之前先使用文法预测输 入将是什么。
三个主要缺点:
- 左递归产生式:NP-> NP PP 会陷入死循环
- 处理不符合句子的词和结构时候浪费时间
- 回溯过程过重会丢掉计算过的分析,重新计算
2. 移进-归约解析器
移进-归约分析器是一种自下而上分析器,它尝试找到对应文法产生式右侧的词和短语的序列,用左侧的替换它们,直到整个句子归约为一个 S。
移位-规约分析器反复将下一个输入词推到堆栈,如果堆栈上的前 n 项,匹配一些产生式的右侧的 n 个项目,那么就把它们弹出栈,并把产生式左边的项目压入栈。这种替换前 n 项为一项的操作就是规约操作。此操作只适用于堆栈的顶部;规约栈中的项目必须在后面的项目被压入栈之前做。当所有的输入都使用过,堆栈中只剩余一个项目,也就是一颗分析树作为它的根的 S 节点时,分析器完成。移位-规约分析器通过上述过程建立一颗分析树。每次弹出堆栈 n 个项目,它就将它们组合成部分的分析树,然后将这压回推栈:
sr_parse = nltk.ShiftReduceParser(grammar1)
for t in sr_parse.parse(sent):
print(t)
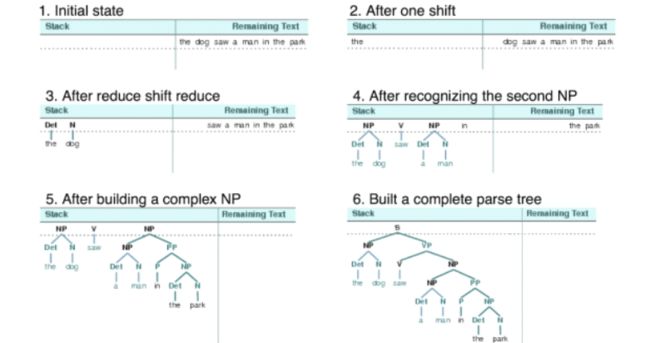
两个缺点:
- 由于堆栈的特殊性,只能找到一种解析
- 不能保证一定能找到解析
3. 左角落分析器
递归下降分析器的问题之一是当它遇到一个左递归产生式时,会进入无限循环。这是因为它盲目应用文法产生式而不考虑实际输入的句子。左角落分析器是自下而 上与自上而下方法的混合体。
左角落分析器是一个带自下而上过滤的自上而下的分析器。不像普通的递归下降分析器,它不会陷入左递归产生式的陷阱。在开始工作之前,左角落分析器预处理上下文无关文法建立一个表,其中每行包含两个单元,第一个存放非终结符,第二个存放那个非终结符可 能的左角落的集合
分析器每次考虑产生式时,它会检查下一个输入词是否与左角落表格中至少一种非终结符的类别相容。
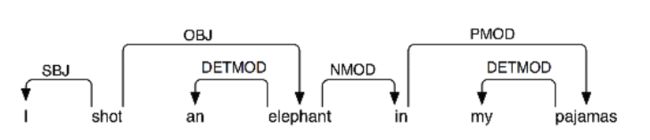
三、依存关系和依存文法
依存文法存在一个共同的基本假设:文法结构本质上包含词和词之间的依存(修饰)关系。一个依存关系连接两个词,分别是核心词( head)和依存词( dependent)。依存关系可以细分为不同的类型,表示两个词之间的具体句法关系。
依存关系是一个核心词与它的依赖之间的二元对称关系。一个句子的核心词通常是动词,所有其他词要么依赖于核心词,要么依赖路径与它联通。
依存关系表示是一个加标签的有向图,其中节点是词汇项,加标签的弧表示依赖关系, 从中心词到依赖。


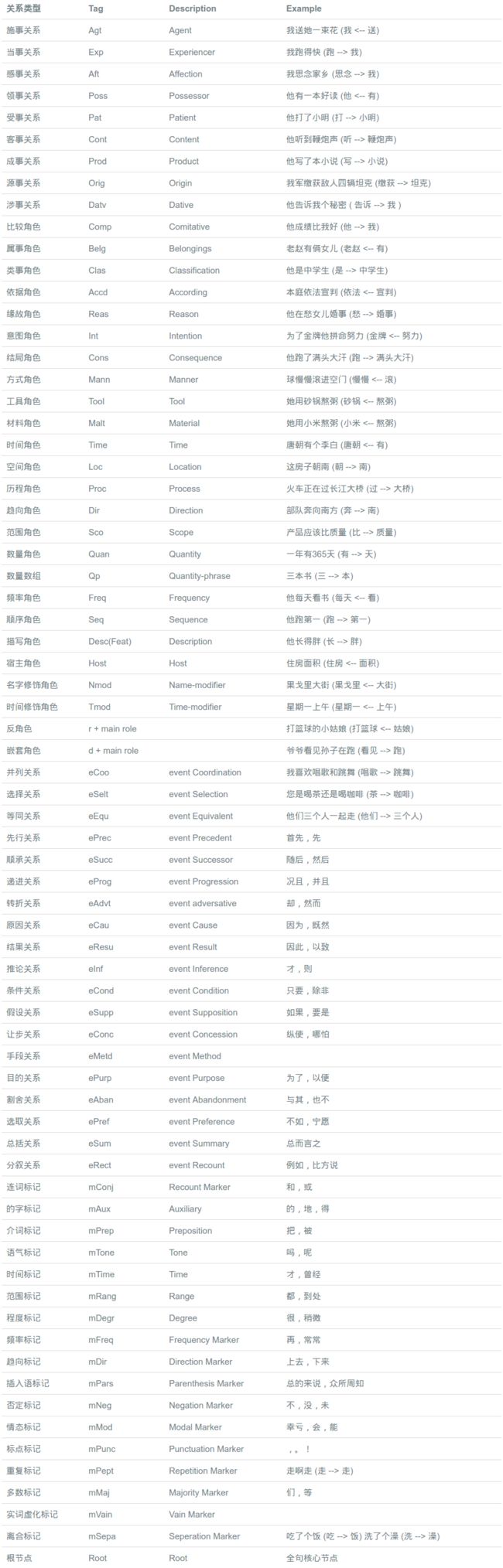
依存文法分析标注关系 (共14种) 及含义如下:
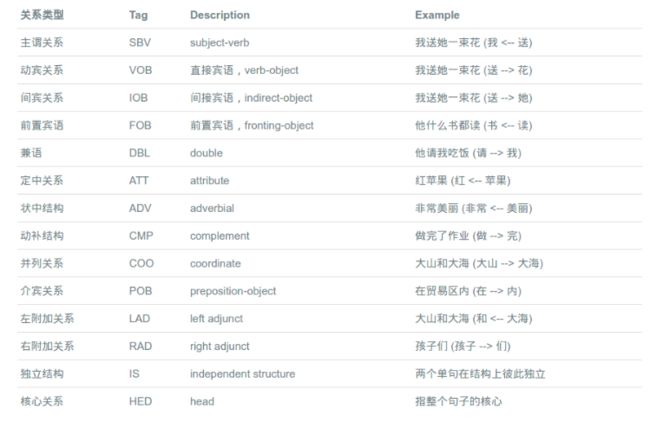
90年代的文法分析论文99%都是短语结构树,但后来人们发现依存文法树标注简单,parser准确率高,所以后来(特别是最近十年)基本上就是依存文法树的天下了(至少80%)。

目前研究主要集中在数据驱动的依存文法分析方法,即在训练实例集合上学习得到依存文法分析器,而不涉及依存语法理论的研究。数据驱动的方法的主要优势在于给定较大规模的训练数据,不需要过多的人工干预,就可以得到比较好的模型。因此,这类方法很容易应用到新领域和新语言环境。数据驱动的依存文法分析方法主要有两种主流方法:基于图( graph-based)的分析方法和基于转移( transition-based)的分析方法
1. 基于图的依存句法分析方法
基于图的方法将依存句法分析问题看成从完全有向图中寻找最大生成树的问题。一棵依存树的分值由构成依存树的几种子树的分值累加得到。根据依存树分值中包含的子树的复杂度,基于图的依存分析模型可以简单区分为一阶和高阶模型。 高阶模型可以使用更加复杂的子树特征,因此分析准确率更高,但是解码算法的效率也会下降。基于图的方法通常采用基于动态规划的解码算法,也有一些学者采用柱搜索(beam search)来提高效率。学习特征权重时,通常采用在线训练算法,如平均感知器( average dperceptron)。
目前基于图的方法的句法分析算法主要有自顶向下(Top Down),自底向上(Bottom Up),最大生成树(Spanning Tree)的方法。
例如在使用最大熵算法进行依存句法分析时就是生成一系列句法树,使用最大熵等模型去计算单条依存边的概率,从里面挑选出概率最大的那一棵作为输出。
具体可以参考:基于最大熵的依存句法分析
2. 基于转移的依存句法分析方法
基于转移的方法将依存树的构成过程建模为一个动作序列,将依存分析问题转化为寻找最优动作序列的问题。 早期,研究者们使用局部分类器(如支持向量机等)决定下一个动作。近年来,研究者们采用全局线性模型来决定下一个动作,一个依存树的分值由其对应的动作序列中每一个动作的分值累加得到。特征表示方面,基于转移的方法可以充分利用已形成的子树信息,从而形成丰富的特征,以指导模型决策下一个动作。模型通过贪心搜索或者柱搜索等解码算法找到近似最优的依存树。和基于图的方法类似,基于转移的方法通常也采用在线训练算法学习特征权重
总的来说,基于转移的依存句法分析方法是基于动作(或称转移)和一个分类器实现的,仿照人类从左到右的阅读顺序,其不断地读入单词,根据该单词和已构建的句法子树等信息建立分类模型,分类模型输出当前状态下的最佳动作,然后分析器根据最佳动作“拼装”句法树
目前基于转移的依存句法分析方法主要分为基于栈(Stack Based)和基于列表(List Based)两类,其中基于栈的又分为arc-standard算法和arc-eager算法。
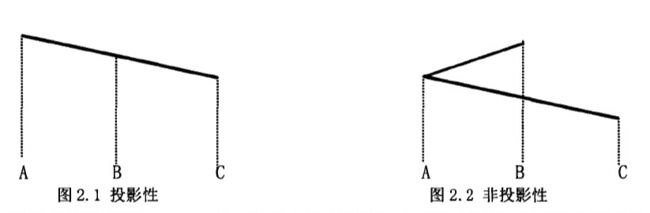
补充知识点:投射和非投射
投射性:如果词p依存于词q,那么p和q之间的任意词r就不能依存到p和q所构成的跨度之外
简单来说就是任意构成依存的两个单词构成一个笼子,把它们之间的所有单词囚禁在这个笼子里,内部的词的依存关系只能在这个笼子里,也就是说不存在交叉的依存弧,如下图所示:
3. 多模型融合的依存句法分析方法
基于图和基于转移的方法从不同的角度解决问题,各有优势。基于图的模型进行全局搜索但只能利用有限的子树特征,而基于转移的模型搜索空间有限但可以充分利用已构成的子树信息构成丰富的特征。详细比较发现,这两种方法存在不同的错误分布。因此,研究者们使用不同的方法融合两种模型的优势,常见的方法有:stacked learning;对多个模型的结果加权后重新解码(re-parsing);从训练语料中多次抽样训练多个模型(bagging)。
四、额外的笔记——语义依存分析
语义依存分析 (Semantic Dependency Parsing, SDP),分析句子各个语言单位之间的语义关联,并将语义关联以依存结构呈现。 使用语义依存刻画句子语义,好处在于不需要去抽象词汇本身,而是通过词汇所承受的语义框架来描述该词汇,而论元的数目相对词汇来说数量总是少了很多的。语义依存分析目标是跨越句子表层句法结构的束缚,直接获取深层的语义信息。 例如以下三个句子,用不同的表达方式表达了同一个语义信息,即张三实施了一个吃的动作,吃的动作是对苹果实施的。
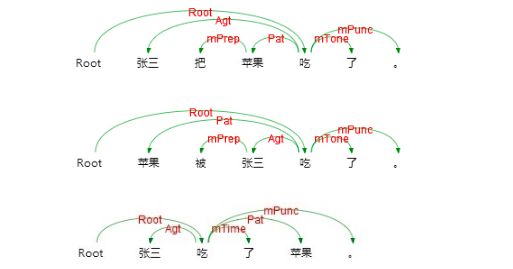
语义依存分析不受文法结构的影响,将具有直接语义关联的语言单元直接连接依存弧并标记上相应的语义关系。这也是语义依存分析与文法依存分析的重要区别。
再看一下三个句子的句法依存分析和语义依存分析的对比:

从上边的对比可以看出,虽然三个句子拥有不同的句子结构, 产生了不同的句法分析结果, 但是三个句子中语言单元之间的语义关系并没有发生变化, 从"吃"这个词来看, 它的主体, 客体...都没有发生变化。
再看一个例子:
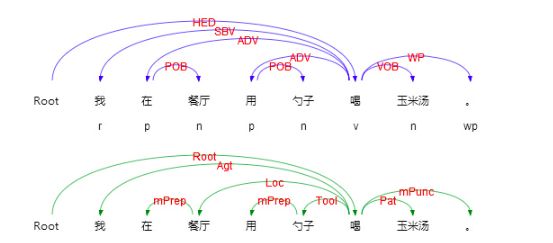
如上例对比了句法依存和语义分析的结果,可以看到两者存在两个显著差别:
句法依存某种程度上更重视非实词(如介词)在句子结构分析中的作用,而语义依存更倾向在具有直接语义关联的实词之间建立直接依存弧,非实词作为辅助标记存在
两者依存弧上标记的语义关系完全不同,语义依存关系是由论元关系引申归纳而来,可以用于回答问题,如我在哪里喝汤,我在用什么喝汤,谁在喝汤,我在喝什么。但是句法依存却没有这个能力
语义依存与语义角色标注之间也存在关联,语义角色标注只关注句子主要谓词的论元及谓词与论元之间的关系,而语义依存不仅关注谓词与论元的关系,还关注谓词与谓词之间、论元与论元之间、论元内部的语义关系。语义依存对句子语义信息的刻画更加完整全面。
语义依存关系分为三类,分别是主要语义角色,每一种语义角色对应存在一个嵌套关系和反关系;事件关系,描述两个事件间的关系;语义依附标记,标记说话者语气等依附性信息。
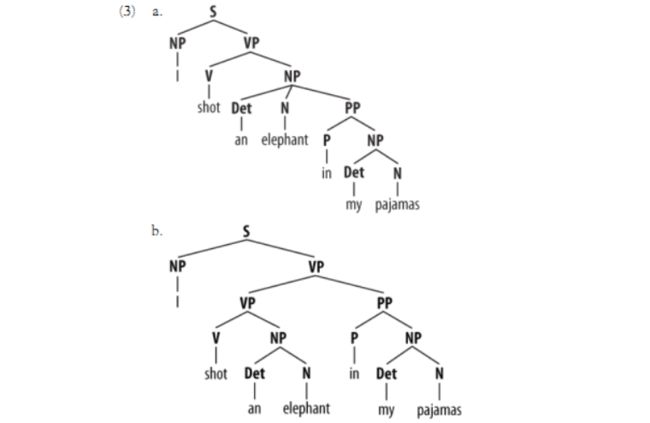
五、歧义
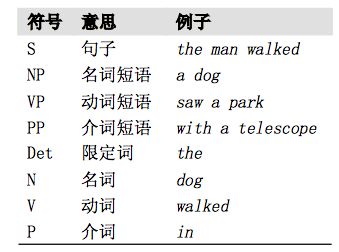
一个众所周知的关于歧义例子如下所示,来自 Groucho Marx 的电影,Animal Crac kers (1930):
While hunting in Africa, I shot an elephant in my pajamas. How an elephant got into my pajamas I’ll never know.
虽然我一直get不到这个歧义,不过歧义也很好理解,就是一句话有不同的理解,用我们之前的特征方法很难解决歧义的问题,但文法分析可以很好地解决:
参考
- https://www.cnblogs.com/CheeseZH/p/5768389.html
- http://www.hankcs.com/nlp/cs224n-dependency-parsing.html
- http://ltp.ai/demo.html
- https://www.cnblogs.com/CheeseZH/category/421499.html
- https://blog.csdn.net/sinat_26917383/article/details/55682996