背景
youtube视频推荐碰到的挑战:
- 大数据量,涉及到海量的用户和视频,需要高效的分布式学习算法和线上服务系统;
- 新鲜度,包括新上传的视频和利用用户最新的交互记录,平衡新旧视频的推荐;
- 噪声,用户的行为记录很少,并且受到外部影响,不易预测,用户满意度不好定义,上传内容包含很多非结构化数据。
模型涉及 10亿参数,千亿样本。
之前的方法有矩阵分解、协同过滤
系统概述

论文构建的推荐系统分为两个部分:候选集生成和排序,即常说的召回和排序两个步骤,召回从百万级的视频中快速精确的找到数百的视频,排序对这数百个视频进行精排序,最后将排名靠前的呈现为用户。
这样设计的好处是使得推荐系统可以应用于大数据量的情况,并且保证个性化和用户满意的推荐的结果,此外,还可以融合之前方法得到的候选集。
候选集生成

文章以每个视频为一个类别,问题看成是大规模的多分类问题,分为线上和线下两个部分。
线下训练
训练目标
在线下训练时计算了在给定用户U和上下文C的情况下,用户选择观看第i个视频的概率,用softmax函数表示如下:
其中vi表示第i个视频的embedding,u表示用户和上下文的embedding,对二者做内积,然后计算softmax得到看第i个视频的概率。从图中的可以看到,用户和上下文的向量是模型最后一层的输出,视频的向量是后面接的softmax层的连接权重,在训练时二者都可以得到更新,类似于word2vec的设置。
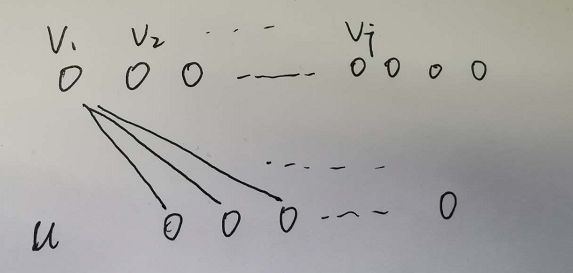
label设计
既然是多分类模型,就必然需要区分正类和负类。文中以是否看完某个视频作为区分标准,看完了为正,否则为负,虽然youtube有其他反映用户满意度的反馈信号,如点赞、调查等,但是这些信号很少,正样本会很少,不利于模型的训练,尤其是长尾视频。
损失函数
文章采用的损失函数是交叉熵,但是对百万量级的来说,计算成本过高。文章采用了负采样的方式降低计算量,采样了数千的负样本,速度加快了100倍以上。
负采样和分层softmax是常见的加快训练速度的方法,文章为什么没有采用分层的softmax呢,理论上是因为分层的softmax每层节点之间通常是不相关的,分类更困难,实际上的实验也确实没有达到负采样的效果。
输入特征
模型的输入特征是用户和上下文信息,主要包括用户看过的视频embedding累加求平均、搜索过的词做uni-gram和bi-gram的embedding累加求平均、人口统计信息和example age等,其中前两者利用了用户的历史信息,在实际实验中取的窗口大小为50,embedding维度为256,取平均也是因为比求和、求最大值等的实验效果更好;人口统计信息是为了新用户的冷启动,example age表示到样本出现到现在的时间,线上时值为0,它可以更好的拟合用户对新视频的偏好,用户其实是偏好于新的视频,即使于用户之前的观看兴趣不太相符,而且推荐系统往往有推荐历史数据的偏好,加入这个特征可以很好的进行修复这一点。

数据处理上,神经网络对数据的范围和分布比较敏感,更适合处理连续特征。稀疏的id特征经过embedding变成稠密的连续值,简单的连续特征也被标准化到[0,1]。
样本构造
在构造训练样本时,并非只选用推荐视频的播放情况,那样会让推荐系统偏向之前推荐过的视频,过于exploitation而缺少了exploration。文章选取了所有的播放记录,甚至嵌入在别的网站上的播放记录,这样做的好处是便于新视频的推荐,能利用上用户最新的动作。
为了不让少量观看次数多的用户主导了损失函数,每个用户都构造了相同数量的训练样本,达到统一权重的目的。
在预测的目标上,文章并没有从用户的一系列观看时间节点中随便选一个,用之前和之后的观看记录特征进行预测,而是预测用户的下一个观看的视频,防止信息泄露。

模型结构
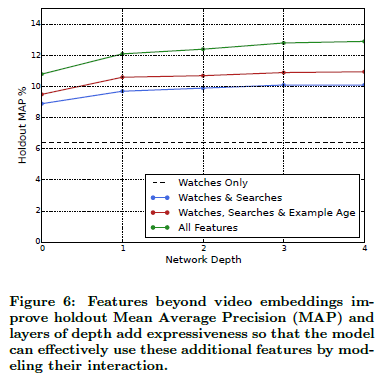
模型是一个多层的塔式NN结构,文章依次增加隐层的宽度和深度,直到效果不能提升、不能收敛、超出算力,在构造时,每一层的隐藏层节点依次减半,实验效果如下图,可以看到随着深度的增加和特征的增加,效果逐渐变好。

线上预测
在进行线上预测时,因为时间和性能的限制,通过网络计算得到用户和上下文的向量后,不能对每个视频都计算softmax得分。
文章在训练时通过内积限制两个embedding在相同空间,对训练时得到的视频向量,选择了点积空间中的最近邻的近似评价方式,经过实验验证,实验效果对最近邻算法的选择并不敏感。
Note:
虽然跑一遍就可以得到每个视频的softmax得分,这样的时间复杂度还是过高,softmax逐个进行向量内积运算加排序,复杂度应该是nlogn级别的。但使用LSH这种ANN(Approximate Nearest Neighbo)的方法,建立索引后的复杂度甚至可以低到 logN甚至常数级别的。NN只是对argtop_k u'vj的近似,NN近似让人感觉u,v属于同一个space,但是u和v应该不是同一个空间,有点像rowspace和nullspace的关系。|u-v|^2=|u|^2+|v|^2-2u'v,可见u'v和NN还差了一项|v|^2,假设|v|^2是正态分布,可以按|v|^2分成3组做ANN近邻搜索,|v|^2,这样近似更精确。文章说k~几百,所以ANN非常快,k相对大(2k)的时候,很有可能还是u'V算起来更快。
新的视频可以不走这样的召回,通过其他方式分发给用户,然后根据用户的embedding去反推。。或者用双端模型,引入物品侧的特征,像用户端一样也训练一个nn结构,新的视频只要有特征就可以过nn结构embedding了
排序
排序部分模型架构整体上候选集生成部分类似,主要区别在于训练和预测的目标、设计的特征。
label和训练目标
文章在排序部分使用了期望的观看时长作为预测目标,没有采用点击率,因为点击率可能会把一些标题党等骗点击的视频推荐给用户。ranking模型通过加权的LR给每个视频都赋予了一个得分,根据得分的高低排序依次展示给用户。
在实际建模中,因为用到了LR,所以依然要设置正例和负例,文章将点击的视频当作正例,没有点击的视频当作负例,为了预测期望的观看时长,对正例赋予观看时长的权重,负例的权重均设成单位权重。
在线下训练时,依然采用了交叉熵作为损失函数,线上就直接通过参数点成计算,然后求以e为底,目标值为幂的值,刚好表示了期望时长。

特征工程
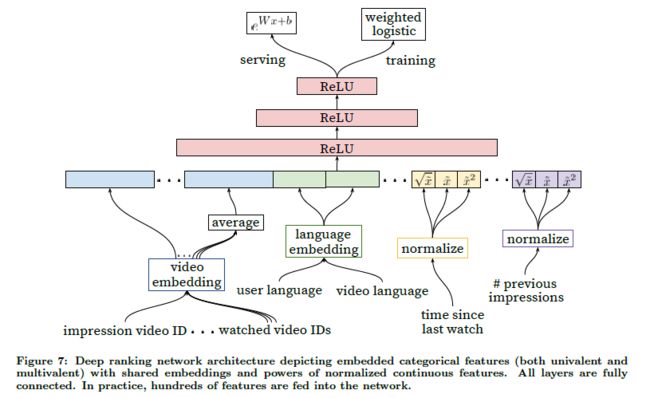
排序阶段相对于候选集生成阶段需要处理的视频数量大幅降低,可以使用更多的特征。主要包含的特征如结构图所示,其中要展示的video和看过的video时共享embedding的,用户的语言和视频的语言也是共享embedding的,其他的还包括视频的来源、视频在候选集生成阶段的得分、上次观看这个视频的时间、看过这个视频的次数等。
值得注意的有以下几点:
- 用户部分特征计算一次就可以,但是视频因为包含很多个,特征就需要计算几百次。
- 用户之前对该视频和该视频相关的频道、主题等的交互特征非常重要并且泛化性能很好,比如看过多少次、上次什么时候看的。
- 用户看过多少次这个特征可以防止总是给用户推荐这个视频。
- embedding的维度可以设置成id数目的对数个,很少出现的视频的embedding可以设置成全0,节省计算资源。
- 同类id共享embedding可以提升泛化性能,加速训练和节省计算资源。
- 过多使用序列信息可能会导致用户总是看到某一种视频,文章抛弃了序列性这一点,将历史信息打乱作为特征(当时应该是没有很好的掌握序列信息的使用方法,现在经过attention的使用已经克服了这样的缺陷)。
-
文中使用的标准化方法是采用了累积分布,并做了平方和开跟的非线性变化,增加模型的表达能力,在实验中也验证了做非线性变换的好处。

模型结构的实验
文章评价loss用的是正例被分错的观看时长占整体

其他内容
线下的指标往往和线上的情况不符,可以通过对点击率、观看时长等评价方式进行修改去近似判断用户是否满意。
预测目标是非常关键的,指明了大方向
参考资料:
https://research.google.com/pubs/archive/45530.pdf
https://zhuanlan.zhihu.com/p/52169807
https://zhuanlan.zhihu.com/p/52504407