简介
| 数据模型 | 相关数据库 | 典型应用 | 优势 | 劣势 |
|---|---|---|---|---|
| key-value | Redis | 缓存 | 快速查询 | 存储数据缺乏结构化 |
| 列族 | Cassandra,Hbase | 分布式的文件系统,大规模的数据存储 | 易于分布式扩展 | 功能受限 |
| document | Mongo,CouchDB | 易用 | 可扩展性差 | |
| 图 | Neo4J | 社交网络 | 利用图结构相关算法 | 不易扩展 |
从NoSQL分类来说,Hbase和Cassandra是一类数据库,都是列族数据类型。
关于hbae和cassandra的对比可以看下为什么国内流行hbase,国外反而多用cassandra?,这里不再赘述。
名词介绍
表,行这些都是同关系型数据库一致
列族
列族顾名思义就是列的组合,wide-column这种数据类型都是根据BigTable模型实现的,它是一个稀疏的、多维结构映射。实际存储,就是列族的数据存储在一起,而不是像关系型数据库那样,一行存在一起。所以列族是需要提前定义的。
key-value,wide-column,json几种数据类型对比NoSQL概述-从Mongo和Cassandra谈谈NoSQL
region
region就是range partition,一组row key的范围组合。region是自动分裂的。一般大小是1GB-2GB,超过配置的大小,就进行分裂。
部署架构
Hbase的部署架构比较复杂。对于一个分布式数据库,集群架构一般有三个角色:路由节点、配置信息节点、分片数据节点。
有些数据库将这些功能都集成到同一个节点,这样的话扩容比较简单,单点比较少。如果拆分成不同节点话,部署起来就比较麻烦,扩容的话也比较麻烦,每个部分都有可能需要去扩容,好处是职责隔离,不会因为耦合造成整个节点的故障。以下是HBase的集群部署架构
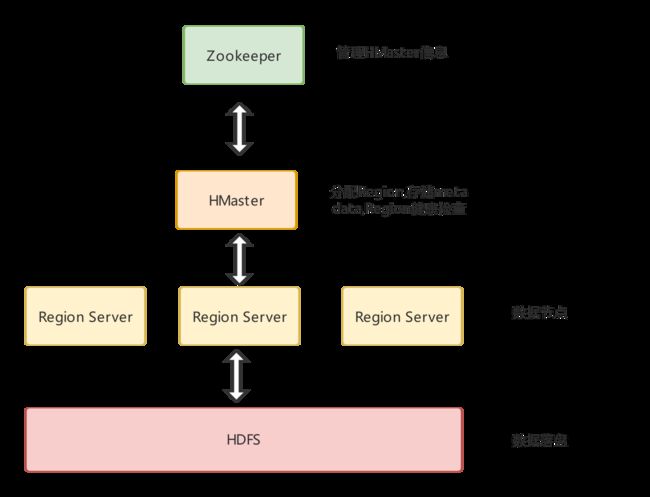
Hbase Master
Hbase是AP型分布式数据库,Master-Slave模式。Master负责管理所有的RegsionServer,也就是上面所说的配置信息节点这个角色。
记录了数据块HRegions属于哪个Region Server。当RegionServer增加或者下线时,需要进行HRegion的重新分配。一般为了可用性,Master节点个数要大于1,避免单点故障。
Region Server
Region Server负责数据的读写,数据存放在内存中,持续化需要和HDFS文件系统进行I/O交互。HBase是列族数据库,列的数据是存放在一起的,不同的行按照row key分布,存储在不同的Region Server中。
一般来说,扩容主要是扩容Region Server,因为主要是Region Server负责数据的读写。
Zookeeper
管理HMaster的信息
HDFS DataNode
数据的存储与备份。将数据存储在HDFS的一个显而易见的好处时,当集群Region Server发生变化时,增加或者减少时,不需要在节点间进行数据的复制,这大大减少了节点的上下线时间,和I/O消耗。
分片
Hbase的分片策略很简单,就是根据rowkey来分片,每个Region Server负责一组rowkey.
数据存储与维护
数据存储和Cassandra类似,先写log和内存,内存memstore也是LSM树,然后在flush到磁盘中,HFile,存储在HDFS中。
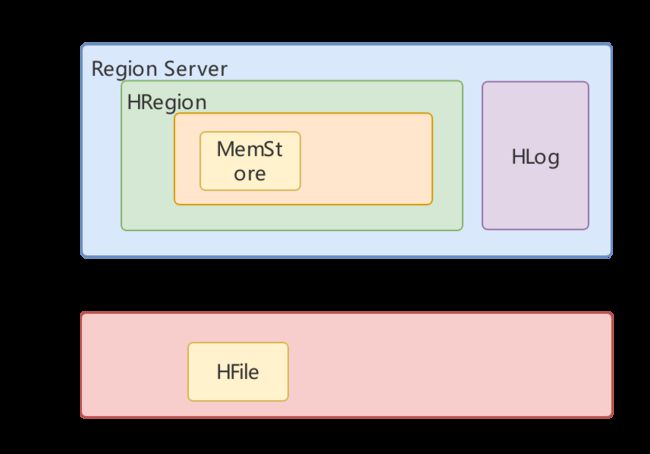
当HFile超过一定大小后,进行数据的分离。
读写分析
读操作
读操作一般在Hbase里面叫3跳,涉及到Hbase集群的3个角色。
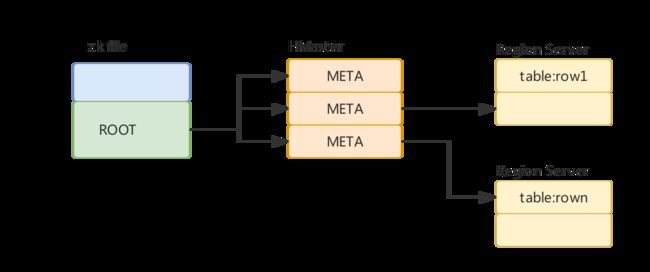
Meta table
HRegion的metadata信息都存储在.META表中,Region增加减少,这个信息都会更改。
Root table
Root table是用来记录META表信息的,存储在ZK中。
Hbase的读一般需要三跳
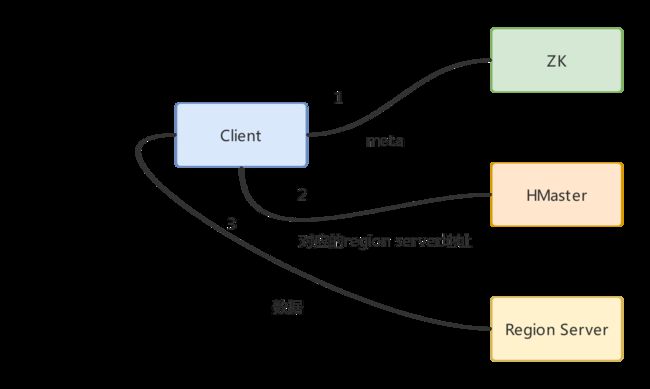
非常繁琐,所以路由信息一般cache到client,减少client与Hbase各个节点之间的交互。
写操作
没什么复杂的,和cassandra类似,不再赘述
总结
Hbase的集群部署架构模式和Mongo类似,多角色方式。所以读取数据的3跳也比较类似。单节点写入的话和Cassandra类似。
参考
https://www.iteblog.com/archives/2516.html