导语:系列一搞定异常发现后,就轮到异常定位了。所谓异常定位,就是找到异常发生处,比如异常是发生在哪个模块或哪行代码。目前笔者在FinTech领域供职,身临BigData场景,本文将介绍BigData下app异常定位的设计思路和解决方案,以及业内比较、如何开放、系统能力评估。

1、技术难点:跳入大数据的坑
单个异常的定位并不难,比如通过app端回传的异常栈一眼就能定位crash在哪。但笔者在FinTech领域供职,所在部门要接入最多上千个金融类app,和所有BigData场景一样,本来看似简单的问题将变得极端复杂,难点包括:
数据维度/灵活性:一开始,我们设计以app模块为服务治理单元,不久便发现各个app对异常定位的要求并不相同,上至整个app,下至单个页面元素,比如A要求模块级别的定位,B要求页面级别的定位,这要求对上千家app各种维度的数据进行分析。
实效性:金融行业有很高的止损诉求(毕竟关系到钱),很多核心服务的治理是要实时的,尤其实时发现和定位异常,而在高并发大流量场景下做实时具有很大挑战性。
实时一般指低延迟,是个相对的概念。由于异步架构和网络开销,本文系统核心的实时能力在s级,这在我们业务范围内已经足够。当然,对于少部分延迟要求极低的服务,可以单独做到更低延迟,但过于定制化,不是本文重点
- 跨平台:为了实现app服务治理,要采集分析app端和服务端的数据,里面会包含各种DSL定义的接口数据
需要强调一点,我们优先解决的是规模问题,至于BigData领域的弹性计算,全权交给了公司的云服务。
2、设计思路:单调到灵活
近几个月,我们经历了3个阶段。
阶段1:单维度模式。最初,以app模块为服务治理单元,对数据源的每条数据流格式要求很简单,只需包含模块名和该模块数据,我们称之为单维度模式。这种模式简单,但单调,因为只能分析以模块为维度的数据。
阶段2:多维度模式。不久,我们发现服务治理单元远不止app模块,理论上所有维度都能充当治理单元,这就要求兼容各个维度甚至是服务端api维度的数据。为此,我们调整了数据流格式,包含4个必选项appId、os、appVersion、dataType和其他可选项,其中data可用来传递任意数据项,实现数据维度的无限扩展,我们称之为多维度模式。该阶段最关键是制定了一套通用数据源格式标准,相比于单维度模式,这套标准能轻松扩展到任意类型的异常定位,进而扩展到任意维度的服务治理。
* @param appId app唯一标示,必选
* @param os 操作系统,必选
* @param appVersion app版本号,必选
* @param dataType 数据类型,对应策略名,用来指定使用哪个策略,必选
* @param osVersion 操作系统版本号,可选
* @param deviceId 设备号,可选
* @param deviceName 设备名,可选
* @param channel 渠道号,可选
* @param location 位置,可选
* @param ip ip号码,可选
* @param mobilePhone 手机号,可选
* @param networkEnv 网络环境类型,可选
* @param telecomOperator 基础运营商名称,可选
* @param time 数据发生时间,后台可根据数据类型的不同,选择性信任此参数,可选
* @param userAgent 用户代理类型UA,可选
* @param screenSize 屏幕大小,可选
* @param data 数据详情,可选
阶段3:DSL。多维度模式只是统一了数据源,我们还需要对原始数据进行分析,转化成知识,这些知识告诉我们什么时候出了异常(异常发现)、异常在哪里(异常定位)。面对多维度数据多场景化,系统的分析能力必须足够灵活,能覆盖任意异常的分析,归根结底,就是要实现条件可定义。条件可定义的意思是针对任意类型异常,都能设置一个条件,当数据流满足该条件时,就意味着此类型异常发生并能进行定位。虽然策略平台早在单维度模式阶段就能通过配置策略来定义条件,但比较粗糙,为了更灵活定义条件,策略平台引入了DSL对条件进行表达。
为何叫
条件可定义而非异常可定义,是因为策略平台不单单用于异常发现和定位,还能用于数据统计,即能够定义当满足何种条件时就统计何种数据。而且,不单能统计移动端(类似Google Analytics、TalkingData),还可以统计服务端(比如api统计)
3、解决方案:SQL on jstorm
3.1、具体异常定位实例
假设有一个iOS应用,应用ID为100,要为该app的一个abc模块设置crash监控,要求如果一个小时内crash数目>100,就向abc维护者发送监控报警邮件。
我们的系统是如何定义一条策略来表达上面的crash监控需求?
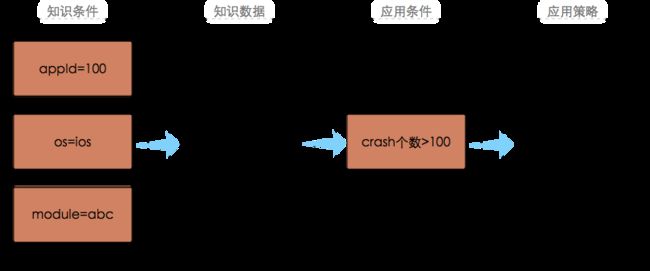
如上图所示,我们先配置3个知识条件,表示当数据流符合appId=100、os=ios、module=abc时,将产生一个知识数据,这个知识数据就是应用的abc模块在最近一小时内累积的crash个数。每来一个符合这3个知识条件的原始数据流,该知识数据就变化一次,即crash个数就增1。该知识数据(crash个数)将在redis中保留1个小时。接着,我们又配置了1个应用条件,表示一旦知识数据符合该条件(crash个数>100),则触发应用策略(发送报警邮件)。除了可以设置触发何种应用策略外,我们还能设置符合应用条件时是否将知识数据进行持久化,这可用来做数据统计,用在本节实例身上,就是可以统计abc模块每小时的crash个数。
总结起来,配置一个策略其实主要就是配置一系列条件,这个过程分为两部分:1)先配置N个知识条件,当实时数据流满足这N个条件,就产生相应的知识数据;2)再配置1个应用条件,当知识数据满足该条件,则启动相应的应用策略或持久化。
3.2、整体架构
本节,我们对策略平台整体架构做一个讲解。
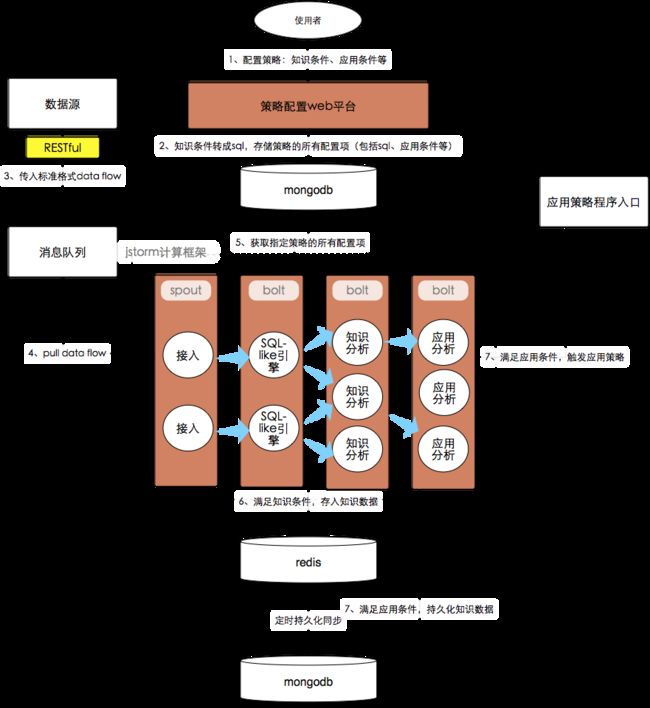
首先,使用者要在策略平台配置策略,包括配置N个知识条件和1个应用条件。
接着,策略平台把知识条件转成一条sql。如上文所述,我们使用DSL来表达条件,而常见的DSL或结构化格式包括sql、json、xml等,我们最终选择sql,理由见下文。然后,将策略的所有配置项存入mongoDB,除了知识条件sql和应用条件外,其他配置项还包括策略名、描述、知识缓存时间等基本信息。
一旦有数据产生,数据源需按照标准格式把数据传给策略平台,即必须包含appId、os、appVersion、dataType。dataType是策略名,用来指定本次数据使用哪个策略来处理。数据流先到消息队列排队,再由jstorm异步拉取。对于那些延迟要求极低的核心服务,数据源的数据将直达jstorm,不在消息队列排队。
jstorm拉取到数据流后,SQL-like引擎先根据dataType取出对应的策略,解析策略中的sql,得到程序可识别的结构化知识条件,再把策略和数据流传给第2个bolt。第2个bolt中,知识分析模块分析数据流,如果数据流符合知识条件,则产生相应的知识数据,然后使用inc或set命令把新的知识数据存入redis,并把新知识数据传给第3个bolt。第3个bolt中,应用分析模块对新知识数据进行分析,如果知识数据符合策略中的应用条件,则触发应用策略或知识数据持久化。
为了区别于狭义上的数据库sql,这里用了SQL-like
如果知识数据设置为可持久化,则需要定时将该知识数据从redis中不断同步进mongoDB。如果没有定时同步,只依靠数据流来触发持久化,一旦redis重启或redis过期时间到来之前没有数据流,知识数据将会丢失
3.3、系统核心
策略平台的核心支撑技术是sql on jstorm,本质上是一种SQL-like引擎(或QueryEngine)+计算框架组合,这样的组合业内并不陌生,比如hive on spark/hadoop、Greenplum等。
在大数据领域,计算框架基本算是标配,它们可以充分利用集群资源提升系统的计算能力,虽然单机性能有所损耗。对计算框架的选型,由于实时性要求以及社区活跃度,我们选择了流式计算框架jstorm。
SQL-like引擎最大作用是提供通用简单的sql语法,完成复杂查询和数据分析,一般用于数据仓库。业内有不少成熟的SQL-like引擎和工具,比如hive hql、spark sql 、wing等,但策略平台的特殊性,接入现有工具的改造成本太大,于是我们定制化了自己的轻量级SQL-like引擎。
有人说知识条件并不复杂,用简单的json就能表达,无需sql,更没必要单独做了一个SQL-like引擎,而我们之所以这么做,理由包括:
- sql具有更直接明了的查询表达能力,学习成本也低,还能做查询优化
- SQL-like在大数据领域很普遍,如果我们的SQL-like引擎无法适应未来的发展,可以小成本迁移业内成熟方案
- 作为一个独立的无状态组件,升级和扩容缩容的风险变小
- 基于开源库解析sql,开发成本不大
SQL-like引擎的设计借鉴了数据仓库概念,比如知识条件相当于维度(Dimention)、知识相当于事实(Fact)。我们支持的sql语法如下:
select 知识类型 from 策略名 where 知识条件
// 支持的知识类型包括不限于:
// 数据流中任意一个field:语法是field,可用于慢请求定位等
// 总数:语法是count(),可用于crash定位、流量控制、pv统计等
// 指定field的累加和:语法是sum(field),可用于累积流量统计等
// 拿3.1实例来说,就是select count() from crashMonitor where appId=100 and os=ios and module=abc
SQL-like引擎依赖JSqlParser完成词法分析、语法分析、ast树生成,对于一条简单sql,JSqlParser大概耗时30ms,为了提升性能,可以将解析好的sql条件存入local缓存。SQL-like引擎定制化了自己的逻辑查询计划和物理查询计划,未来再展开讲。
4、业内比较
Sensors Data创始人对典型的数据流做了个总结,如图3。如果我们把持久化数据进行可视化,就和图3差不多了,这解释了我们和业内的相似之处,那区别在哪?
- 目标不同:我们要实现app服务治理,业内没有成熟方案
- 手段不同:app服务治理分为知识和应用两个阶段。知识阶段对增量数据(实时数据流)和存量数据(redis中的知识数据)做整合分析,而业内一般对存量数据(全量原始数据)做分析,也正由于知识数据量远比原始数据量小,因此可以做到s级低延迟。而应用阶段依赖知识数据做任意应用,比如异常解决,应用和业务强相关,业务在业内不一样,应用也就不一样。
整个过程中,分析(或训练)的数据都拥有分类标记,分析结果是对异常的预测,算是一种简单的有监督机器学习。
不过,如果未来需要用到离线的原始数据做治理,如何解决?这已经涉及到传统的数据仓库OLAP甚至是data mining了,需求极度灵活,往往要用到任意原始数据项和任意时间点的数据。但我们目前更关注实时治理而非事后离线分析,况且原始数据存储还有容量问题,要考虑引入Protobuf压缩等方案,因此只是暂时缓存了3个月的原始数据,以备不时之需。
5、如何开放
虽然开放和异常定位没有直接关系,但app服务治理的使用者是上千个金融类app的维护者,所以一开始设计就要考虑如何开放,实现Strategy-as-a-Service。要实现开放,以下事情很重要。
- 接入数据:提供统一接口,使用者按照标准格式传递数据到策略平台
- 配置策略:提供统一的操作页面
- 反馈:提供统一的可视化图表,查看持久化数据和应用策略命中情况
6、系统能力评估
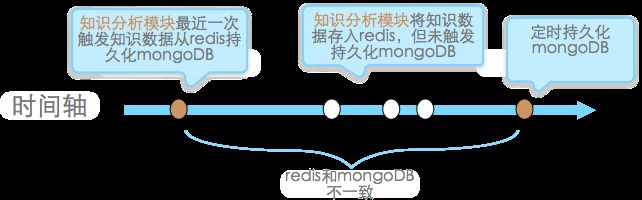
首先,套用CAP原理来评估,即一致性和高可用间的权衡。一般来说,有状态组件(比如redis和mongodb)是不一致问题之源,从图2得知,知识数据要从redis向mongoDB持久化,只能由知识分析模块或定时任务触发,而图4场景中redis和mongoDB会有一段时间的不一致,我们无法做到强一致性,只能通过定时任务保证最终一致性,但定时任务会使很多数据在同一时间从redis中清除和写mongoDB,降低了可用性。然而,为了追求某些场景的效率又偏向了可用性,比如我们将把sql解析结果缓存本地cache,修改sql后要同步所有机器清除本地cache,这里容忍同步期间的不一致。此外可用性方面,redis和mongDB都主从备,纳入HA(High available)系统,仅jstorm Nimbus是单点。
接着是性能。先是消息队列中间件,一般考察TPS。通过Jason's Blog看到,kafka在3台4核虚拟机broker下,如果数据流传递了策略平台所有数据项,即按100字节算,将达到330w records/s和322MB/s,而redis pub/sub benchmark表明单机tps在几十万。
再来分析一下jstorm内组件的性能,重点考察TRT。假设命中的策略只设置了一个知识条件,按图2的数据流,一次数据流请求最多包含apout和bolt间3次网络消耗、3个bolt的逻辑处理耗时、读写mongoDB各1次、读写redis各1次、1次解析sql、1次http/dubbo应用请求,大概50~200ms。
事实上,生产环境的情况更复杂,因为可能不会触发写mongoDB和http/dubbo请求、一个策略包含多个
知识条件等等,更详实的压测结果以后有机会再写。