一、简介
Hbase:全名Hadoop DataBase,是一种开源的,可伸缩的,严格一致性(并非最终一致性)的分布式存储系统。具有最理想化的写和极好的读性能。它支持可插拔的压缩算法(用户可以根据其列族中的数据特性合理选择其压缩算法),充分利用了磁盘空间。
类似于Google的BigTable,其分布式计算采用MapReduce,通过MapReduce完成大块的数据加载和全表扫描操作等。文件存储系统采用HDFS,通过Zookeeper来完成状态管理协同服务。不过BigTable只支持一级索引,Hbase不仅支持一级索引,还支持二级索引。
需要指出的是:很多人都认为Hbase是面向列的数据库,其实不是。从典型的关系型数据库概念上来说Hbase并不是面向列的数据库。但是充分利用了磁盘上列式存储格式的特性。Hbase跟传统的Columnar databases还是有区别的。Columnar databases擅长的是实时数据的分析访问,而Hbase在基于key的单值访问和范围扫描上比较突出。不过我们经常谈及到的Hbase是面向列的存储系统,其实是因为Hbase是以列族的模式进行存储的。
二、Hbase基本结构
1)架构图
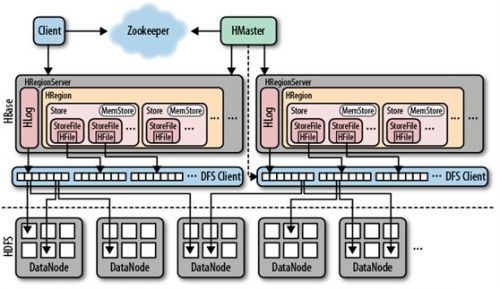
从上图中可以看出,Hbase内部的核心结构由以下几大块组成:HMaster,HRegionServer,HLog,HRegion等。而Hbase依赖的外部系统有Zookeeper,HDFS等。
1)HMaster(类似于HDFS中NameNode,MapReduce中的JobTrackers)是用来管理HRegionServer的。它负责监控集群中HRegionServer的状态信息变化。主要功能点如下:
1、管理HRegionServer的负载均衡,调整Region分布。这个通过HMaster的后台线程LoadBalancer来完成。LoadBalancer会定期将Region进行移动,以使各个HRegionServer达到Load均衡。
2、在Region Split后,负载新Region的分配。
3、HRegionServer的FailOver处理,当某一个HRegionServer出问题后,HMaster负责将其Region进行转移。
4、CatalogJanitor。 CatalogJanitor会定期检查和清理.Meta.表。
在一个HBase集群中会存在多个HMaster,不过zookeeper的Master Election机制会保证只有一个HMaster在运行。当运行的HMaster出问题后,其他的HMaster就会立刻补上。
2)从图中可以看出,Hbase客户端是只与zookeeper和HRegion Server打交道。并不会跟HMaster交互。所以如果HMaster出问题了,Hbase集群在短时间内还是可以对外提供可靠服务的。但是,因为HMaster掌控了HRegionServer的一些功能,如:HRegion Server的FailOver操作,Region切分等,HMaster长时间不可用还是会出问题的。
3)上面所提及的Catelog表有两个:-Root-和.Meta.表。-Root-表中存储了.Meta.表的位置。即.Meta.表的Region key。.Meta.表存储了所有Region的位置及每个Region所包含的RowKey的范围。-Root-表的存储位置记录在zookeeper中,.Meta.表的存储位置记录在-Root-表中。
4)当客户端发起一个查询数据的请求后,首先,客户端会先连接上zookeeper集群,获取-Root-表的存放在哪一个HRegionServer上。接着找到对应的HRegionServer后,就能够获取到-Root-表中对应的.Meta.表的位置。最后客户端根据.Meta.表存储的HRegion的位置到相应的HRegionServer中取对应的Hregion中的数据信息。经过一次查询后,访问Catalog表的过程就会被缓存起来,下次客户端就可以直接到相应的HRegion上获取数据。
5)Hbase已经无缝集成了HDFS,其中所有的数据最终都会通过DFS客户端API持久化到HDFS中。
6)一个Hbase集群中有许多个HRegionServer(类似于HDFS中的DataNode,MapReduce中的TaskTrackers),由一个HMaster进行管理。每个HRegionServer拥有一个WAL(write Ahead Log,日志文件,用作数据恢复)和多个HRegion(可以简单认为是用来存储一个表中的某些行)。一个HRegion拥有多个Store(存储一个ColumnFamily)。一个Store又由一个MemStore(持有对该Store的所有修改于内存中)和0至多个StoreFiles(HFile,数据存储的地方)组成。详细图如下:
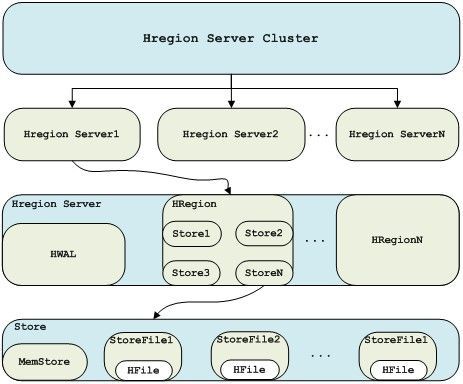
2)基本元素
1、Row Key
行标示,类似于传统数据库表中的行号。Rowkeys具有不变性。除非该行别删除或者被重新插入了新的数据。Hbase中支持基于RowKey的单行查询和范围扫描。在Hbase的Auto-Sharding中,也是基于RowKey进行自动切分的。
2、Column Family
在Hbase中最基本的单元就是列。而列族是由一个或者列组成。一般在使用时,尽量将经常访问的列作为一个列族。因为Hbase是面向列族的存储,也就是说一个列族中的所有列是存储在一起的。即上图中的一个Store存储一个列族。
不过有一点需要注意的是在一个表中列族被限定不能超过十个。
3、TimeStamp
Hbase中支持时间戳的概念。即允许Cell存储多个版本值。版本之间通过时间戳来区分。也就是说可能存在某一列的某一行有多个值。一般默认是3,且最近版本在最上面。Hbase中有一个TTL(Time To Live)的配置,这个是基于列族维度的。一旦过期,列族就会自动删除所有行。
4、HRegion Server
HRegionServer是负责服务和管理Region的。类似于我们所说的主从服务器,HMaster就是主服务器,HRegionServer就是从服务器。当用户执行CRUD等操作时,都需要通过HRegionServer定位到相应的Region上进行操作。
5、WAL
WAL全名是Write Ahead Log,类似于mysql中的Binary Log,WAL记录了该HRegionServer上所有数据的变更。一旦这个HRegionServer死翘翘了,导致数据丢失后,WAL就是救命稻草。可以通过WAL进行数据恢复。所以在平时WAL是没什么用的,只是为了不可预知的灾难做准备。当然,WAL起作用的前提是保证变更日志已经记录到了WAL中。
WAL的实现类是HLog。因为在一个HRegionServer中持有一个WAL,所以对于该HRegionServer上的所有Region来说,WAL是全局,共享的。当HRegion实例创建的时候,在HRegionServer实例中的HLog就会被当做HRegion构造函数的参数传递到HRegion。当HRegion接收到一个变更操作时,HRegion就能直接通过HLog将变更日志追加(append()方法)到共享WAL中。当然基于性能考虑,HBase还提供了一个setWriteToWAL(false)方法。一旦用户调用了此方法。变更日志就不会追加到WAL中。默认是需要写入的,除非用户自己保证数据不会丢失。
HLog还有一个重要的特性就是:跟踪变更。在HLog类中有一个原子类型的变量,HLog会读取StoreFiles中最大的sequence number(HLog中每一条变更日志都有一个number号,因为对于一个HRegionServer中的所有HRegion是共享HLog的,所以会将变更日志顺序写入WAL,StoreFiles中也持有该number),并存放到变量中。这样HLog就知道已经已经存储到哪一个位置了。
WAL还有两个比较重要的类,一个是LogSyncer,另一个是LogRoller。
1、在创建表时,有一个参数设置:Deferred Log Flush,默认是false,表示log一旦更新就立即同步到filesystem。如果设置为true,则HRegionServer会缓存那些变更,并由后台任务LogSyncer定时将变更信息同步到filesystem。
2、WAL是有容量限制的,LogRoller是一个后台线程,会定时滚动logfile,用户可以设定这个间隔时间(hbase.regionserver.logroll.period,默认是一小时)。当检查到某个logfile文件中的所有sequence number均小于那个最大的sequence number时,就会将此logfile移到.oldLog目录。
如下是WAL的文件结构,目前WAL采用的是Hadoop的SequenceFile,其存储记录格式是key/value键值对的形式。其中Key保存了HLogkey的实例,HLogKey包含数据所属的表名及RegionName,timeStamp,sequenceNumber等信息。Value保存了WALEdit实例,WALEdit包含客户端每一次发来的变更信息。
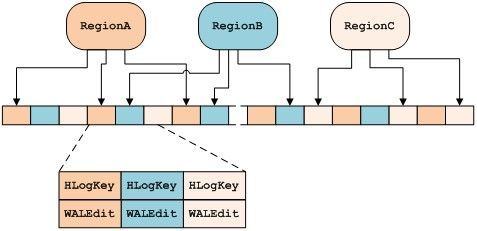
6、Region
在Hbase中实现可扩展性和负载均衡的基本单元是Region。Region存储着连续的RowKey的数据。刚开始时,一个表就只有一个Region,当一个表随着数据增多而不断变大时,如果达到指定的大小后就会根据Rowkey自动一分为二成两个Region。每个Region中保存着一个【startkey,endkey】。随着表的继续增大,每个Region又会自动split成更多的Region。每个Region只会由一个HRegionServer服务。这就是所谓的Hbase的AutoSharding特性。当然,Region除了会spilt外,也可能进行合并以减少Region数目(这就是Hbase的compaction特性,后面会谈到)。
既然Region是表的基本元素。那么,用户如何获取到对应的Region呢??前面已经提及—通过Catalog表。
7、Store
Store是核心存储单元。在一个HRegion中可能存在多个ColumnFamily,那么Store中被指定只能存储一个ColumnFamily。不同的ColumnFamily存储在不同的Store中(所以在创建ColumnFamily时,尽量将经常需要一起访问的列放到一个ColumnFamily中,这样可以减少访问Store的数目)。一个Store由一个MemStore和0至多个StoreFile组成。
8、MemStore
Hbase在将数据写入StoreFile之前,会先写入MemStore。MemStore是一个有序的内存缓冲器。当MemStore中的数据量达到设定的大小时(Flush Size),HRegionServer就会执行Flush操作,将MemStore中的数据flush到StoreFile中。
当HRegionServer正在将MemStore中的数据Flush到StoreFile时,MemStore还可以对外进行读写服务。这个是通过MemStore的滚动机制实现的。通过滚动MemStore,新的空的块就可以接收变更,而老的满的块就会执行flush操作。
9、StoreFile/HFile
StoreFile是HFile的实现,对HFile做了一层包装。HFile是数据真正存储的地方。HFile是基于BigTable的SSTable File和Hadoop的TFile。HFile是以keyvalue的格式存储数据的。(Hbase之前使用过Hadoop得MapFile,因为其性能上相当糟糕而放弃。)下图是HFile中版本1的格式,版本2稍有改变(详见Hbase wiki):
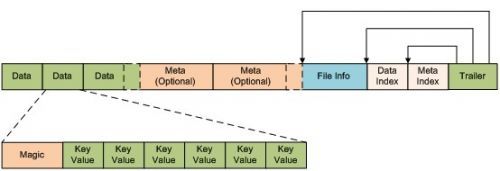
从上图中看出,HFile是由多个数据块组成。大部分数据块是不定长的,唯一固定长度的只有两个数据块:File Info和Trailer。DataIndex和MetaIndex分别记录了Data块和Meta块的起始位置。每个data块由一些kevalue键值对和Magic header组成。Data块的大小可以再创建表时通过HColumnDescriptor设定。Magic记录了一串随机的数字,防治数据丢失和损坏。
如果用户想绕过Hbase直接访问HFile时,比如检查HFile的健康状态,dump HFile的内容,可以通过HFile.main()方法完成。
如下图是KeyValue的格式:

KeyValue是一个数组,对byte数组做了一层包装。Key Length和Value Length都是固定长度的数值。Key包含的内容有行RowKey的长度及值,列族的长度及值,列,时间戳,key类型(Put, Delete, DeleteColumn, DeleteFamily)。
从上图可以看出,每一个keyValue只包含一列,即使对于同一行的不同列数据,会创建多个KeyValue实例。此外KeyValue不能被Split,即使此KeyValue值超过Block的大小,比如:
Block大小为16Kb,而KeyValue值有8Mb,那么KeyValue会通过相连的多个Block进行存储。
3)总结
以上对Hbase的基本元素做了一个大体的介绍。下图是Hbase的存储结构图。记录了客户端发起变更或者新增操作时,Hbase内部的存储流程。
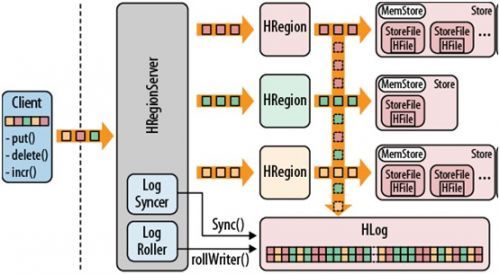
下面来分析下整个存储流程:
1)当客户端提交变更操作(如插入put,删除delete,计数新增incr),首先客户端会连接上Zookeeper找到-Root-表的存储位置,然后根据-Root-表所提供的.Meta.表的位置找到对应的Region所在的HRegionServer。数据变更信息会先通过HRegionServer写入一个commit log,也就是WAL。当写入WAL成功后,数据变更信息会存到MemStore中。当MemStore达到设定的maximum value(hbase.hregion.memstore.flush.size,默认64MB)后,MemStore就会开始进行Flush操作,将其内容持久化到一个新的HFile中。在Flush操作过程中,MemStore通过滚动机制继续对用户提供读写服务。随着Flush操作的不断进行,HFile文件越来越多。 当HFile文件超过设定的数量后,Hbase的HouseKeeping机制就会通过Compaction特性将HFile小文件合并成一个更大的HFile文件。在Compaction的过程中,会进行版本的合并以及数据的删除。由于storeFiles是不变的,用户执行删除操作时,并不能简单地通过删除其键值对来删除数据内容。Hbase提供了一个delete marker机制(也称为tombstone marker),会告诉HRegionServer那个指定的key已经被删除了。这样其它用户检索这个key的内容时,因为已经被标记为删除,所以也不会检索出来。在进行Compaction操作中就会丢弃这些已经打标的记录。经过多次Compaction后,HFile文件会越来越大,当达到设定的值时,会触发Split操作。将当前的Region根据RowKey对等切分成两个子Region,当期的那个Region被废弃,两个子Region会被分配到其他HRegionServer上。所以刚开始时一个表只有一个Region,随着不断的split,会产生越来越多的Region,通过HMaster
的LoadBalancer调整,Region会均匀遍布到所有的HRegionServer中。
2)当HLog满时,HRegionServer就会启动LogRoller,通过执行rollWriter方法将那些所有sequence number均小于最大的那个sequence number的logfile移动到.oldLog目录中等待被删除。如果用户设置了Deferred Log Flush为true,HRegionServer会缓存有关此表的所有变更,并通过LogSyncer调用sync()方法定时将变更信息同步到filesystem。默认为false的话,一旦有变更就会立刻同步到filesystem。
3)在一个HRegionServer中只有一个WAL,所有Region共享此WAL。HLog会根据Region提交变更信息的先后顺序依次顺序写入WAL中。如果用户设置了setWriteToWAL(false)方法,则有关此表的所有Region变更日志都不会写入WAL中。这也是上图中Region将变更日志写入WAL的那个垂直向下的箭头为什么是虚线的原因。
三、Hbase基本操作
Hbase中主要的客户端接口是HTable类,HTable提供了对数据的所有CRUD操作。需要注意的是由于创建HTabe实例比较耗时, 所以在实际使用中最好创建单例模式的HTable实例,不过如果需要多个HTable实例的话,可以考虑使用HBase的HTablePool特性(下面后讲到)。Hbase不提供直接的update操作。由于Hbase中数据存储有版本支持。所以如果需要update一条记录,一般是通过put操作,这样历史版本会在Compaction操作中被合并掉,这样就间接实现了更新。(在MemStore中有一个变量MemstoreTS,该变量是随put操作而递增的。比如首先往列A,timeStamp为T1上put一条数据data1,假设此时MemstoreTS为1;之后如果想更新这条数据,只需要往列A,timeStamp为T1上put一条数据data2,此时MemstoreTS为2,Hbase会自动会将MemstoreTS大的排在前面。MemstoreTS小的在Compaction过程中就被过滤掉了。)
1)put操作
Put操作就是讲数据插入到Hbase中。有两种模式,一种是对单行的操作(single put);还有一种是对多行的操作(List of put)。针对单行操作的方式如下:
1、创建put实例有如下构造函数:需要用户指定某行,用户也可以设定时间戳作为版本标示。此外,用户还可以加入自定义的行锁,以防其它用户或者其它线程在变更期间访问此行的数据。
Put(byte[] row)
Put(byte[] row, RowLock rowLock)
Put(byte[] row, long ts)
Put(byte[] row, long ts, RowLock rowLock)
在Hbase中参数的传递大多是byte数组类型。Hbase提供了许多静态方法将java类型转换成byte数组类型。如下:
static byte[] toBytes(ByteBuffer bb)
static byte[] toBytes(String s)
static byte[] toBytes(boolean b)
static byte[] toBytes(long val)
static byte[] toBytes(float f)
static byte[] toBytes(int val)
2、一旦创建好put实例后,就可以通过put类提供的方法插入数据了。插入数据的操作需要指定列族,所在列等。如下:
Put add(byte[] family, byte[] qualifier, byte[] value)
Put add(byte[] family, byte[] qualifier, long ts, byte[] value)
Put add(KeyValue kv) throws IOException
3、put组装完成后,就可以通过HTable提供的void put(Put put)throws IOException完成数据的插入操作。
如果需要对多行进行put操作,可以组装一系列的put实例,然后调用HTable提供的void put(List puts) throws IOException来完成多行插入操作。不过需要指出的是:如果在这多个Put实例中存在一个put实例有误(比如:往一个不存在的列族中插入数据),那么该put实例会报错,但是不影响其他的put实例。跟后面的get操作有点区别。
此外,Hbase还提供了一个原子型的put操作:Atomic compare-and-set ,方法如下:boolean checkAndPut(byte[] row, byte[] family, byte[] qualifier,byte[] value, Put put) throws IOException。只有校验成功后才会完成put操作.
需要注意的是,因为每次的put操作相当于一个RPC,将数据从客户端传递到服务端并返回。如果你的应用中RPC非常频繁,比如一秒内成千上万次,可能会有隐患。解决的办法就是尽量降低RPC次数,Hbase提供了一个嵌入的客户端写缓存器(Client-side Write Buffer)。它会缓存所有的put操作,然后再一次性提交。默认情况下Client-side Write Buffer是没有激活的。用户可以在创建HTable的时候通过调用table.setAutoFlush(false)方法来激活它。并且可以通过isAutoFlush()来检查是否已经激活。默认是true,表示一旦有put操作会立即发送到服务器端。当你想将所有put操作提交到服务器端时,可以调用flushCommits()操作。它会将缓存器中所有变更提交到远程服务器。Client-side Write Buffer还会自动对buffer中的所有变更进行分组,同一个HRegionServer的分到同一个组。这样每个HRegionServer通过一个RPC传送.
2)get操作
Get操作就是从服务器端获取数据。跟put操作一样,get操作也分为两种模式,一种是对单行的get操作(single get),另一种是对多行进行检索操作(List of gets)。
1、HTable提供的get方法如下:其返回值为Result类,该类包含了列族,列,keyvalue,
RowKey等信息。该类提供的丰富的方法供用户获取返回的各种信息。
Result get(Get get) throws IOException
2、Get类的构造函数如下,需要用户传入指定的行及行锁等参数。
Get(byte[] row)
Get(byte[] row, RowLock rowLock)
3、 一旦创建的get实例后,用户可以调用Get类提供的如下方法来框定你需要检索的数据。如下:用户可以指定列族,列,时间戳,最大版本号等。如果不设置版本号,默认是1,表示最大的版本。
Get addFamily(byte[] family)
Get addColumn(byte[] family, byte[] qualifier)
Get setTimeRange(long minStamp, long maxStamp) throws IOException
Get setTimeStamp(long timestamp)
Get setMaxVersions()
Get setMaxVersions(int maxVersions) throws IOException
跟List of put 类似,对于多行的检索操作,HTable也提供了类似的如下方法:用户只要创建多个get实例,就可以通过如下方法获取需要的数据。不过需要注意的是:跟List of put不同的是,如果Get实例列表中只要存在一个Get实例有误(比如get一个不存在的列族的值),那么整体就会抛出一个异常.
Result[] get(List gets) throws IOException
3)delete操作
Delete操作也类似,HTable提供了两种方法,支持单个delete实例和多个delete实例的操作。如下:
void delete(Delete delete) throws IOException
void delete(List deletes) throws IOException
1、相应的delete实例构造函数有:
Delete(byte[] row)
Delete(byte[] row, long timestamp, RowLock rowLock)
2、如果你需要添加一些限制条件,可以使用delete类提供的相关方法,支持指定列族,列,时间戳等。如果你指定了一个时间戳,则表示小于等于该时间戳的时间将被删除。如果指定了列和行号,但没有指定时间戳,则默认会删掉版本号最大的那个值。
Delete deleteFamily(byte[] family)
Delete deleteFamily(byte[] family, long timestamp)
Delete deleteColumns(byte[] family, byte[] qualifier)
Delete deleteColumns(byte[] family, byte[] qualifier, long timestamp)
Delete deleteColumn(byte[] family, byte[] qualifier)
Delete deleteColumn(byte[] family, byte[] qualifier, long timestamp)
void setTimestamp(long timestamp)
3、当使用List of delete时,如果有一个delete实例出错,那么会抛出异常。而且delete的实例列表中只会存在那个出问题的delete实例。Delete也支持原子型的Compare-and- Delete,如下:
boolean checkAndDelete(byte[] row, byte[] family, byte[] qualifier,byte[] value, Delete delete) throws IOException
4)Batch操作
Hbase还支持批量操作。其实上面所谈到的List of puts,gets,deletes都是基于Batch操作来的。不过List of puts,gets,deletes逐渐会被废弃。推荐使用Batch操作。HTable提供的batch操作方法如下:参数中Row类是Put,Delete,Get类的父类。表示用户可以同时传入put,get及delete实例操作。不过在一个batch中,最好不要同时传入针对同一行的put和delete实例。
(1) void batch(List actions, Object[] results) throws IOException, InterruptedException
(2) Object[] batch(List actions) throws IOException, InterruptedException上面这两个batch方法比较类似,但有比较大的区别。第一个batch方法需要用户传递一个数组,该数组用来填充batch操作中所有成功的操作的结果集。如果没有指定这个数组,比如第二个方法。一旦batch操作中某一个实例出现问题,那么Hbase只会抛出一个异常。那些成功的操作的结果并不会返回。而第一个方法则会将那些成功的操作的结果集返回给用户。
此外Batch操作不支持Client-side write buffer,Batch方法是同步的,会直接将其包含的操作发往服务器。这点需要注意!
Batch操作返回的结果可能的结果有如下几种:
1、null:表示那个操作操作连接远程服务器失败。
2、Empty Result:put和delete操作的返回结果,表示操作成功。
3、Result:get操作的返回结果集
4、Throwable:异常结果
5)Scan操作
Scan操作类似于传统的RDBMS中的游标的概念。其目的跟get一样,也是检索服务器端数据。Hbase也提供了一个Scan类。由于Scans类似于迭代器,所以你需要通过getScanner()方法获取。HTable提供了如下方法:如果你看了源码就会知道,后面那两个方法其实是先创建一个scan实例,并加入传入的参数,然后再调用第一个方法。
ResultScanner getScanner(Scan scan) throws IOException
ResultScanner getScanner(byte[] family) throws IOException
ResultScanner getScanner(byte[] family, byte[] qualifier) throws IOException
1、Scan类提供了多个构造函数,如下:startRow和stopRow是左闭右开的。从构造函数中可以看出,用户只需要指定rowKey的范围,或者添加相应的过滤器,Hbase能够自动检索你指定的RowKey的范围的数据。如果没有指定startRow,默认从第一行开始.
Scan()
Scan(byte[] startRow, Filter filter)
Scan(byte[] startRow)
Scan(byte[] startRow, byte[] stopRow)
2、当创建好Scan实例后,如果想添加更多的限制条件,可以通过调用Scan提供的如下方法:允许添加列族,列,时间戳等.
Scan addFamily(byte [] family)
Scan addColumn(byte[] family, byte[] qualifier)
Scan setTimeRange(long minStamp, long maxStamp) throws IOException
Scan setTimeStamp(long timestamp)
Scan setMaxVersions()
Scan setMaxVersions(int maxVersions)
GetScanner()方法返回的是一个ResultScanner实例。需要注意的是:如果结果集存在多行,Scans并不会一次性将所有行在一个RPC里面传送给客户端,而是基于一行一行传送。这样做主要是因为多行需要耗费大量时间。
ResultScanner类包装了Result类将其每行结果以迭代的方式输出,使得Scan操作类似于get操作。此外ResultScanner类提供了如下方法供用户进行迭代使用:用户可以选择一次返回一行或者多行。不过不要认为是服务器端一次性返回多行。其实是客户端循环调用nbRows 次next()方法而已。服务器端在一个RPC里面还是只传送一行数据。这个确实有点影响心情,但Hbase就喜欢恶心下你,不过它也提供的相应的解决办法:Scanner Caching,默认是关闭的。
Result next() throws IOException
Result[] next(int nbRows) throws IOException
void close()
close()方法表示释放ResultScanner实例。因为ResultScanner实例持有了一定的资源,如果不及时释放,可能随着时间推移会占用很大的内存空间。此外,close()操作最好放在finally模块,原因你懂得!
四、Hbase特性
HBase提供了许多赏心悦目的特性。如Filters,Counters,Coprocessors,Compaction,HTablePool等。
1)Filters
当你通过Scan或者Get操作检索数据时,会发现Scan和Get只支持基于RowKey,列族,列,时间戳等粗粒度的检索。如果用户想基于Key或者Value或者正则表达式等作为查询条件进行查询的话,Scan和Get是没办法做到的。而Filter就是干这事的。Hbase提供了一系列的Filters,用户只要实现Filter,也可以自定义Filters。
需要说明的是Hbase提供的这些Filters都是配置在客户端,但应用在服务器端,也叫做Predicate push-down。(比如用户在进行Scan操作时可以传入Filter,序列化后传送到服务器端,HRegionServer就会将其反序列化,并应用到内部Scanner)。这样可以有效减少数据传输带来的网络开销。
需要注意的是:Filters的通用约定是过滤掉你不需要的数据,而不是用来指定你需要的数据。不过凡是继承CompareFilter过滤器的Filter,其作用刚好相反,用来指定你需要的数据。
Hbase提供的Filters有:
Ⅰ. Comparison Filters
Compartison Filters是基于比较的过滤器。定义如下:
CompareFilter(CompareOp valueCompareOp,WritableByteArrayComparable valueComparator)
该构造器有两个特定的参数,一个是比较运算符,另一个是比较器。
A、常见的比较运算符有:
LESS,LESS_OR_EQUAL,EQUAL,NOT_EQUAL,GREATER_OR_EQUAL,GREATER,NO_OP。前面几个运算符根据名字定义就能判断其意思,最后一个是NO_OP,表示排除任何数据。
B、常见的比较器有:其中NullComparator是判断给定的值是否为空或者非空。最后三个比较器只能搭配使用EQUAL,NOT_EQUAL比较运算符,返回0表示匹配,1表示不匹配。
BinaryComparator
BinaryPrefixComparator
NullComparator
BitComparator
RegexStringComparator
SubstringComparator
C、基于Comparison Filter的过滤器有好多种,比如:
1、RowFilter
2、FamilyFilter
3、QualifierFilter
4、ValueFilter
5、DependentColumnFilter
(1) RowFilter过滤器顾名思义就是根据RowKey来过滤数据。所以RowFilter中的比较运算符和比较器参数都是基于RowKey来比较的。比如如下Filter表示RowKey包含-4的数据。
Filter filter = new RowFilter(CompareFilter.CompareOp.EQUAL,new SubstringComparator("-4"))。
(2) FamilyFilter过滤器跟RowFilter类似,不过FamilyFilter是基于ColumnFamily的比较。
QualifierFilter和ValueFilter过滤器也类似,分别是基于列和数值的比较。
(3) DependentColumnFilter过滤器稍微复杂一点。它可以说是timeStamp Filter和ValueFilter的结合。因为DependentColumnFilter需要指定一个参考列,然后获取跟改参考列有相同时间戳的所有列,再在此基础上获取满足ValueFilter的列值。构造函数如下:用户可以根据自己喜好省略valueFilter或者通过设置dropDependentColumn为true省略timestamp Filter。不过需要注意的是:此过滤器不能跟Scan中的Batch操作结合使用。
A、DependentColumnFilter(byte[] family, byte[] qualifier)
B、DependentColumnFilter(byte[] family, byte[] qualifier,boolean dropDependentColumn)
C、DependentColumnFilter(byte[] family, byte[] qualifier,boolean dropDependentColumn, CompareOp valueCompareOp,WritableByteArrayComparable valueComparator)
Ⅱ. Dedicated Filters
专有的一些过滤器,Hbase提供了许多个性化的专有过滤器。常见的Dedicated Filters有:
A、SingleColumnValueFilter
B、SingleColumnValueExcludeFilter
C、PrefixFilter
D、PageFilter
E、KeyOnlyFilter
F、FirstKeyOnlyFilter
G、InclusiveStopFilter
H、TimestampsFilter
I、ColumnCountGetFilter
J、ColumnPaginationFilter
K、ColumnPrefixFilter
L、RandomRowFilter
(1) 如果你想分页获取数据,可以通过PageFilter来完成。ColumnPaginationFilter跟PageFilter类似,只不过PageFilter是基于行的分页,而ColumnPaginationFilter是基于列的分页。如:
ColumnPaginationFilter(int limit, int offset),表示获取从offset列开始的连续limit列的数据。
(2) 如果只想获取每一行的第一列的值,那么FirstKeyOnlyFilter是不错的选择。此外,因为前面提到的Scan操作需要用户指定一个startRow和EndRow,其中这两个参数时左闭右开区间的。如果想EndRow也包含,可以通过InclusiveStopFilter来解决。如下:获取从Row5至Row10的数据
。不过因为Hbase是字典排序的,所以得到的结果中可能会包含Row51,Row52等这些行的数据。
Filter filter = new InclusiveStopFilter(Bytes.toBytes("row-9"));
Scan scan = new Scan();
scan.setStartRow(Bytes.toBytes("row-5"));
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
(3) 如果想获取某个版本的所有数据。可以通过TimestampsFilter来设置,用户需要传入版本号。如下:
TimestampsFilter(List timestamps)
(4) PrefixFilter和ColumnPrefixFilter都是基于前缀的过滤器,不过PrefixFilter是基于行的前缀过滤,而后者是基于列的前缀过滤。
(5) RandomRowFilter是基于随机行的过滤器,用户需要指定一个在0到1之间的随机数,构造函数如下:如果chance大于1,则会返回所有行。如果小于0,则过滤掉所有行。
RandomRowFilter(float chance)
Ⅲ. Decorating Filters
Decorating Filters称为装饰型的过滤器。它的作用是为其他过滤器返回的结果提供一些附加的校验操作。常见的Decorating Filters有:
A、SkipFilter
B、WhileMatchFilter
(1) SkipFilter包装了其它的过滤器,只要被包装的过滤器返回的结果中有一行的某一列或者某个KeyValue被过滤掉了,那么SkipFilter会将该列或者KeyValue所处的整行全部过滤。被包装的过滤器必须实现filterKeyValue()方法。因为SkipFilter会依靠filterKeyValue()返回的结果进行附加的处理。比如:
Filter filter = new ValueFilter(CompareFilter.CompareOp.NOT_EQUAL,new BinaryComparator(Bytes.toBytes("val-1")));
上面这样一个filter,表示返回的结果中值不能等于val-1,这样值为val-1的那个列就不会展示,但该行的其他列只要满足值不等于val-1都会返回。
不过一旦使用了SkipFilter,如:Filter filter2 = new SkipFilter(filter);只要存在某一行中的某个列的值等于val-1,那么该行的所有数据都不会返回。
(2) WhileMatchFilter跟SkipFilter类似,不过区别之处在于WhileMatchFilter一旦找到某一行中的某些列值或者KeyValue不满足条件,那么整个Scan操作就会被终止。SkipFilter只是会将此行过滤,不作为返回值,但Scan操作会继续。
Ⅳ. Custom Filters
如果想实现自定义的Filter,可以实现Filter接口或者扩展FilterBase类。FilterBase类提供了基本的Filter实现。
如果用户想在一次检索数据的过程中使用多个Filter,那么可以使用FilterList特性。其构造函数如下:
FilterList(List rowFilters)
FilterList(Operator operator)
FilterList(Operator operator, List rowFilters)
其参数operator其枚举值有两个:MUST_PASS_ALL(表示返回的结果集数据必须通过所有过滤器的过滤),MUST_PASS_ONE(表示返回的结果集数据只要通过了其中一个过滤器就行)。
2)Counters
Hbase提供了计数器Counters机制。它将列当做Counters,通过对列的操作来完成计数。在命令行下用户可以通过如下命令增加计数。
incr ‘
’,’’,’’,[]
如果想获取当前计数器的值,可以通过get命令或者get_counter或者incr命令。如下:
get ‘
’,’’;
get_counter ‘
’,’’;
incr ‘
’,’’,’’,0;
第一个和第二个的区别就是第一个返回的值是字节数组类型,用户很难立刻知道到底代表什么值。第二个返回的是可读的值。第三个命令采用比较投机取巧的办法,通过incr计数加0来返回当前值。如果将减少计数,可以通过incr命令来增加一个负数的值。
HTable提供了单个计数器(Single Counters)和多个计数器(Multiple Counters)。对于单个的Counters,需要指定准确的列名,跟命令行的incr一样,可以通过增加正数和负数或者零来达到增加计数,减少计数以及访问当期计数的目的。构造函数如下:
long incrementColumnValue(byte[] row, byte[] family, byte[] qualifier,long amount) throws IOException
long incrementColumnValue(byte[] row, byte[] family, byte[] qualifier,long amount, boolean writeToWAL) throws IOException
对于多重计数器,HTable提供的方法如下:
Result increment(Increment increment) throws IOException
1、用户需要创建一个Increment实例,可以采用如下构造函数:
Increment() {}
Increment(byte[] row)
Increment(byte[] row, RowLock rowLock)
2、如果想为这个Increment实例添加必要的条件,如列名,或者时间戳范围,可以通过如下方法来完成。可以在一个Increment实例中通过增加多列来实现多重计数器。
Increment addColumn(byte[] family, byte[] qualifier, long amount)
Increment setTimeRange(long minStamp, long maxStamp) throws IOException
3)Coprocessors
Coprocessors是Hbase提供的另一大特性。可以认为是简化的MapReduce组件。Coprocessors是一组内嵌于RegionServer和HMaster进程的框架(BigTable的coprocessors拥有独立进程和地址空间),支持用户请求在每个Region上并行运行,类似于传统数据库中触发器的功能。
1、Hbase提供的Coprocessors有两种类型:observer和endpoint。其中observer类似于RDBMS中的触发器,即钩子函数,其代码部署在服务器端运行,在真实的方法前添加pre(),实现后加入
post(),以实现对真实方法的辅助操作。而endpoint类似于存储过程。
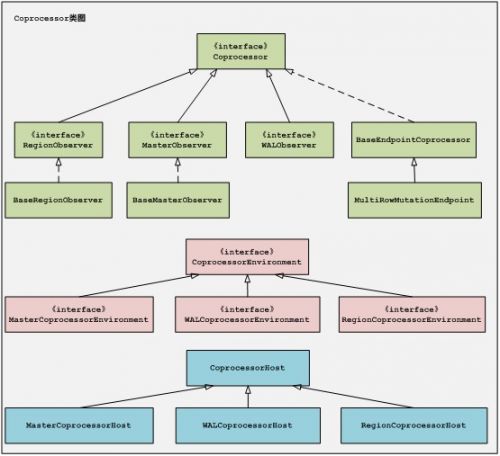
2、Coprocessors框架有三个模块组成:Coprocessors,CoprocessorEnvironment,
CoprocessorHost。CoprocessorEnvironment提供Coprocessors实例运行的环境以及持有
Coprocessors实例的生命周期状态。CoprocessorHost是用来维护Coprocessors实例和
Coprocessors运行环境的。
三元体类图如下(Hbase94版本):用户可以通过继承BaseRegionObserver, WALObserver,
BaseMasterObserver或者BaseEndpointCoprocessor来实现自定义的Coprocessors。
A、coprocessors Load
Coprocessors有两种加载方式:通过配置文件方式的静态加载和动态加载方式。
a、配置文件加载
静态加载方式就是通过hbase-site.xml配置文件配置指定的coprocessors来加载。配置方式如下,其执行顺序就是按照配置文件指定的顺序:
hbase.coprocessor.region.classes
coprocessor.RegionObserverExample,coprocessor.otherCoprocessor
hbase.coprocessor.master.classes
coprocessor.MasterObserverExample
hbase.coprocessor.wal.classes
coprocessor.WALObserverExample, bar.foo.MyWALObserver
需要注意的是:通过这种方式加载的RegionObserver是针对所有Region和表的。用户无法指定某一具体的Region或者table。
b、通过table description加载
通过这种方式的加载是细化到具体的表的维度。只有跟该表有关的Region操作才会加载。所以这种方式的加载只能针对RegionCoprocessor。加载方法是:
HTableDescriptor.setValue(),其中key是Coprocessor,value是||
B、observer
observer又有三种实现类型:
a、RegionObserver
RegionObserver一般用来进行数据操作的coprocessor,比如数据访问前的权限身份验证,Filter,二级索引等。如:
void preFlush(...) / void postFlush(...) MemStore中内容flush到Storefile前后添加辅助型操作。
void preGet(...) / void postGet(...) 获取数据的前后添加辅助操作
b、MasterObserver
MasterObserver是面向整个集群的事件,比如基于管理员的操作和DDL类型的操作的监控。如:
void preCreateTable(...) / void postCreateTable(...) 创建表前后做些辅助操作
void preAddColumn(...) / void postAddColumn(...) 创建列前后做些辅助操作
void preMove(...) / void postMove(...) 移动Region的前后添加辅助操作
c、WALObserver
WALObserver则是提供钩子函数对Write Ahead Log的的操作。
C、Endpoint
Endpoint动态扩展了RPC协议。只支持Region的操作,不支持Master和WAL的操作。用户可以通过Endpoint完成一些聚集函数的功能,如AVG,Count,SUM等。其原理是通过包装客户端的实现,类似于MapReduce,比如getSum()操作,Map端endpoint通过并行的scan完成对每个Region的操作,每个Region的scan结果汇总到endpoint包装的客户端,将每个Region反馈的结果进行汇总即可得到getSum()的结果。
D、小结
a、Coprocessors有两种类型:observer和endpoint。observer类似于传统的关系型数据库中的触发器,通过钩子函数来完成对被钩的方法的辅助功能,endpoint类似于关系型数据库中的存储过程,用来实现聚合函数的相关功能。
b、Coprocessors支持动态加载,拥有多种加载方式。
c、Coprocessors可以将多个Coprocessor链接在一起使用,类似于Servlet中的filters过滤器。
d、Coprocessors中有优先级的概念,SYSTEM级别的Coprocessor优先处理,USER级别的Coprocessor优先级更低。
4)Split And Comcaption
A、Region Split
当创建一个表时,此时该表只对应一个Region。随着不断了往表中插入记录,表数据越来越多,当超过设定的值hbase.hregion.max.filesize时,该Region就会Split成两个子Region。原来的那个Region就会被删除。具体操作如下:
a、HRegionServer创建一个splits目录,并且关闭其父Region以防接收其它请求。
b、HRegionServer会在splits目录准备好两个子Region,父Region的RowKey对半切。然后将其移动到表目录下,并且更细.Meta.表的数据,指示该父Region正在被执行Split操作。
c、读取父Region的数据到子Region中。更新.Meta.表。
d、清理父Region,通知HMaster将新的子Region迁移到其它RegionServer中。
Split过程核心代码如下:如果想了解有关Split的详细流程,可以参考:
http://punishzhou.iteye.com/blog/1233802

B、Compaction
当Hbase将MemStore中的内容flush到StoreFile中后,由于每次flush都会产生一个新的HFile文件。随着一次次的flush,HFile文件越来越多,当达到设定的阀值时,Hbase提供了Compaction特性,会通过此机制将HFile文件进行压缩。
Compaction机制分为两种方式:minor compactions和major compactions 。minor compactions是将相邻的一些小的HFile合并成一个稍大的HFile,表演一个多路合并的过程,其文件的数目由(hbase.hstore.compaction.min)指定;而major compactions会将一个Store中的所有HFile合并成一个HFile,并且在压缩的过程中会进行版本合并和删除过滤操作。比如对于那些同一个Cell中且同一个时间戳的数据,只保留最新的那个值,其他的值将被废弃。此外标记了删除样式的数据以及过期的数据也将被过滤。
其实Compaction就是将多个有序的HFile文件合并成一个有序的HFile文件的一个过程。它会创建一个StoreFileScanner来包装每一个StoreFile,然后再通过一个StoreFileScanner实例来组装StoreFile对应的StoreFileScanner列表。通过StoreFileScanner实例提供的next()和seek()方法获取每个storeFile中的数据,最后再将此数据append到一个新的HFile中。
5)HTablePool
如果用户每次发起一个请求时都创建一个HTable实例,如下创建方式:
Configuration conf = HBaseConfiguration.create();
HTable table = new HTable(conf, "testtable");
这种方式虽然可以满足要求,但对于请求数比较多的情况或者要求响应时间比较快的情况,如上创建HTable实例就比较落伍了。因为创建Htable是一个比较耗时的过程,此外,HTable并不能保证线程安全,在多线程处理下就可能产生莫名其妙的问题。
HBase提供了HTable池特性可以解决此问题。用户可以直接从HTable池中获取HTable实例。
1、可以通过如下构造函数来创建HTablePool实例,如下:
HTablePool()
HTablePool(Configuration config, int maxSize)
HTablePool(Configuration config, int maxSize,HTableInterfaceFactory tableFactory)
上面的第一个构造函数会默认获取classpath下的配置,并且创建无穷大的HTable个数。用户可以提供定制的创建的HTable实例的工厂来,这样创建的HTablePool中的HTable就是用户定制的
HTable实例。maxSize参数是指定HTable池中最大持有多少个HTable实例。比如如果此size为5,
而用户通过getTable获取了10次引用,那么当用户通过putTable方法将实例放回HTable池中时,只能放回5个实例,另外的5次将被忽略掉了。
2、创建HTablePool实例后,就可以通过getTable方法获取对应的表的HTable实例了。如下:
HTableInterface getTable(String tableName)
HTableInterface getTable(byte[] tableName)
3、当使用完HTable实例后,需要将HTable实例关闭,可以采用如下方法:
void closeTablePool(String tableName)
void closeTablePool(byte[] tableName)
void putTable(HTableInterface table)
closeTablePool(tableName)相当于直接将此Table实例关闭。建议使用此方法。PutTable(FilterBase)表示将此实例放回HTable池中供下次使用。建议不要使用此方法,目前此方法也在逐渐废弃。需要注意的是以上操作最好放到finally模块进行处理。
五、总结
A、总的来说Hbase因为其面向列族的key-value存储特性使得其拥有列式数据库的优势。分布式的Hbase应用是由客户端和服务端进程组成,通过HDFS作为其持久层,采用Zookeeper来完成集群的管理和状态监控协调服务。对于全表扫描和大数据的加载通过MapReduce来完成。Hbase无缝集成了Apache的这几大组件来实现可伸缩,面向列族的分布式存储系统。
B、Hbase是严格一致性的分布式存储系统,从两个方面来保证严格一致性问题:它提供行锁,但不提供多行锁和事务,保证了读写的原子性。此外Hbase数据存储支持多版本和时间戳的特性。
C、Hbase可以认为是BigTable的开源实现,但跟BigTable还是有很多区别。比如:Hbase的Coprocessors跟BigTable不同。Hbase支持服务器端的Filter以减少网络传输开销。此外Hbase支持可插拔的文件系统,目前文件系统是HDFS,BigTable是GFS。
D、Hbase通过实现服务器端的钩子(Coprocessors)来完成二级索引。这也是BigTable没有实现的。