奇偶校验码
奇偶校验通过在编码中增加一个校验位来使编码中的1的个数为奇数(奇校验)或者偶数(偶校验),从而使码距变为2.对于奇校验,它可以检测代码中奇数位出错的编码,但不能发现偶数位出错的情况。既当合法编码中奇数位出现错误。也就是1变成0或者0变成1,其编码的奇偶性就发生了变化,从而发现错误。但是这种校验只能发现出现了错误但是不知道具体是哪一位发生了错误。
各校验码校验的码位对照表

其中:p1,p2,p3,p4等是校验位
校验位所校验的字符位置计算方法举例:b9由p4, p3, p2进行校验:从左到右b9的位序是14, 14=8+4+2,因此用第8位的p4,第4位的p3和第2位的p2校验。同理可得其他校验位。
从表中可以得出以下两个规律:
- 所有校验码所在的位是只由对应的校验码进行校验,如第1位(只由p1校验)、第2位(只由p2校验)、第4位(只由p3校验)、第8位(只由p4校验)、第16位(只由p5校验),……。也就是这些位如果发生了差错,影响的只是对应的校验码的校验结果,不会影响其它校验码的校验结果。这点很重要,如果最终发现只是一个校验组中的校验结果不符,则直接可以知道是对应校验组中的校验码在传输过程中出现了差错。
- 所有信息码位均被至少两个校验码进行了校验,也就是至少校验了两次。查看对应的是哪两组校验结果不符,然后根据表5-2就可以很快确定是哪位信息码在传输过程中出了差错。
海明码校验的方式就是各校验码对它所校验的位组进行“异或运算”,即:
G1=p1⊕b1⊕b2⊕b4⊕b5⊕……
G2=p2⊕b1⊕b3⊕b4⊕b6⊕b7⊕b10⊕b11⊕……
G3= p3⊕b2⊕b3⊕b4⊕b8⊕b9⊕b10⊕b11⊕……
G4= p4⊕b5⊕b6⊕b7⊕b8⊕b9⊕b10⊕b11⊕……
G5= p5⊕b12⊕b13⊕b14⊕b15⊕b16⊕b17⊕b18⊕b19⊕b20⊕b21⊕b11⊕b23⊕b24⊕b25⊕b26⊕……
正常情况下(也就是整个码字不发生差错的情况下),在采用偶校验时,各校验组通过异或运算后的校验结果均应该是为0,也就是前面所说的G1、G2、G3、G4,……均为0,因为此时1为偶数个,进行异或运算后就是0;而采用奇校验时,各组校验结果均应是为1。
海明码的编码和校验方法
海明码(也叫汉明码)具有一位纠错能力。本文以1010110这个二进制数为例解释海明码的编码和校验方法。
确定校验码的位数x
设数据有n位,校验码有x位。则校验码一共有2x种取值方式。其中需要一种取值方式表示数据正确,剩下2x-1种取值方式表示有一位数据出错。因为编码后的二进制串有n+x位,因此x应该满足
2x-1 ≥ n+x
使不等式成立的x的最小值就是校验码的位数。在本例中,n=7,解得x=4。
确定校验码的位置
校验码在二进制串中的位置为2的整数幂。剩下的位置为数据。如图所示。

求出校验位的值
以求x2的值为例。为了直观,将表格中的位置用二进制表示。

为了求出x2,要使所有位置的第二位是1的数据(即形如**1*的位置的数据)的异或值为0。即x2^1^1^0^1^0 = 0。因此x2 = 1。
同理可得x1 = 0, x3 = 1, x4 = 0。

因此1010110的海明码为01110100110。
校验
假设位置为1011(加了校验码后的第11位)的数据由0变成了1,校验过程为:
将所有位置形如1, 1, 1, 1的数据分别异或(对应于刚才求的x1, x2, x3, x4校验位)
G1=0^1^0^0^1^1 = 1 (对应于x1校验位)
G2=1^1^1^0^1^1 = 1 (对应于X2校验位)
G3=1^0^1^0= 0 (对应于X3校验位)
G4=0^1^1^1 = 1 (对应于X4校验位)
以上四组中,如果一组异或值为1,说明该组中有数据出错了。*1 1 1的异或都为1,说明出错数据的位置为x1, x2, x4都能校验到这个错误,查看本文开头的那个表只有p1,p2,p4都能校验第11位,则出错的值就是1101(换算成十进制就是11)
哈夫曼编码的理解(Huffman Coding)
哈夫曼编码(Huffman Coding),又称霍夫曼编码,是一种编码方式,可变字长编码(VLC)的一种。Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就叫做Huffman编码(有时也称为霍夫曼编码)。
哈夫曼编码,主要目的是根据使用频率来最大化节省字符(编码)的存储空间。
简易的理解就是,假如我有A,B,C,D,E五个字符,出现的频率(即权值)分别为5,4,3,2,1,那么我们第一步先取两个最小权值作为左右子树构造一个新树,即取1,2构成新树,其结点为1+2=3,如图:
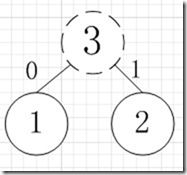
虚线为新生成的结点,第二步再把新生成的权值为3的结点放到剩下的集合中,所以集合变成{5,4,3,3},再根据第二步,取最小的两个权值构成新树,如图:

再依次建立哈夫曼树,如下图:

其中各个权值替换对应的字符即为下图:

所以各字符对应的编码为:A->11,B->10,C->00,D->011,E->010
霍夫曼编码是一种无前缀编码。解码时不会混淆。其主要应用在数据压缩,加密解密等场合。
如果左叶子节点都小于等于根节点和右叶子节点,可以把左分支路径都设置为0,右分支路径都设置为1;或者小的值设置为0,大的分支路径设置为1
如果考虑到进一步节省存储空间,就应该将出现概率大(占比多)的字符用尽量少的0-1进行编码,也就是更靠近根(节点少),这也就是最优二叉树-哈夫曼树。