不久前写过一篇使用Scrapy框架写的Crawlspider爬虫笔记(五)- 关于Scrapy 全站遍历Crawlspider,本次我再次沿用上次的网站实现全站爬虫,希望目标网址的小伙伴原谅我~~~
目标站点:www.cuiqingcai.com
代码已经上存到github下载
代码已经有详细的注释,这里附上流程图和部分代码解析~~
主要用到的库和技术
import urllib2
from collections import deque # deque是为了高效实现插入和删除操作的双向列表
import httplib
from lxml import etree
from pybloom import BloomFilter
- urllib2:伪造请求
- deque:双向列表,存储待下载的URL
- httplib:生成md5值
- BloomFilter:用于URL过滤
- etree:获取页面,结合xpath过滤页面中的URL
伪流程图
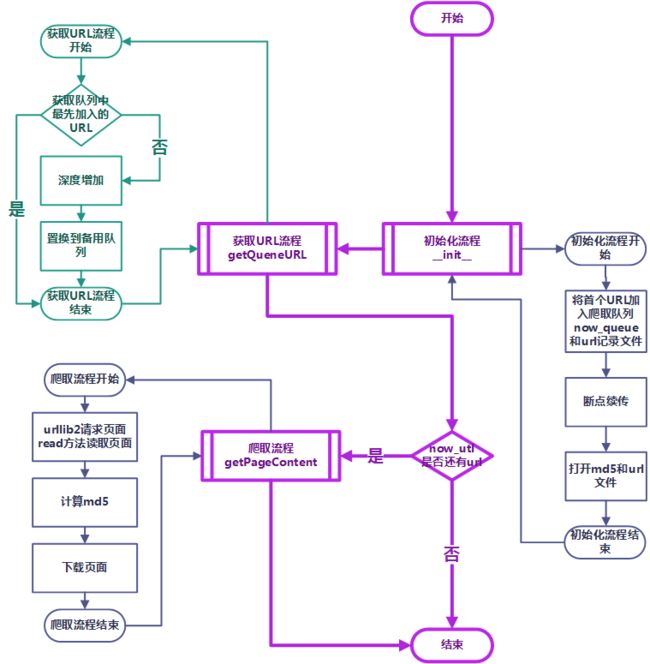
伪流程图
首先是紫色部分,就是主要流程:通过主流程来控制整个爬取的过程。
然后,主要流程里面有三个伪小流程【初始化流程__ini__】、【获取URL流程getqueneURL】和【爬取流程getPageContent】。
重点代码说明
【初始化流程__ini__】
- 断点续传逻辑:通过将下载过的md5和url记录到文件中的方式,在每次执行脚本前分析已记录的md5值的方式来实现断点续传
self.md5_file = open(self.md5_file_name, 'r') # 只读方式打开md5的文件
self.md5_lists = self.md5_file.readlines() # 将文件的内容以列表的方式读取出来
self.md5_file.close() # 关闭文件
for md5_item in self.md5_lists: # md5_item 的格式是"7e9229e7650b1f5b58c90773433ae2bc\r\n"
self.download_bf.add(md5_item[:-2]) # 将去掉回车换行符的md5写入BloomFilter对象当中
【获取URL流程getqueneURL】
- deque双向列表:通过popleft()高效读取URL爬取。(这里有个GIL锁,想了解可以自己深入了解下~~~)
# 用于记录爬取URL的队列(先进先出)
now_queue = deque() # 爬取队列
bak_queue = deque() # 备用队列(爬取队列为空的时候置换)
···
url = self.now_queue.popleft() # 从左边进行获取队列内容
- try except:队列为空的时候,增加深度&置换队列
try:
url = self.now_queue.popleft() # 从左边进行获取队列内容
return url
except IndexError:
self.now_level += 1 # 深度加一
if self.now_level == self.max_level: # 如果深度与设定的最大深度相等,停止爬虫返回None
return None
if len(self.bak_queue) == 0: # 如果备用队列长度为0,停止爬虫返回None
return None
self.now_queue = self.bak_queue # 将备用队列传递给爬取队列
self.bak_queue = deque() # 重置备用队列
return self.getQueneURL() # 继续执行dequeuUrl方法,直到获取到URL或者None
【爬取流程getPageContent】
- md5:__init__流程中的断点续传和过滤URL
# 计算md5的值并将md5和写入到文件中
dumd5 = hashlib.md5(now_url).hexdigest() # 生成md5值
self.md5_lists.append(dumd5) # 将md5加入到md5的列表中
self.md5_file.write(dumd5 + '\r\n') # 将md5写入文件
self.url_file.write(now_url + '\r\n') # 将url写入文件
self.download_bf.add(dumd5) # 将md5加入到BloomFilter对象当中
num_downloaded_pages += 1 # 用于统计当前下载页面的总数
- xpath:获取当前文件中所有的URL
html = etree.HTML(html_page.lower().decode('utf-8'))
hrefs = html.xpath(u"//a")
for href in hrefs:
# 用于处理xpath抓取到的href,获取有用的
try:
if 'href' in href.attrib:
val = href.attrib['href']
if val.find('javascript:') != -1: # 过滤掉类似"javascript:void(0)"
continue
if val.startswith('http://') is False: # 给"/mdd/calendar/"做拼接
if val.startswith('/'):
val = 'http://cuiqingcai.com/{0}'.format(val)
else:
continue
if val[-1] == '/': # 过滤掉末尾的/
val = val[0:-1]
- BloomFilter:过滤URL后入列
if hashlib.md5(val).hexdigest() not in self.download_bf:
self.bak_queue.append(val)
结果展示
(占位---待继续更新)
代码不够200行,这里附上所有代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
# @Time : 2017/6/9 19:23
# @Author : Spareribs
# @File : cuiqingcai_crawl.py
# @Notice : 这是使用宽度优先算法BSF实现的全站爬取的爬虫
详解1:我们已经将md5和URL记录到md5.txt和url.txt中,但是我们暂时不用url.txt,我们只需要将md5的值读取到用于做判断逻辑的BloomFilter对象当中即可
"""
import os
import time
import urllib2
from collections import deque # deque是为了高效实现插入和删除操作的双向列表
import httplib
import hashlib
from lxml import etree
from pybloom import BloomFilter
num_downloaded_pages = 0
class CuiQingCaiBSF():
"""
这是使用宽度优先算法BSF实现的全站爬取的爬虫类,通过max_level来自定义抓取的深度
"""
# 定义请求的头部(目标网站没有做太多的安全措施,所以原谅我)
request_headers = {
'user-agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.95 Safari/537.36",
}
# BSF宽度优先算法的深度标记
now_level = 0 # 初始深度
max_level = 2 # 爬取深度
# 记录文件(URL和计算得到的md5)
dir_name = 'cuiqingcai/'
if not os.path.exists(dir_name): # 检查用于存储网页文件夹是否存在,不存在则创建
os.makedirs(dir_name)
md5_file_name = dir_name + "md5.txt" # 记录已经下载的md5的值
url_file_name = dir_name + "url.txt" # 记录已经下载的URL
# 用于记录爬取URL的队列(先进先出)
now_queue = deque() # 爬取队列
bak_queue = deque() # 备用队列(爬取队列为空的时候置换)
# 定义一个BloomFilter对象,用于做URL去重使用
download_bf = BloomFilter(1024 * 1024 * 16, 0.01)
# 定义一个存放md5值的列表
md5_lists = []
def __init__(self, begin_url):
"""
初始化处理,主要是断点续传的逻辑
"""
self.root_url = begin_url # 将初始的URL传入
self.now_queue.append(begin_url) # 将首个URL加入爬取队列now_queue
self.url_file = open(self.url_file_name, 'a+') # 将首个url写入url记录文件
# 用于处理断点续传逻辑(详细请看-->详解一)
try:
self.md5_file = open(self.md5_file_name, 'r') # 只读方式打开md5的文件
self.md5_lists = self.md5_file.readlines() # 将文件的内容以列表的方式读取出来
self.md5_file.close() # 关闭文件
for md5_item in self.md5_lists: # md5_item 的格式是"7e9229e7650b1f5b58c90773433ae2bc\r\n"
self.download_bf.add(md5_item[:-2]) # 将去掉回车换行符的md5写入BloomFilter对象当中
except IOError:
print "【Error】{0} - File not found".format(self.md5_file_name)
finally:
self.md5_file = open(self.md5_file_name, 'a+') # 增加编辑方式打开md5的文件
# def enqueueUrl(self, url):
# self.bak_queue.append(url) # 将获取到的url加入到备用队列当中
def getQueneURL(self):
"""
爬取队列为空的时候,将备用队列置换到爬取队列
"""
try:
url = self.now_queue.popleft() # 从左边进行获取队列内容
return url
except IndexError:
self.now_level += 1 # 深度加一
if self.now_level == self.max_level: # 如果深度与设定的最大深度相等,停止爬虫返回None
return None
if len(self.bak_queue) == 0: # 如果备用队列长度为0,停止爬虫返回None
return None
self.now_queue = self.bak_queue # 将备用队列传递给爬取队列
self.bak_queue = deque() # 重置备用队列
return self.getQueneURL() # 继续执行dequeuUrl方法,直到获取到URL或者None
def getPageContent(self, now_url):
"""
下载当前爬取页面,
"""
global filename, num_downloaded_pages
print "【Download】正在下载网址 {0} 当前深度为{1}".format(now_url, self.now_level)
try:
# 使用urllib库请求now_url地址,将页面通过read方法读取下来
req = urllib2.Request(now_url, headers=self.request_headers)
response = urllib2.urlopen(req)
html_page = response.read()
filename = now_url[7:].replace('/', '_') # 处理URL信息,去掉"http://",将/替换成_
# 将获取到的页面写入到文件中
fo = open("{0}{1}.html".format(self.dir_name, filename), 'wb+')
fo.write(html_page)
fo.close()
# 处理各种异常情况
except urllib2.HTTPError, Arguments:
print "【Error】:{0}\n".format(Arguments)
return
except httplib.BadStatusLine:
print "【Error】:{0}\n".format('BadStatusLine')
return
except IOError:
print "【Error】:IOError {0}\n".format(filename)
return
except Exception, Arguments:
print "【Error】:{0}\n".format(Arguments)
return
# 计算md5的值并将md5和写入到文件中
dumd5 = hashlib.md5(now_url).hexdigest() # 生成md5值
self.md5_lists.append(dumd5) # 将md5加入到md5的列表中
self.md5_file.write(dumd5 + '\r\n') # 将md5写入文件
self.url_file.write(now_url + '\r\n') # 将url写入文件
self.download_bf.add(dumd5) # 将md5加入到BloomFilter对象当中
num_downloaded_pages += 1 # 用于统计当前下载页面的总数
# 解析页面,获取当前页面中所有的URL
try:
html = etree.HTML(html_page.lower().decode('utf-8'))
hrefs = html.xpath(u"//a")
for href in hrefs:
# 用于处理xpath抓取到的href,获取有用的
try:
if 'href' in href.attrib:
val = href.attrib['href']
if val.find('javascript:') != -1: # 过滤掉类似"javascript:void(0)"
continue
if val.startswith('http://') is False: # 给"/mdd/calendar/"做拼接
if val.startswith('/'):
val = 'http://cuiqingcai.com/{0}'.format(val)
else:
continue
if val[-1] == '/': # 过滤掉末尾的/
val = val[0:-1]
# 判断如果这个URL没有在BloomFilter中就加入BloomFilter的队列
if hashlib.md5(val).hexdigest() not in self.download_bf:
self.bak_queue.append(val)
else:
print '【Skip】已经爬取 {0} 跳过'.format(val)
except ValueError:
continue
except UnicodeDecodeError: # 处理utf-8编码无法解析的异常情况
pass
def start_crawl(self):
"""
启动脚本的主程序
"""
while True:
# time.sleep(10)
url = self.getQueneURL()
if url is None:
break
self.getPageContent(url)
print "爬取队列剩余URL数量为:{0},备用队列剩余URL数量为:{1}".format(len(self.now_queue), len(self.bak_queue))
# 最后关闭打开的md5和rul文件
self.md5_file.close()
self.url_file.close()
if __name__ == "__main__":
print '【Begin】---------------------------------------------------------------'
start_time = time.time()
CuiQingCaiBSF("http://cuiqingcai.com/").start_crawl()
print '【End】下载了 {0} 个页面,花费时间 {1:.2f} 秒'.format(num_downloaded_pages, time.time() - start_time)
以上都是我的个人观点,如果有不对,或者有更好的方法,欢迎留言指正~~~