1 四个核心API
● Producer API
允许一个应用程序发布一串流式的数据到一个或者多个Kafka topic。
● Consumer API
允许一个应用程序订阅一个或多个topic ,并且对发布给他们的流式数据进行处理。
● Streams API
允许一个应用程序作为一个流处理器,消费一个或者多个topic产生的输入流,然后生产一个输出流到一个或多个topic中去,在输入输出流中进行有效的转换。
● Connector API
允许构建并运行可重用的生产者或者消费者,将Kafka topics连接到已存在的应用程序或者数据系统。比如,连接到一个关系型数据库,捕捉表(table) 的所有变更内容。
在Kafka中,客户端和服务器之间的通信是通过简单,高性能,语言无关的TCP协
议完成的。此协议已版本化并保持与旧版本的向后兼容性。Kafka提供多种语言客
户端。

2 Kafka API - producer
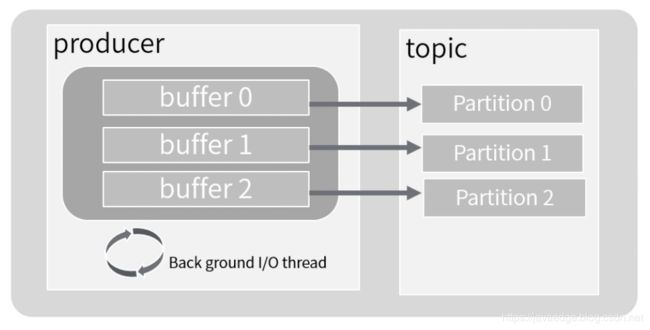
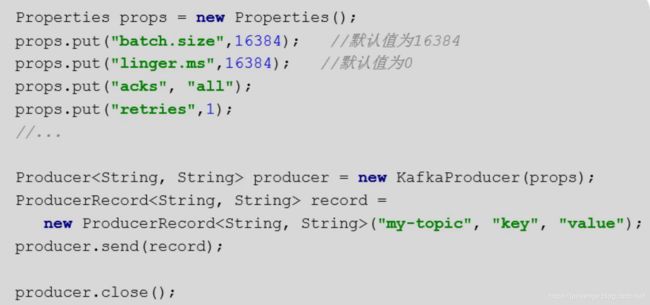
- Producer会为每个partition维护一个缓冲,用来记录还没有发送的数据,每个缓冲区大小用batch.size指定,默认值为16k.
- linger.ms为,buffer中的数据在达到batch.size前,需要等待的时间
- acks用来配置请求成功的标准
- send异步方法
3 Kafka API - Consumer
3.1 Simple Cnsumer
位于kafka.javaapi.consumer包中,不提供负载均衡、容错的特性每次获取数据都要指定topic、partition、offset、 fetchSize
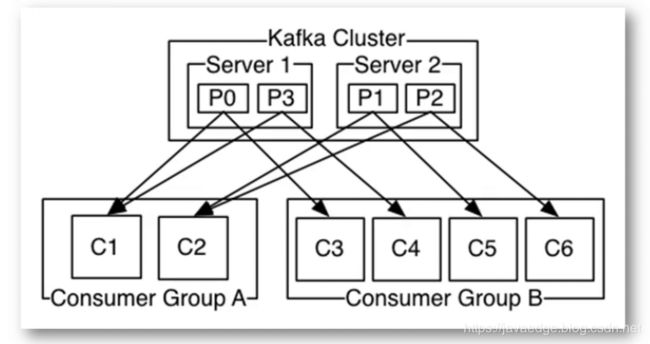
3.2 High-level Consumer
该客户端透明地处理kafka broker异常,透明地切换consumer的partition, 通过和broker交互来实现consumer group级别的负载均衡。
-
Group
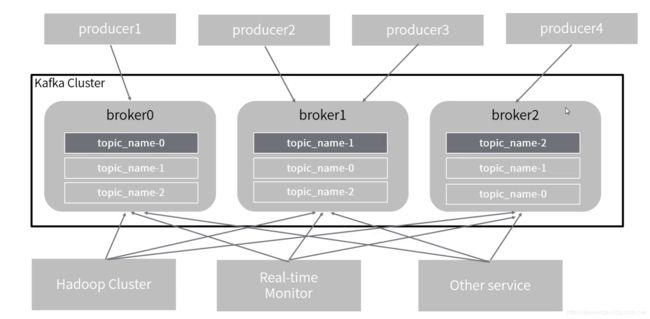
4 整体架构
5 使用场景
5.1 消息系统
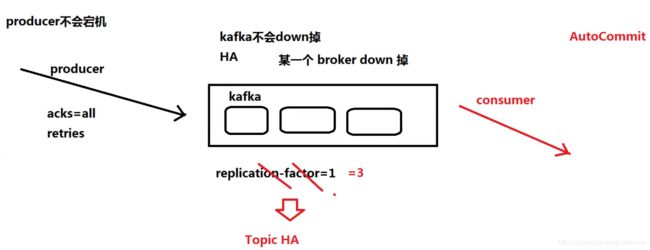
消息系统被用于各种场景,如解耦数据生产者,缓存未处理的消息。Kafka 可作为传统的消息系统的替代者,与传统消息系统相比,kafka有更好的吞吐量、更好的可用性,这有利于处理大规模的消息。
根据经验,通常消息传递对吞吐量要求较低,但可能要求较低的端到端延迟,并经常依赖kafka可靠的durable机制。
在这方面,Kafka可以与传统的消息传递系统(ActiveMQ 和RabbitMQ)相媲美。
5.2 存储系统
写入到kafka中的数据是落地到了磁盘上,并且有冗余备份,kafka允许producer等待确认,通过配置,可实现直到所有的replication完成复制才算写入成功,这样可保证数据的可用性。
Kafka认真对待存储,并允许client自行控制读取位置,你可以认为kafka是-种特殊的文件系统,它能够提供高性能、低延迟、高可用的日志提交存储。
5.3 日志聚合
日志系统一般需要如下功能:日志的收集、清洗、聚合、存储、展示。
Kafka常用来替代其他日志聚合解决方案。(官方说法,略有夸大嫌疑)
和Scribe、Flume相 比,Kafka提供同样好的性能、更健壮的堆积保障、更低的端到端延迟。
日志会落地,导致kafka做 日志聚合更昂贵
kafka可实现日志的清洗(需要编码)、聚合(可靠但昂贵,因为需要落地磁盘)、存储。
ELK是现在比较流行的日志系统。在kafka的配合 下才是更成熟的方案,kafka在ELK技术栈中,主要起到buffer的作用,必要时可进行日志的汇流。.
5.4 跟踪网站活动
kafka的最初始作用就是,将用户行为跟踪管道重构为一组实时发布-订阅源。
把网站活动(浏览网页、搜索或其他的用户操作)发布到中心topics中,每种活动类型对应一个topic。基于这些订阅源,能够实现一系列用例,如实时处理、实时监视、批量地将Kafka的数据加载到Hadoop或离线数据仓库系统,进行离线数据处理并生成报告。
每个用户浏览网页时都生成了许多活动信息,因此活动跟踪的数据量通常非常大。(Kafka实际应用)
5.5 流处理 - kafka stream API
Kafka社区认为仅仅提供数据生产、消费机制是不够的,他们还要提供流数据实时处理机制
从0.10.0.0开始, Kafka通过提供Strearms API来提供轻量,但功能强大的流处理。实际上就是Streams API帮助解决流引用中一些棘手的问题,比如:
- 处理无序的数据
- 代码变化后再次处理数据
- 进行有状态的流式计算
Streams API的流处理包含多个阶段,从input topics消费数据,做各种处理,将结果写入到目标topic, Streans API基于kafka提供的核心原语构建,它使用kafka consumer、 producer来输入、输出,用Kfka来做状态存储。
流处理框架: flink spark streamingJ Stortm、 Samza 本是正统的流处理框架,Kafka在流处理中更多的是扮演流存储的角色。