首先还是先说一下Zookeeper在Hadoop集群的作用,以前我们学习Hadoop伪分布式的时候没有用到Zookeeper是因为伪分布式只有一个NameNode,没有Active和Standby状态的两个NameNode之说,因此根本就不需要Zookeepr来帮我们自动切换。但是Hadoop真正的集群就不一样了,为了集群的高可靠性,Hadoop集群采用主备NameNode方式来工作,一个处于Active激活状态,另一个处于Standby备份状态,一旦激活状态的NameNode发生宕机,处于备份状态的NameNode需要立即顶替上来进行工作,从而对外提供持续稳定的服务。那么,Zookeeper便是为我们提供这种服务的。
在Hadoop1.0当中,集群当中只有一个NameNode,一旦宕机,服务便停止,这是非常大的缺陷,在Hadoop2.0当中,针对这一问题进行了优化,它对NameNode进行了抽象处理,它把NameNode抽象成一个NameService,一个NameService下面有两个NameNode,如下图所示。既然有两个NameNode,就需要有一个人来协调,谁来协调呢?那就是Zookeeper,Zookeeper有一个选举机制,它能确保一个NameService下面只有一个活跃的NameNode。因此Zookeeper在Hadoop2.0当中是非常重要的。
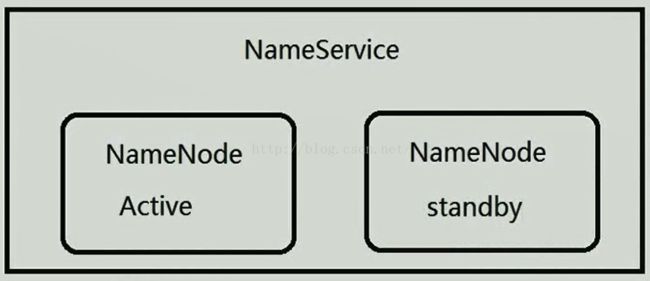
我们会疑问,在Hadoop集群当中一共就有两个NameNode吗?不是的,因为一个Hadoop集群每天面对的数据量是海量的,只有两个NameNode的话,内存会被写爆,因此NameService是可以水平扩展的,即一个集群有多个NameService,每个NameService有两个NameNode。NameService的名字依次是NameService1、NameService2...,由于DataNode是无限扩展的,因此NameService也是无限扩展的(当然不是说多的就没边了,合适的数量就好),如下图所示。
下面我看一张Hadoop高可靠性的工作原理图,其中NN代表的是NameNode,DN代表的是DataNode,ZK代表的是Zookeeper,我们发现这个集群当中有两个NameNode,一个处于Active状态,另一个处于Standby状态,NameNode是受Zookeeper控制的,但是又不是直接受Zookeeper控制,有一个中间件FailoverController(也就是ZKFC进程),每一个NameNode所在的机器都有一个ZKFC进程,ZKFC可以给NameNode发送一些指令,比如切换指令。同时ZKFC还负责监控NameNode,一旦它发现NameNode宕机了,它就会报告给Zookeeper,另一台NameNode上的ZKFC可以得到那一台NameNode宕机的信息,因为Zookeeper数据是同步的,因此它可以从ZK中得到这条信息,它得到这条信息之后,会向它控制的NameNode发送一条指令,让它由Standby状态切换为Active状态。具体原理是什么呢,刚开始的时候两个NameNode都正常工作,处于激活状态的NameNode会实时的把edits文件写入到存放edits的一个介质当中(如下图绿色的如数据库图形的东西),Standby状态的NameNode会实时的把介质当中的edits文件同步到它自己所在的机器。因此Active里面的信息与Standby里面的信息是实时同步的。FailoverController实时监控NameNode,不断把NameNode的情况汇报给Zookeeper,一旦Active状态的NameNode发生宕机,FailoverController就跟NameNode联系不上了,联系不上之后,FailoverController就会把Active宕机的信息汇报给Zookeeper,另一个FailoverController便从ZK中得到了这条信息,然后它给监控的NameNode发送切换指令,让它由Standby状态切换为Active状态。存放edits文件的方式可以使用NFS---网络文件系统,另一种是JournalNode,我们本课程便使用JournalNode来存储edits文件。DataNode连向的是NameService,DataNode既可以跟Active的NameNode通信又可以跟Standby的NameNode通信,一旦Active宕机,DataNode会自动向新的Active进行通信。

上面说了一大堆理论了,下面我们来开始搭建我们的Hadoop集群!,我们先来看一下我们的集群规划,我们打算布一个6台设备的集群,每台设备应该安装的软件、运行的进程如下图所示。其中DFSZKFailoverController是我们上图中介绍的FailoverContrlloer进程。我们可能会疑问,为什么NameNode和ResourceManager不放到一台设备上呢,是不能放到一起吗?不是的,之所以把它们分开是因为它们都是管理者(NameNode是HDFS的管理者,ResourceManager是Yarn的管理者)都十分耗资源,为了不让它们争抢资源,因此最好把它们分别布置到不同的设备上。NodeManager和DataNode最好在一台设备上,因为NodeManager以后要运行MapReduce程序,运行程序需要数据,数据从本地取最好,而DataNode刚好就是用来存储数据的。JournalNode是用来存储共享的edits文件的。
说明:
在hadoop2.0中通常由两个NameNode组成,一个处于active状态,另一个处于standby状态。Active NameNode对外提供服务,而Standby NameNode则不对外提供服务,仅同步active namenode的状态,以便能够在它失败时快速进行切换。
hadoop2.0官方提供了两种HDFS HA的解决方案,一种是NFS,另一种是QJM。这里我们使用简单的QJM。在该方案中,主备NameNode之间通过一组JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。通常配置奇数个JournalNode
这里还配置了一个zookeeper集群,用于ZKFC(DFSZKFailoverController)故障转移,当Active NameNode挂掉了,会自动切换Standby NameNode为Active状态

接下来我们便真正开始部署集群了,首先我们需要给所有的设备安装jdk了,关于jdk安装,我这里就不再详细说明了,大家可以参考:http://blog.csdn.net/u012453843/article/details/52422736这篇博客来安装。hadoop的安装我们采取先先安装一台并且配置好之后,然后再拷贝到其它设备的方式来进行。其中Hadoop的安装过程大家可以参考:http://blog.csdn.net/u012453843/article/details/52431742这篇博客来安装,注意:参考这篇博客先不要配置hadoop因为我们集群的配置跟当时学习的时候的配置不一样。Hadoop我们使用64位的Hadoop-2.2.0.tar.gz,大家可以到:http://pan.baidu.com/s/1hsDfFso来下载。
** 安装完hadoop之后我们来配置HDFS,(hadoop2.0所有的配置文件都在$HADOOP_HOME/etc/hadoop目录下)**
** 我们将Hadoop添加到环境变量中,如下所示,然后先按ESC键,再按Shift+ZZ(按两次Z)保存退出。**
[root@itcast01 hadoop]# vim /etc/profile
:"$1":)
;;
*)
if [ "$2" = "after" ] ; then ---------------------->中间只截取了一部分信息
PATH=$PATH:$1
else
PATH=$1:$PATH
fi
esac
}
unset i
unset -f pathmunge export JAVA_HOME=/usr/java/jdk1.7.0_80
export HADOOP_HOME=/itcast/hadoop-2.2.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
** 安装好了hadoop,接下来我们开始配置hadoop,我们一共需要配置6个文件,如下图所示。**

第一个文件:hadoop.env.sh
说明:我们修改java的导出路径,export JAVA_HOME=/usr/java/jdk1.7.0_80,然后先按ESC键,再按Shift+ZZ(按两次Z)保存退出。第一个文件就修改完了。

第二个文件:core-site.xml
说明:第一个property配置的的是nameservice,在以前伪分布式的时候配置的是类如:
[root@itcast01 hadoop]# **vim core-site.xml**
**
fs.defaultFS
hdfs://ns1
hadoop.tmp.dir
/itcast/hadoop-2.2.0/tmp
ha.zookeeper.quorum
itcast04:2181,itcast05:2181,itcast06:2181
**
第三个文件:hdfs-site.xml
说明:
** 我们在
配置中有一个是关于配置隔离机制方法的配置,第一种方法是sshfence,这个配置的作用是什么呢?我们举例来说明,假如现在Active状态的NameNode出现了问题,但是进程却没有宕掉,这时FailoveController监测到Active状态的NameNode出现了问题并向ZK汇报,另外一个FailoverController可以从ZK中得到同步过来的相关信息,然后这个FailoverController便向它监控的NameNode发送指令,让它由Standby状态切换为Active状态,但这时就有问题了,出现问题的那个NameNode的状态依然是Active,这时又要来一个Active状态的NameNode,为了保证一个NameService下只有一个Active的NameNode,没有问题的NameNode会向有问题的NameNode发送SSH命令,把有问题的NameNode的进程给kill掉,这样就保证没问题的NameNode可以正常切换到Active状态。第二种方法是通过shell脚本的方法(shell(/bin/true)),这种方法适用的场景是什么呢?我们在上面不是有一张关于Hadoop高可靠性工作原理的图嘛,从图中可以看出FailoverController和它监测的NameNode是在同一台设备上的,假如这一台设备给宕掉了,那么FailoverController和NameNode都宕掉了,FailoverController也就不会再向ZK汇报NameNode的状态了,那么另外一个FailoverController长时间无法从ZK中得到Active的NameNode的信息,过了超时时长后,它会调用一个shell脚本,如果这个脚本返回true,那么它就发送命令给它监控的NameNode,让它由Standby状态切换为Active状态。
**[root@itcast01 hadoop]# vim hdfs-site.xml**
**
dfs.nameservices
ns1
dfs.ha.namenodes.ns1
nn1,nn2
dfs.namenode.rpc-address.ns1.nn1
itcast01:9000
dfs.namenode.http-address.ns1.nn1
itcast01:50070
dfs.namenode.rpc-address.ns1.nn2
itcast02:9000
dfs.namenode.http-address.ns1.nn2
itcast02:50070
dfs.namenode.shared.edits.dir
qjournal://itcast04:8485;itcast05:8485;itcast06:8485/ns1
dfs.journalnode.edits.dir
/itcast/hadoop-2.2.0/journal
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.ns1
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
**
**第四个文件:mapred-site.xml**
**说明:在hadoop的目录下没有mapred-site.xml,而是有一个mapred-site.xml.template,我们需要先修改mapred-site.template文件为mared-site.xml**
**[root@itcast01 hadoop]# mv mapred-site.xml.template mapred-site.xml
[root@itcast01 hadoop]# ls
capacity-scheduler.xml hadoop-env.cmd hadoop-policy.xml httpfs-signature.secret mapred-env.sh ssl-client.xml.example yarn-site.xml
configuration.xsl hadoop-env.sh hdfs-site.xml httpfs-site.xml mapred-queues.xml.template ssl-server.xml.example
container-executor.cfg hadoop-metrics2.properties httpfs-env.sh log4j.properties mapred-site.xml yarn-env.cmd
core-site.xml hadoop-metrics.properties httpfs-log4j.properties mapred-env.cmd slaves yarn-env.sh
[root@itcast01 hadoop]#vim mapred-site.xml**
**
mapreduce.framework.name
yarn
**
**第五个文件:yarn-site.xml**
**[root@itcast01 hadoop]# vim yarn-site.xml**
**
yarn.resourcemanager.hostname
itcast03
yarn.nodemanager.aux-services
mapreduce_shuffle
**
第六个文件:slaves
说明:slaves文件中存放我们的奴隶(被管理者)的主机名,我们在集群规划的那张图中可以知道itcast04、itcast05、itcast06上有DataNode和NodeManager,这两种都是被管理者的身份,因此我们需要配置的是itcast04、itcast05、itcast06,如下所示。
[root@itcast01 hadoop]# vim slaves
itcast04
itcast05
itcast06
配置完上面六个文件之后,我们接下来把我们需要检查itcast04、itcast05、itcast06上的Zookeeper是否正常启动起来了,如下所示,发现确实都正常。
[root@itcast04 bin]# ./zkServer.sh status
JMX enabled by default
Using config: /itcast/zookeeper-3.4.5/bin/../conf/zoo.cfg
Mode: follower
[root@itcast04 bin]#
[root@itcast05 itcast]# cd zookeeper-3.4.5/bin
[root@itcast05 bin]# ./zkServer.sh status
JMX enabled by default
Using config: /itcast/zookeeper-3.4.5/bin/../conf/zoo.cfg
Mode: leader
[root@itcast05 bin]#
[root@itcast06 itcast]# cd zookeeper-3.4.5/bin/
[root@itcast06 bin]# ./zkServer.sh status
JMX enabled by default
Using config: /itcast/zookeeper-3.4.5/bin/../conf/zoo.cfg
Mode: follower
[root@itcast06 bin]#
我们再看看itcast04的zookeeper根目录,防止一些不必要的文件干扰,我们登录到zookeeper客户端,发现zookeeper根目录下有个hadoop123文件,我们使用命令rmr /hadoop123来删除它,删除之后我们发现zookeeper根目录下只有zookeeper这一个文件了。如下图所示。
接下来我们把在这台机器上配置的hadoop复制到其它机器上,为了拷贝的快速一点,我们把hadoop-2.2.0的share目录下的doc文件夹给删掉,因为这个文件夹下有很多阅读文件,我们在Linux系统上基本上是用不着的,删掉它之后有利于我们加快拷贝的速度。如下所示。
[root@itcast01 hadoop]# cd /itcast/hadoop-2.2.0/share
[root@itcast01 share]# ls
doc hadoop
[root@itcast01 share]# rm -rf doc/
[root@itcast01 share]# ls
hadoop
[root@itcast01 share]#
在拷贝之前我们先看看itcast02的根目录下是否有itcast文件夹了,我们发现没有itcast。
[root@itcast02 /]# ls
bin boot dev etc home lib lib64 lost+found media mnt opt proc root sbin selinux srv sys tmp usr var
[root@itcast02 /]#
拷贝前我们还需要在每台设备的/etc/hosts的文件配置主机名和IP的映射关系(**注意,要给每台设备都配置一样的映射**)
[root@itcast01 share]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.8.10 itcast01
192.168.8.20 itcast02
192.168.8.30 itcast03
192.168.8.40 itcast04
192.168.8.50 itcast05
192.168.8.60 itcast06
接下来我们便开始从itcast01上通过ssh的方式向itcast02上拷贝hadoop目录了,拷贝前先确认itcast02根目录下没有itcast文件夹,有就先删除。使用命令**scp -r /itcast/ root@itcast02:/**之后会让我们输入yes/no,我们输入yes并按回车,然后会让你输入itcast02的root用户的密码,然后就开始拷贝了,如下图所示。
[root@itcast01 share]# scp -r /itcast/ root@itcast02:/
The authenticity of host 'itcast02 (192.168.8.20)' can't be established.
RSA key fingerprint is b4:aa:39:16:08:ef:bf:79:2c:5a:60:fc:32:ac:b6:13.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'itcast02,192.168.8.20' (RSA) to the list of known hosts.
root@itcast02's password:
拷贝完之后,我们到itcast02的根目录下查看是不是已经有了itcast目录了,发现确实已经有itcast文件夹了,而且我们到itcast目录下后可以看到hadoop-2.2.0的文件夹,说明我们刚才的拷贝成功了!
[root@itcast02 /]# ls
bin boot dev etc home itcast lib lib64 lost+found media mnt opt proc root sbin selinux srv sys tmp usr var[root@itcast02 /]# cd itcast
[root@itcast02 /]# cd itcast
[root@itcast02 itcast]# ls
hadoop-2.2.0
然后我们再以同样的方法把itcast01上的/itcast目录拷贝给itcast03,当然也需要先查看一下itcast03根目录下是否已经有itcast文件夹了,如果已经有了那么就先删掉,确保在拷贝之前itcast03根目录下没有itcast文件夹。
[root@itcast01 share]# scp -r /itcast/ root@itcast03:/
The authenticity of host 'itcast03 (192.168.8.30)' can't be established.
RSA key fingerprint is b4:aa:39:16:08:ef:bf:79:2c:5a:60:fc:32:ac:b6:13.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'itcast03,192.168.8.30' (RSA) to the list of known hosts.
root@itcast03's password:
拷贝完之后我们再到itcast03上查看根目录下是否有我们刚才拷贝的itcast文件夹。发现已经有了。
[root@itcast03 /]# ls
bin boot dev etc home itcast lib lib64 lost+found media mnt opt proc root sbin selinux srv sys tmp usr var
[root@itcast03 /]# cd itcast/
[root@itcast03 itcast]# ls
hadoop-2.2.0
[root@itcast03 itcast]#
我们在给itcast04拷贝的时候,需要注意,因为itcast04上已经有itcast这个文件夹了,如下所示。
[root@itcast04 bin]# cd /
[root@itcast04 /]# ls
bin boot dev etc home itcast lib lib64 lost+found media mnt opt proc root sbin selinux srv sys tmp usr var
[root@itcast04 /]#
因此我们在给itcast04拷贝前也需要先确认itcast04的itcast目录下是否已经有hadoop-2.2.0的文件夹了呢?如果已经有了,就先删除掉。也就是说我们拷贝的只是itcast01的hadoop-2.2.0文件夹到itcast04的根目录下的itcast文件夹下。
[root@itcast01 share]# scp -r /itcast/hadoop-2.2.0/ root@itcast04:/itcast/
The authenticity of host 'itcast04 (192.168.8.40)' can't be established.
RSA key fingerprint is b4:aa:39:16:08:ef:bf:79:2c:5a:60:fc:32:ac:b6:13.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'itcast04,192.168.8.40' (RSA) to the list of known hosts.
root@itcast04's password:
拷贝完之后,我们到itcast04上查看itcast目录下是否有了我们刚才拷贝的hadoop-2.2.0
[root@itcast04 itcast]# ls
zookeeper-3.4.5-------->拷贝前****并没有hadoop-2.2.0
[root@itcast04 itcast]# ls
hadoop-2.2.0 zookeeper-3.4.5 -------->拷贝完之后发现已经有hadoop-2.2.0了。
[root@itcast04 itcast]#
同理,我们再拷贝到itcast05和itcast06上。
接下来我们配置环境变量,我们先来看看itcast01上的/etc/profile文件是否已经配置好了,如下所示,发现我们已经配置好了,**这还不行,因为虽然配置好了,但是还没有生效,我们使用命令:source /etc/profile来使配置生效。**
[root@itcast01 share]# more /etc/profile
/etc/profile
unset i
unset -f pathmunge
export JAVA_HOME=/usr/java/jdk1.7.0_80
export HADOOP_HOME=/itcast/hadoop-2.2.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
接下来我们把itcast01上的profile文件拷贝到其它设备上,使用的命令如scp /etc/profile itcast02:/etc,如下所示。

拷贝完之后,我们到itcast02上看一下/etc/profile文件是否已经配置好了,如下所示,发现已经OK了。同样,我们再看看其它设备的该文件是否OK了。**请注意:要记得使用命令source /etc/profile来使每台设备的配置生效。**
[root@itcast02 ~]more /etc/profile
unset i
unset -f pathmunge
export JAVA_HOME=/usr/java/jdk1.7.0_80
export HADOOP_HOME=/itcast/hadoop-2.2.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
[root@itcast02 etc]#
我们发现我们在拷贝的时候老是让我们输入密码,这是因为没有配置SSH免密码登录,接下来我们先配置下免密码登录
#首先要配置itcast01到itcast02、itcast03、itcast04、itcast05、itcast06的免密码登陆
#在itcast01上生产一对钥匙,命令是ssh-keygen -t rsa,过程需要敲三次回车就可以了,如下图所示。
秘钥生成成功后,itcast01上.ssh目录下的文件有什么变化呢?如下图所示,我们发现相比开始,这个文件夹下多出了两个文件,分别是id_rsa和id_rsa.pub分别代表私钥和公钥。如下所示
[root@itcast01 ~]# ls .ssh
id_rsa id_rsa.pub known_hosts
[root@itcast01 ~]#
接下来我们将itcast01的公钥拷贝到其他节点,包括自己 ,如下所示。
[root@itcast01 ~]# ssh-copy-id itcast01
The authenticity of host 'itcast01 (192.168.8.10)' can't be established.
RSA key fingerprint is b4:aa:39:16:08:ef:bf:79:2c:5a:60:fc:32:ac:b6:13.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'itcast01,192.168.8.10' (RSA) to the list of known hosts.
root@itcast01's password:
Now try logging into the machine, with "ssh 'itcast01'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
[root@itcast01 ~]# ssh-copy-id itcast02
root@itcast02's password:
Now try logging into the machine, with "ssh 'itcast02'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
[root@itcast01 ~]# ssh-copy-id itcast03
root@itcast03's password:
Now try logging into the machine, with "ssh 'itcast03'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
[root@itcast01 ~]# ssh-copy-id itcast04
root@itcast04's password:
Now try logging into the machine, with "ssh 'itcast04'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
[root@itcast01 ~]# ssh-copy-id itcast05
root@itcast05's password:
Now try logging into the machine, with "ssh 'itcast05'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
[root@itcast01 ~]# ssh-copy-id itcast06
root@itcast06's password:
Now try logging into the machine, with "ssh 'itcast06'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
[root@itcast01 ~]#
#配置itcast03到itcast04、itcast05、itcast06的免密码登陆
#在itcast03上生产一对钥匙,使用命令: ssh-keygen -t rsa,如下图所示。
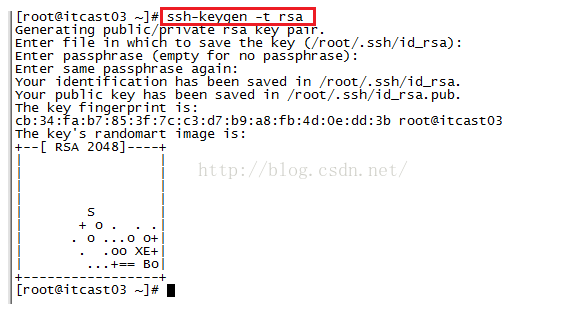
#将公钥拷贝到其他节点, 使用的命令:ssh-coyp-id itcast04,ssh-coyp-id itcast05, ssh-coyp-id itcast06,如下图所示。

#注意:两个namenode之间要配置ssh免密码登陆,别忘了配置itcast02到itcast01的免登陆
在itcast02上生产一对钥匙,使用命令: ssh-keygen -t rsa。接着使用命令ssh-coyp-id itcast01拷贝到itcast01上,如下图所示。
[图片上传失败...(image-f72590-1519890869338)]
**接下来进入最重要的环节**,我们必须按照如下步骤挨个进行操作,顺序不能颠倒,否则会有问题
第一步:启动zookeeper集群(分别在itcast04、itcast05、itcast06上启动zk,上面我们已经启动过zookeeper了,就不用重启了。
cd /itcast/zookeeper-3.4.5/bin/
./zkServer.sh start
查看状态:一个leader,两个follower
./zkServer.sh status
第二步:启动journalnode(注意:根据我们集群的规划,我们需要在itcast04、itcast05、itcast06上启动JournalNode,在hadoop的sbin目录下,有hadoop-daemon.sh和hadoop-daemons.sh命令,第一条命令是单独启动某台设备的某个进程,第二条命令是启动所有设备的某个进程,既然我们的集群只有3台设备有JournalNode,所以我们在itcast04、itcast05、itcast06上分别启动journalnode)如下图所示。我们启动journalnode使用的命令是./hadoop-daemon.sh start journalnode
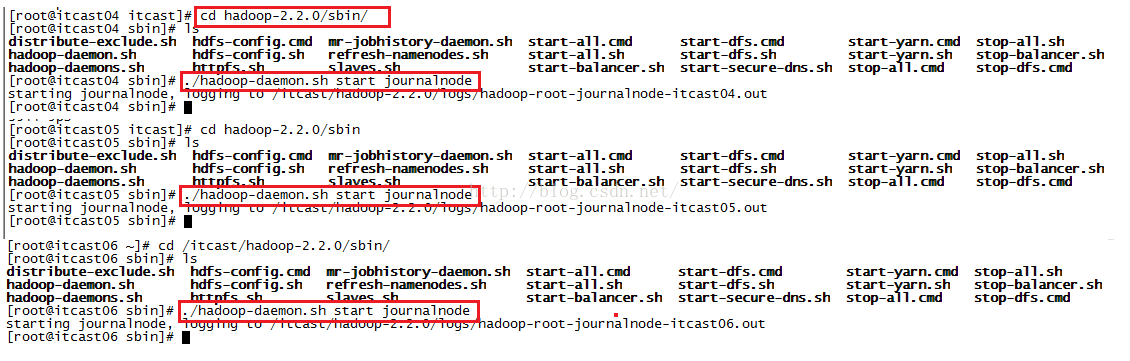
运行jps命令检验,itcast04、itcast05、itcast06上多了JournalNode进程,从下图可以看到三台设备都多了一个JournalNode进程。
[图片上传失败...(image-afc182-1519890869338)]
第三步:格式化HDFS
在itcast01上执行命令: hdfs namenode -format,如下图所示,当我们看到类似/itcast/hadoop-2.2.0/tmp/dfs/name has been successfully formatted这样的描述信息时说明格式化成功了。

格式化之后,我们到hadoop-2.2.0目录下,可以看到tmp这个目录,这个目录会存放fsimage和edits文件。

我们再来看一下itcast02的hadoop-2.2.0目录下是否有tmp文件,如下图所示,发现,没有tmp这个文件。

我们在说Hadoop的高可靠性原理图时说过两个NameNode实时共享edits文件,我们的itcast01和itcast02上开启的是NameNode,itcast02上没有tmp这个文件,因此我们从Itcast01上拷贝到itcast02。

拷贝完之后,我们到itcast02上看一下是否已经有tmp文件夹了,如下图所示,发现确实已经有了。

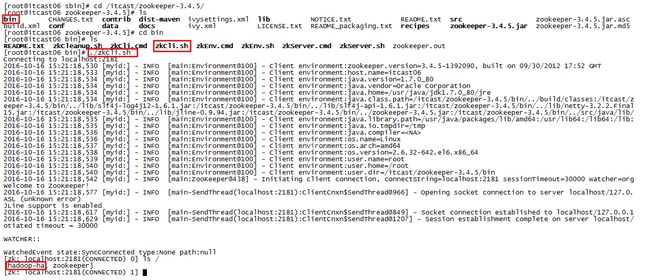
第四步:格式化ZK(在itcast01上执行即可)
hdfs zkfc -formatZK

格式化ZK之后我们到itcast06的zookeeper根目录下查看,查看是否多了文件,我们发现确实多了一个hadoop-ha的文件,如下图所示。
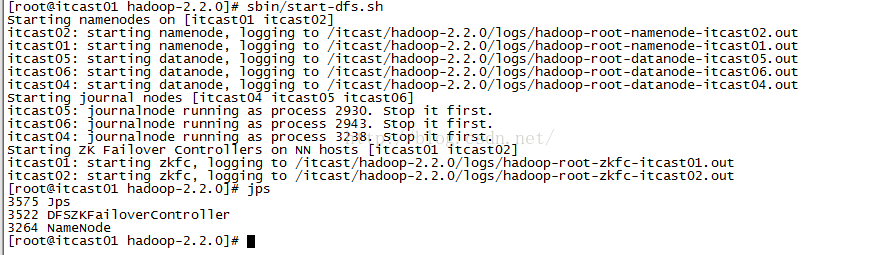
第五步:启动HDFS(在itcast01上执行)使用命令: sbin/start-dfs.sh,执行完命令之后,我们查看进程,发现NameNode和DFSZKFailoverController已经启动成功了。
第六步:启动YARN(#####注意#####:是在itcast03上执行start-yarn.sh,把namenode和resourcemanager分开是因为性能问题,因为他们都要占用大量资源,所以把他们分开了,他们分开了就要分别在不同的机器上启动)
sbin/start-yarn.sh

启动完yarn之后,我们到itcast04上查看进程,发现确实有了NodeManager,而且itcast05和itcast06上也有了NodeManager。

可以看到itcast01、itcast02的进程有NameNode、DFSZKFailoverController两个进程,itcast03的进程是ResourceManager,itcast04、itcast05、itcast06的进程有DataNode、NodeManager、JournalNode、QuorumPeerMain四个进程,完全符合我们设计的集群要求。
至此,Hadoop集群便搭建完了!!!
注意:如果您配置没有成功,请检查是否符合下面几点
1.Hadoop-2.2.0.tar.gz我们使用64位的,下载地址:http://pan.baidu.com/s/1hsDfFso****
****2.配置六个文件的时候,配置的内容是否按Tab进行缩进了,一级缩进一个Tab的距离。(请不要直接粘贴我博客的配置内容,因为它默认是以空格来缩进的,大家可以从http://download.csdn.net/detail/u012453843/9662854这个地址下载Hadoop-2.2.0集群搭建文件,文件中有详细配置信息,而且格式是以Tab缩进的)****
****我第一次搭建的时候就没有成功,后来在上面两点上注意了一下,就搭建成功了,希望能够帮到大家。****