背景
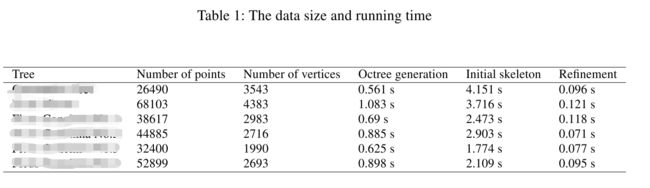
仍然是树重建实验,从点云里构建邻接图是一个时间开销比较大的步骤,对于几千个数据点而言,一个O(N^2)的建图过程大概会花几秒左右,建图属于下图中的 Initial Skeleton 步骤,然而我每次改动的代码都在 Refinement 步骤里,也就是说,每次我点击 Run 按钮时,都要重复生成一模一样的邻居图。
如果把生成的中间数据都缓存起来,重新Run 时直接读取缓存,这样就可以节省掉等待的时间了。
一开始的做法
我写了一个接口,用来表示缓存数据的容器。
import java.io.Serializable;
/**
* T 类型的数据用于缓存!
* @param
*/
public interface CachedData {
T getData();
void setData(T s);
Class getContentType();
boolean checkData();
}
我在实验代码使用 Spring IOC 容器来管理 Java Bean,每个实现了CachedData 接口的类会被我标注为组件(@Component),写 getData(),setData() 方法是为了在序列化和反序列化中读取和注入数据。
声明 getContentType() 是为了处理 Java 假泛型的问题,因为我需要在反序列化之后做类型检查,不能因为缓存读取错误就让程序挂掉,但是这里的类型是T,泛型类型只能在编译时获取,无法在运行时获取,我就写这么一个方法在具体实现类里面给出 T 的类型信息。
读 cache 的做法如下:
CachedData data = xxxx;
FileInputStream stream = new FileInputStream("xxxx.cache");
ObjectInputStream objStream = new ObjectInputStream(stream);
Serializable obj = (Serializable) objStream.readObject();
if (data.getContentType().isInstance(obj) {
data.setData(obj);
}
然后我就很欢喜地拿图1里面的第二条数据进行测试,结果让我大跌眼镜,直接从 cache 文件里读邻接图居然比在内存里计算要慢!
后来就查了一下Java序列化相关的 东西, Java 序列化虽然会把二进制数据写入文件,但是除了字段的值外,还会写入其他的信息比如类信息(class),如果class引用了其他的class,就会存下这些数据。实际上Java的序列化和反序列化本身并不是很高效的操作。
如果使用JSON进行序列化呢?有空我要尝试一下,据说比Serializable还要快一些。
其他的尝试(20180515)
搜索了一下 Java 的高效序列化库,看到了 kryo,Github上最新的版本是 4.0.2。这里把 Kryo 4.0.2,GSON 2.8.0,Oracle Java 8 Serializable 三者进行了对比,用比较学术的三线表展示一下对比结果:
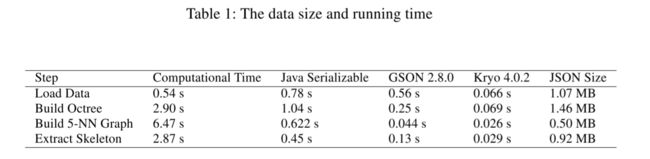
第一列,操作说明:
- Load Data 是我的实验代码中从类 ply 格式的点云文件中读取三维数据点操作。输出 List
格式的数据。 - Build Octree 是求出点云的Bounding Box,然后对包围盒递归划分八叉树,最后求出所有八叉树格子。输出 List
- Build 5-NN Graph,对数据点求5近邻图。输出 HashMap
- Extract Skeleton,求最短路径图,按测地距离决定结点先后顺序,连接成初始骨架。输出数据比较复杂。
这 4 个步骤都会输出一些数据,这个表就是对比 3 种序列化方法对输出数据的反序列化性能。几个步骤的数据大小不好衡量,我放出了 JSON 格式的数据大小(第六列)。
最后粗暴的对比结果就是:
Kryo 4.0.2 > GSON 2.8.0 > Oracle Java 8 Serializable