这个学期旁听了统数学院的三门课:马景义老师的[数据挖掘],刘苗老师的[时间序列分析],李丰老师的[统计计算]。
我以前说,没有数学的日子里,我的生活中只剩下了鄙视链和毒鸡汤,无法进行深层次的思考。现在上了三个月的课,仍是十分赞同这句话。三个月来,在数据科学这个行业里摸爬滚打,算是有不少收获,在这里写一些随想吧。全文的结构是:
- 数据挖掘
- 关于这门课程的收获
- 关于数据科学与经济学
- 关于数据挖掘实战
- 关于测试误差和科学哲学
- 关于今后的努力方向
- 时间序列
- 统计计算
- 结语
数据挖掘
关于这门课程的收获
遇到马老师是一件值得感激的事情,一位很棒的带领我走进数据科学行业的领路人。
这门课主要是介绍机器学习里的一些基本算法(目前已经教的回归算法有逐步回归、岭回归和lasso/lars,分类算法有分类树、随机森林、bagging trees和AdaBoost trees等)和一些重要的概念(交叉验证、训练集和测试集、bootstrap、boosting、ensemble methods、bias-variance分解等),重点不在于介绍很多的算法,而在于深入了解每个算法背后的思想和数学原理,所以每次上课都是用马老师自己写的R代码,而不是调用R里面现有的算法包。
上课用的参考书是斯坦福大学的Hastie教授的《An Introduction to Statistical Learning》,(但是课上基本没怎么提这本书,因为里面几乎不提数学原理,着重在思想,而课上主要是讲马老师这十多年来在数据科学行业的一些钻研的收获,各种推导公式和算法优化都是他自己原创的想法,在书上找不到,这也是我非常感激这门课的原因之一),毫无疑问是一本深入浅出、高屋建瓴的大师之作, 用简洁明了的语言阐明各种算法和概念的思想与本质,读来有醍醐灌顶之感,排版和画图也十分美观、清晰。

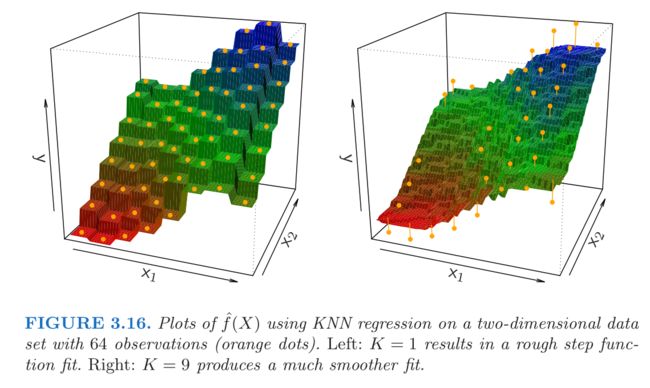
印象很深刻的是在介绍过度拟合(overfitting)的时候,说了这么一句:
When a given method yields a small training MSE but a large test MSE, we are said to be overfitting the data. This happens because our statistical learning procedure is working too hard to find patterns in the training data, and may be picking up some patterns that are just caused by random chance rather than by true properties of the unknown function f.
讲的非常生动清楚,对于理解测试误差和训练误差的不同之处也很有帮助。我觉得,ISLR是本很适合自学的书。
这门课的代码实现是用R语言,和python一样是解释型语言,很好上手。我之前接触过一段时间的python,觉得代码相当简洁,开始学习R之后,发现R比python还要简洁,甚至简洁得过分。
predictt <- function(tx) LETTERS[which.max(summary(unlist(lapply(TREE,predictt0,tx))))]
cl <- makeCluster(getOption("cl.cores", 3))
pre <- parApply(cl,TX,1,predictt)
这是课上的一段代码,短短三行,调用了很多的函数,都浓缩到一块儿去了。当然,写得简洁,运行起来速度就慢了不少,不像C语言和C++,虽然写得多,但运行起来快得很。老师在课上说:“别小看这三行代码,可把计算机给累坏了”。
虽然接触R语言的时间不长,但是我自觉进步很快,我这才意识到我之前在Coursera上学的python课程是多么的水,既没有学到干货,也没有掌握基本的学习模式/体系。现在虽然不敢说有很强的写代码能力,但至少掌握了如何学习R,学习python,即便离开了老师离开了课堂,也能够自己完整地学下去。

一开始上这门课是很吃力的,一个原因是我没什么写代码的基础,另一个是我的微积分/线性代数/概率论与数理统计掌握得不够扎实。老师上课的时候总爱说“我这一段讲清楚了吗?” “你们听明白了吗?”,每当他说这么一句时,我就意识到,我又有一个知识点没有掌握。。(捂脸)
上课的时候,跟不上老师的进度,总有一种“老师正在高速驾驶着汽车,车尾挂着一条绳子,绑住我的双手,拖着我往前”的感觉,我一路颠沛,在地上打着滚,被强行拖向前。。
好在情况有了好转,逐渐熟悉了机器学习之后,有渐入佳境之感。生活进入到了一种很纯粹的状态:基础不好,那就多投入一些时间呗,第一遍没看懂,那就多看几遍呗,勤能补拙,simple life。渐渐地,我能够理解代码,能够把代码和背后对应的思想联系起来。
老师说过一句对我触动很大的话,“要判断你有没有看懂我的代码,其实很简单,你把我的代码关了,自己创建一个空白文档,从零开始写起,你要是写出来了,运行没出错,得到了和我一样的运行结果,这就说明你看明白了,也说明你的写代码能力过关了。” 这话像是鸡血,我立刻行动起来,花了几个小时把逐步回归(stepwise regression)给重构了出来。
这一经历给了我很大的信心,虽然写的时候各种error各种报错,但至少,我独立地检查了错误排除了bug,最终实现了算法。在此之后,我认识到我的代码能力其实并不差,它就实打实地摆在那儿,毕竟能力不足的话是写不出来的。我甚至发现了老师的原代码里的可以改进的地方,里面有一层不必要的赋值计算,有几个不必要存在的变量,徒增复杂,我去了这几个变量,删了那几行代码,对flag这个向量进行修改,用最后一个位置记录常数项,永不变动,前面的位置用来记录自变量是进入还是退出,用FLASE和TRUE进行切换。最后实现的效果是一样的,但是代码更为简洁。
很是兴奋,跑去和老师分享。他先是赞赏了我的做法,然后问我有没有试着模拟一套数据去测试算法。我当时没太明白,后来才慢慢意识到,我这几行代码的修改其实无足轻重,真正重要的算法优化,要么是大幅度缩短了运算时间,要么是大幅度提升了预测精度。
Anyway,这次重构代码是不错的尝试,而且也让我认识到了这门数据挖掘课和网络上的那些培训课的区别。其实逐步回归在R里面调用现成函数只需要两行代码就能实现了:
lm1 = lm(formula = lpsa~.,data)
step(lm1, direction="both")
实现相同的效果,自己却写了一百五十多行,其实是在锻炼自己运用数学独立解决问题的能力。
随着课程的进行,我开始思考两个大问题:
- 为什么叫做机器学习?和人类学习有什么区别和联系?机器能够学到什么?为什么OLS回归这么简单的方法也算是机器学习?
- 数据科学行业的从业者的核心竞争力是什么?是代码能力?统计能力?还是业务场景的insight能力?老师所说的“你需要比那些只会调用R里面现成的函数/工具的人更厉害,能适应和解决更多更复杂的问题,才具有竞争力”究竟是什么意思?
第一个问题,在读了豆瓣上偶然遇到的《Hands-On Machine Learning with Scikit-Learn and TensorFlow》之后基本上想明白了。书中对机器学习下了个定义:
A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
—Tom Mitchell, 1997
机器通过算法从数据中学到了数据之间的内在相互关联,挖掘出了我们不容易发现的信息。用考试作比方的话,考试成绩用MSE/RMSE/MAPE等指标来衡量,给的数据越多,机器学到的知识也就越多,考试成绩也就越好(预测精度越高)。一个具体的例子的是,Califonia Housing这个数据集,当前任务是,给定某地区的人口、人均收入、房屋大小、房间数量、房屋使用年限等信息,让机器预测该地区的房价,机器从数据中学到知识的方法(算法)有很多种,有简单的算法(OLS),也有复杂些的算法(Lasso),方法越好,学习的效率越高(这和人类很像),而且,另外一个和人类学习相似之处在于,学得越多(数据量越大),能力越强(测试集误差越小),不过对人类来说这种单调性可能没这么明显。
至于第二个问题,我现在还没有想清楚,大概需要到互联网公司里实战才能够有更深的体会。我原本认为,只有统计和计算机知识是不够的,毕竟算法和算法实现只是你的一种工具,是你实现目标的途径而已,你还需要对业务、对应用场景、对专业知识、对context有足够深入的洞见。但是,在读了Hastie教授的另外一本教材《The Elements of Statistical Learning》(很著名的一本书,ISLR的深入拓展,写得非常好,培养了一大批数据科学家)之后,我发现我的这个想法似乎还比较稚嫩。
In data mining applications, usually only a small fraction of the large number of predictor variables that have been included in the analysis are actually relevant to prediction. Also, unlike many applications such as pattern recognition, there is seldom reliable domain knowledge to help create especially relevant features and/or filter out the irrelevant ones, the inclusion of which dramatically degrades the performance of many methods.
希望以后有了更多的体会之后,能够好好地回答这个问题吧。
说回到数据挖掘这门课。马老师实在是我很敬佩的一位老师,他的统计知识、对数据结构和计算机的认识、编写代码的能力,都远远在我之上,思维极为敏捷顺畅,表达能力很好,人也很谦逊、风趣,(而且很擅长记住学生的名字)。
最开始的时候,我是怀着敬畏之心的,轻易不敢去问他问题,因为我提的问题都太幼稚了,没什么技术含量。后来逐渐混熟了,我说我是经济学院的,是来旁听的,他就用这个去调侃选修这门课的应用统计和信息计算科学专业的同学:“你们看,廖致君他是学经济学的,以前没怎么接触过编程,他都看懂了我的代码,你们没理由看不懂啊”。和老师打好关系还是有好处,前几天邀请我加入了他和其他几位同学组成的团队,团队当前的目标是以R为主,C++为辅去改进现有的Elastic Net的算法,希望封装成一个package,上传到CRAN上面开源,给全世界的同行使用,比起当前现有的package要大幅度缩短计算时间。我觉得这是个很酷的项目,虽然不会C++,但是希望从别的方面给团队做一些贡献吧。老师说,学经济的和学统计/计算机的思考问题的角度很不相同,能给团队带来不一样的贡献。但愿如此。
我写代码有个习惯,就是先在草稿本上写写画画,把大致的逻辑框架给想清楚,借助草图把变量之间的依附关系和细节弄明白,然后才开始在电脑上敲代码。后来老师在课上说,就应该这么做,别一上来就对着电脑干想。原以为是我这个初学者的坏习惯,却得到了敬佩的老师的认可。微妙的幸福感。
当然,人无完人,老师也有缺点,其中之一就是代码的可读性差(老师自己也承认),变量命名不清楚,排版太拥挤。他要是没有在课上给你讲明白他的思想和实现方法,你直接去读他的代码,会相当吃力,因为你根本不知道某个变量究竟是什么意思。。
贴一些他课上说的话吧,挺有意思。
- 给我们讲怎么运用数学:
数学进入到代码中的时候,别把计算公式给放进去,把你要实现的效果和最核心的思想给放进去。
- 一句让我回味了很久的话:
求1+2+3+…+100的结果。
搞计算机的写了一个for循环,搞统计的写了个公式(n+1)*n/2
- 对data science的看法:
什么是数据科学家?搞统计的里面编程能力最强的那些人,或者搞计算机的里面统计能力最强的那些人。
- 强调要自己动手写代码,不要只停留在看懂一段代码上面,给我们打了个比方:
你去看一场电影,当时很兴奋,印象很深刻,但是过了很久以后,你会遗忘电影里的内容和细节,但如果你拍摄了一部电影,你会对这部电影记忆极其深刻,你知道每个道具、每个布景、每个视角、每段剧情,这段记忆无法磨灭。
- 介绍随机森林的时候:
随机森林是一个技惊四座的算法,不仅计算量小,预测精度还提高了。
- 上课时常常强调算法的优化:
你得非常爱惜你的计算机,心疼它,舍不得让它跑那么大的运算量,才能够不断写出更优秀的算法
关于数据科学与经济学
我是十分喜欢数据科学这个学科的,每天都充满干劲地去学,学一个新的算法、新的概念、新的package,都能给我带来巨大的快乐和新鲜感。写代码的时候,兴奋而投入,常常是在电脑前专注地思考,洗手间都没去过,一眨眼就是两三个小时。看python的document,看CRAN上的专题,看CSDN上的算法,充满了对未知领域的好奇和渴望,每天都期待着能够学到更多更有用的知识。热衷开源,热衷交流,热衷分享,也是我喜欢这个行业的原因。
直到今年三月份之前,我的申请计划专业都是美国的商业分析(business analytics),简单地说它是statistics/business/coding三者的交互,是个交叉学科,我认为比较适合我,那时的我还没怎么了解machine learning。三个月过去了,我意识到我还是更喜欢技术,喜欢偏tech的方向,BA大概满足不了我,所以我的目标变为了data science。我还不能准确地量化我从经济学本科转到data science硕士的难度,而且我也没查到和我相似的案例。不过,我查了一些学校的项目和对应课程,发现其实它们所教授的内容也没那么高深困难。前几天,上了哈佛的master-of-science-in-data-science项目官网,去了
至于经济学,我在四月中旬的时候做了一个重要的决定,我对经济学重新进行了定位:
对我而言,经济学可以当作是一种闲暇的兴趣爱好,像钓鱼、登山那样的陶冶情怀、荡涤世俗势利的爱好,闲来感兴趣读读即可,不求甚解,不求成果,只求获取灵感、转化思维、活跃大脑,却不可拿来当作事业,要求我去研读经典著作、体会大师的思想意识、深入思考经济现象并得出有洞见的观点和给出有力合理的解释,或是给我设置考题考察我对「经济学」的理解,就像是村上春树本人喜欢跑步,却非常厌恶在学校里老师的强制锻炼“快,都给我跑动起来”一般。
那么,我在经济学院的这三年是不是白读了呢?我觉得,经济学是一个十分重要的、大家都绕不开的基础学科,即便我最初大一时念的是计算机或者应用统计,我也还是需要去学习经济学的有关知识,这一条路径,始终是要走的。问题在于,数据科学比起经济学更适合自学,对于经济学,还是需要有大师级别的人物(对此我感谢斌开和川川,非常优秀的导师),带你走进经济学的世界,培养你的经济学直觉,一些系统的训练必不可少,经济学审美的形成尤为重要(使你能够判断,谁是在给出深刻的洞见,谁又是在瞎扯淡,搞一套毫无意义的、障人眼目的数学模型),好的经济理论一定要有被现实证伪的可能。
我曾经总结过这么两种不懂经济学的人:一种是不懂数学,逻辑里存在着明显的错误和矛盾;另一种是只懂数学,不知道经济现象背后的本质,忽略人类之间的交互,造出了华丽而无意义的数学模型。
2016年秋天,上交的陆铭教授来我们学校办了场讲座,讲的是中国的大城市问题,给我触动很大。主要观点是北京/上海这样的城市不是太大了,而是太小了。初听可能难以接受,但是了解了背后的逻辑之后,你又会对这一点深信不疑。你会认同他所说的关于集聚的优势,关于供给和需求的对立统一。这场讲座过后,我意识到经济学其实是常识,同时它也让我从此爱上了听经济学大家的学术报告。
经济学是困难的,困难在于,你不能明确地说出你掌握了某项知识,看清楚了某个经济现象。数据科学则不然,你把公式推导理清楚,自己动手写代码实现,在测试集上得到不错的分数,这便是明白了。而且,对经济学而言,要想说服别人你的理论正确,既要费很多口舌,又要拿出很多的证据(许多经济学家的口才都很好,“所有人都喜欢和弗里德曼辩论,尤其是弗里德曼不在的时候”)。数据科学则简单些,交叉验证的误差大小就摆在那儿,你的算法好不好,一看便知。
我喜欢经济学中对于中国现实问题的讨论和思考“国有企业的预算软约束问题如何解决?” “中国的经济开发区众多,为什么成功,又为什么失败?” “户籍制度和土地指标改革的联动是否可行?”等,不喜欢太方法论太抽象的问题 “经济学是不是一门科学?” “怎么看待经济学中大量运用数学?” “怎么看待经济理论中的模型假设?”等。
因果识别是经济学中极为重要的内容。而在机器学习里,是不涉及到因果推断的。真正严格意义上的因果关系的定义,来自于Rubin的potential outcome framework。举一例子,你今年高一,报了一个学习辅导班,想提高数学成绩,而在平行时空里,有一个一模一样的你和一个一模一样的世界,在那个时空里,你没有报学习辅导班。到了期末,你们在各自的世界中参加数学考试,用你的成绩减去平行时空里你的成绩,得到的差值,便是参加学习辅导班和提高数学成绩之间的因果关系。

从本质上说,因果识别是一个数据缺失问题,因为你观察不到平行时空。对此的解决方法是,找到一个各方面都和你非常非常相似相近的人,他没有报辅导班,看你们的成绩对比。只有你们两个人可能不够,得尽量找更多的相似的人,取个平均,这样得出来的因果关系更稳健。计量经济学中使用的randomized experiment,difference-in-difference,regression discontinuity等方法,目的都是在做这种近似。讨论因果识别,不可避免地要去讨论内生性问题。
Hastie在书里介绍,机器学习的算法模型存在着Prediction Accuracy和Model Interpretability之间的trade-off,这里说的interpretability不是变量之间的因果关系,而是指是否方便你向老板汇报模型的结果,方便你向路人介绍你的算法的故事。
机器学习以预测为目标,从这种意义上说,它比经济学要简单,因为预测结果是清晰可见的,测试误差就摆在那儿,不管你使用什么方法,不管多么扯淡,只要能把误差给降低就行(Hastie管这种算法叫做black box method),而要在经济现象中建立一条严密的因果推导链条,需要花费更多的精力,搜集更多的证据。
噢对了,经济学家如何在科技公司求职?是一篇对我决定转行影响很大的文章,每次读都有新的感悟,推荐给大家。
关于数据挖掘实战
四月中旬的时候,我报名参加了银联商务举办的一个数据挖掘比赛,是一个分类问题,根据用户的基本资料和信贷记录,判断他是否会有信贷违约问题(0-1变量)。那时才刚接触数据挖掘不久,很多知识都还不懂,precision和recall不懂,随机森林不懂,权当是重在参与了。参加比赛最大的体会是,我意识到,有一项在现实生活中非常重要,但是课堂上又没有教授的技术:缺失值填补。
数据挖掘界里有两句常用的行话:
- 数据和特征决定了机器学习的上限,而模型和算法只是在逼近这个上限
- garbage in,garbage out
现在越发赞同和认可这两句话。
前几天又报名参加了kaggle的一个比赛(原本想参加天池的比赛,但是发现没有合适的赛题),数据量挺大,估计我的笔记本带不动。。anyway,希望这次好好做吧。
关于测试误差和科学哲学
我们在谈论算法的误差的时候,我们谈论的是测试误差,而不是训练误差,因为后者往往会有过度拟合的问题,给出的结果往往过于乐观。数据是宝贵的,容不得浪费,所以有了交叉验证的思想。我们训练出一套模型,得到了不错的交叉验证分数,我们希望,这套模型用到最新的,未知的数据上面时,也能够有较好的表现。这其中,隐含了一层假设:新的数据和我们评价模型时用的数据,是相似的,是可以类比的。类似地,计量经济学中常常谈论内部有效性和外部有效性,说的是一个在当地有效的政策/项目,推广到别的地方,是否还能有相同的效果。这二者实际上都是在用一种归纳法的思想,都是从已知到未知,从有限到无限。我们无法穷尽所有的可能性,所以我们需要使用外推的方法。我们的算法在已有数据上表现良好,在新的数据上表现会如何呢?直到数据被采集,验证之前,我们都不知道问题的答案。
科学哲学中,大卫·休谟提出过一个概念,自然的齐一性,说的是我们未检验过的物体将在某些相关的方面与我们已经检验过的同类物体相似。我们很容易发现,宇宙不是齐一的,并且宇宙每天都在任意地改变。即便如此,在时间间隔较短的条件下,我们有理由相信,齐一性是存在的。以上面提到的银联商务的比赛为例,主办方要求我们训练出一套模型,就是为了把模型推广应用出去,预测和防范个人信贷欺诈,从而降低不良贷款率。在时间跨度不大的情况下,这个目标是可以实现的,而时间长了,信贷市场上千变万化,模型的性能自然也就下降了。我把这称为模型的时效性。
横截面数据的预测已然困难,时间序列的预测则更使人畏惧。世界瞬息万变,可能毫无征兆地便暴发一次冲击(回想历次金融危机)。
世界不是平稳的。这便是为什么Hastie会在书的首页引用这么一句话:
It’s tough to make predictions, especially about the future.
-Yogi Berra
关于今后的努力方向
“数据结构这门课非常重要”,马老师如是说。
用一个例子说明这一点。
除了上面提到的逐步回归算法以外,我还自己动手写了分类树的算法。同样的,调用现有的R包只需要两行代码:
library(rpart)
fit <- rpart(Kyphosis~Age + Number + Start,
data = kyphosis, method = "class",control = ct,
parms = list(prior = c(0.65,0.35), split = "information"))
而我写了150多行,来实现同样的效果。看起来是不太划算,一棵简单的分类树写了这么多。但其实这是重要的基本元素,在它的基础上,稍加修改,加一个抽样函数,就能够实现随机森林、AdaBoost等很厉害的算法,甚至还能够在它们的基础上做调整和优化。
马老师的原代码里,有两个非常brilliant的地方。一个是用data.frame来记录和表达整棵分类树,每一行表示一个树节点,包括了它是否为叶节点,子节点的编号是什么,对应哪些观测,划分变量是什么,划分节点在哪儿,预测值是多少等信息。我个人认为,分类树本质上是一个多层嵌套的if...else...结构,而老师能够想到用data.frame来表达这个结构,很厉害。
另一个点是,只用了一个向量index就把所有的树节点所对应的观测数据给记录了下来,从一开始的1:n不断精炼和调整顺序,从而得到最终的index。而我最初的做法是用list来记录信息,一个树节点就对应一个list,这样的做法,不必要地消耗了内存,效率也不高。
indexL = indexCurrent[subx[,tree$splitvariable[cur]] >= tree$splitpoint[cur]]
indexR = indexCurrent[subx[,tree$splitvariable[cur]] < tree$splitpoint[cur]]
index[beginC:endC] = c(indexL,indexR)
index实在是个很厉害的想法,我暗自赞赏了很久。
所以,如果没有学过数据结构这门课,就不容易想到用data.frame和vector来记录信息,上过这门课,才能知道什么样的结构更适合用于表达呈现你的算法。
关于分类树的代码,还有一点值得说的是,里面有这么一行:
xvalues = sort(unique(subx))
在遍历自变量选出最优划分条件的时候,每次循环都要对自变量进行排序,非常耗时间。老师让我们尝试去优化,我试着试,一通瞎操作,结果运算时间不但没有减少,反而多了将近一倍。我意识到,我没法优化是因为我对于算法基础不了解,不知道什么样的运算对计算机而言是耗时的,不知道算法的时间复杂度是多少。要想继续在这方面深造,这门课得补。
在大数据的背景下,并行式编程(parallel programming)也必不可少。老师在课上总是强调并行的重要性,R语言之所以这些年来被python赶超,是因为它背后的维护人员是统计背景的,而python的社区无疑更为强大,大量搞计算机的人在做着贡献,使得它在并行计算方面做得更好。
另外,深度学习/神经网络自然也是需要掌握的,不掌握CNN/DNN/RNN这样的技能,便只能处理结构化的,整齐划一的数据,对于这世界上大量的复杂结构的数据束手无策。不过在我当前这个阶段,这倒不是当务之急,so,it can wait。
总之,要学的知识很多,要想掌握也不是一天两天的事情。不然为啥要出国读个硕士而不是待在家里自习呢?:)
喜欢的东西,感兴趣的东西,总是有机会学明白的。
时间序列
时间序列应该算是连接数据科学和经济学(计量经济学)之间的桥梁。有些时候它给我一种游离在主流体系之外的感觉。虽然书上没有明确地说,但是可以看到,上面所提到的所有算法和模型,都是针对横截面数据来谈的。
这门课用的参考书是刘苗老师和吴喜之老师自己写的书。

关于吴喜之老师,有一个插曲。老师是统计圈内的一个大牛,三月初的时候来我们学校开了场讲座,我去听了,还和老师聊了会儿。后来我才发现,马景义和刘苗都是吴喜之老师的学生,马景义是刘苗的师兄。听过吴老师的讲座,现在上课用的又是老师的课件,真是一种奇妙的体验。

我现在明白了,这不是巧合。当你找到了喜欢做的事情之后,你会发现生活的方方面面开始串联起来,联系起来,逐渐地形成一个流畅的体系。
说回这门课,期中的时候布置了一份project作业,原本要求三个人一组合作完成,我觉得这个project还没有大到需要分工合作才能完成的地步,索性一个人写代码,跑数据,写文章。很高兴的是得到了老师的认可,被当做范文讲了大半节课。

当然,project里的问题有很多,比如一阶单整序列预测之后怎么还原回差分之前的序列,比如怎么填补时间序列的缺失值(我觉得它比横截面数据缺失问题更为严重,因为时间是连续的,不能出现断点)。
而且,对于这门课,我有两个基本问题还没有想明白。
- 面板数据既有横截面属性又有时间序列属性,那么为什么谈论面板数据时不讨论序列相关、序列平稳、单位根检验?为什么时间序列分析比面板数据分析更为复杂?
- 时间序列背后对应的随机变量是什么?再背后对应的随机事件是什么?再再背后对应的随机性是什么?我曾经偶然悟出这么一句话,“世界上绝大多数事件都是随机事件,确定性事件是非常少的”,是否正确?
again,还是好好学了之后再来回答吧。
统计计算
李丰老师的这门课是开给大二同学的基础课,主要讲R语言的基本操作。因为我在上面两门课程中R的训练足够了,所以在从门课里学到的知识相对较少(而且老师讲课节奏偏慢)。比较有意思的内容是Nelder–Mead算法和马尔科夫链,还有用ggplot2来画出很好看的图。
倒是李丰老师的个人网站很吸引我,我觉得很酷。
受到启发,这几天在试着用Github pages来建一个自己的个人网站,我觉得会很有意思。
噢对了,老师还写了一个R包,关于随机变量分布的,同样也很酷。
结语
官官给我推荐过一篇很不错的文章给明年依旧年轻的我们,里边有一句话我非常喜欢,送给自己,也送给大家。
你的理想就像一辆车,如果你觉得这辆车的一切都在你的控制之中,那么可能说明你开得还不够快 (Your dream is like your car. If you are in full control of it, you are not driving it fast enough)。