1、 前面在伪分布模式下已经创建了一台机器,为了统一命名,hostname更名为hadoop01、然后再克隆2台机器:hadoop02、 hadoop03;将第一台机器hadoop01上的伪分布停止,创建一个新目录,重新安装hadoop,解压后,再分发到其他两台机器,具体按下面的步骤操作。
2、 服务器功能规划
| hadoop01 |
hadoop02 |
hadoop03 |
| 192.168.100.129 |
192.168.100.130 |
192.168.100.131 |
| NameNode |
ResourceManager |
|
| DataNode |
DataNode |
DataNode |
| NodeManager |
NodeManager |
NodeManager |
| HistoryServer |
|
|
|
|
|
SecondaryNameNode |
3、 按照上表设置3台机器的IP地址、和hostname。关于设置IP和本地主机名,可以参考《详细的Hadoop的入门教程-单机模式 Standalone Operation》
4、 在hadoop01上创建完全分布模式的目录/opt/modules/app,解压hadoop、设置环境变量
(1) 解压命令:tar –zxvf hadoop-3.2.1.tar.gz –C /opt/modules/app
(2) 执行命令vi /etc/profile设置JAVA_HOME和HADOOP_HOME环境变量,
增加1行内容:
export HADOOP_HOME=/opt/modules/app/hadoop-3.2.1
修改1行内容:
export PATH=$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH
执行命令source /etc/profile 让设置生效
$ source /etc/profile
5、 配置$HADOOP_HOME/etc/hadoop/core-site.xml,设置虚拟目录、文件分布式系统的地址、name和data的目录
fs.defaultFS hdfs://hadoop01:9000 hadoop.tmp.dir /opt/modules/app/hadoop-3.2.1/data/tmp dfs.name.dir /opt/modules/app/hadoop-3.2.1/data/tmp/dfs/name dfs.data.dir /opt/modules/app/hadoop-3.2.1/data/tmp/dfs//data
- fs.defaultFS 为 NameNode 的地址,hadoop01为NameNode。
- hadoop.tmp.dir为hadoop的临时目录,默认情况下,NameNode和DataNode的数据文件都会存在这个目录下的对应子目录下。应该保持该文件目录是存在的,如果不存在先创建。若不指定,格式化后会自动创建到root根目录下。
- dfs.name.dir是NameNode的数据目录
- dfs.data.dir是DataNode的数据目录
6、 配置$HADOOP_HOME/etc/hadoop/hdfs-site.xml、设定SecondaryNameNode的地址
dfs.namenode.secondary.http-address hadoop03:50090
dfs.namenode.secondary.http-address 是指定 secondaryNameNode 的 http 访问地址和端口号。
7、 配置$HADOOP_HOME/etc/hadoop/workers,在文件中各行添加每台机器的hostname或IP; (hadoop2.x版本的文件名叫slaves),该文件指定了HDFS上都有哪些节点。
hadoop01
hadoop02
hadoop03
8、 配置$HADOOP_HOME/etc/hadoop/yarn-site.xml,设置哈hadoop02为ResourceManager,开启日志。
yarn.nodemanager.aux-services mapreduce_shuffle yarn.resourcemanager.hostname hadoop02 yarn.log-aggregation-enable true yarn.log-aggregation.retain-seconds 86400
- yarn.resourcemanager.hostname这个指定 resourcemanager 服务器指向。
- yarn.log-aggregation-enable是配置是否启动日志聚集功能。
- yarn.log-aggregation.retain-seconds是日志在HDFS上保存多长时间,单位秒。
9、 配置$HADOOP_HOME/etc/hadoop/mapred-site.xml,设置hadoop01为历史服务器。
mapreduce.framework.name yarn mapreduce.jobhistory.address hadoop01:10020 mapreduce.jobhistory.webapp.address hadoop01:19888
- mapreduce.framework.name设置mapreduce运行在yarn上。
- mapreduce.jobhistory.address设置mapreduce的历史服务器安装在hadoop01上。
- mapreduce.jobhistory.webapp.address是历史服务器的Web地址和端口。
10、 设置SSH无密码登录,在hadoop集群中各机器之间需要相互通过ssh访问,所以要实现ssh免密码登录:
(1) 在hadoop01、hadoop02、hadoop03上生成公钥和私钥:
执行命令ssh-keygen -t rsa 产生密钥,位于~./.ssh文件夹中(没有则自动创建),输入命令后一直回车。
$ ssh-keygen -t rsa
(2) 派发公钥ssh-copy-id
$ ssh-copy-id hadoop01 $ ssh-copy-id hadoop02 $ ssh-copy-id hadoop03
(3) 同样在hadoop02、hadoop03设置到其它机器的上ssh免密登录,在两台机器上生成公钥和私钥,并将公钥分发到三台机器上。
11、 分发hadoop文件,首先在hadoop02和hadoop03上创建目录/opt/modules/app。在hadoop01上向其他两台机器Scp分发hadoop,hadoop 根目录下的 share/doc 目录是存放的 hadoop 的文档,文件相当大,建议在分发之前将这个目录删除掉,可以节省硬盘空间并能提高分发的速度。
$ du –sh /opt/modules/app/hadoop-3.2.1/ hadoop02:/opt/modules/app/ $ du –sh /opt/modules/app/hadoop-3.2.1/ hadoop03:/opt/modules/app/
12、 在 NameNode 机器hadoop01上执行格式化
$ /opt/modules/app/hadoop-3.2.1/bin/hdfs namenode –format
如果需要重新格式化 NameNode,需要先将原来 NameNode 和 DataNode 下的文件全部删除
13、 启动hadoop集群:
(1) 启动HDFS:在hadoop01上运行:sbin/start-dfs.sh,启动后,jps查看下进程

- $HADOOP_HOME/sbin/start-dfs.sh 启动
- $HADOOP_HOME/sbin/stop-dfs.sh 停止
- 需要在启动和停止两个文件中开头添加:
HDFS_DATANODE_USER=root HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root YARN_RESOURCEMANAGER_USER=root YARN_NODEMANAGER_USER=root
(2) 启动YARN:在hadoop01上运行 sbin/start-yarn.sh,启动后,jps查看下进程

- $HADOOP_HOME/sbin/start-yarn.sh 启动
- $HADOOP_HOME/sbin/stop-yarn.sh 停止
- 需要在启动和停止两个文件中开头添加:
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
(3) 在hadoop02启动ResourceManager,运行 sbin/yarn-daemon.sh start resourcemanager,jps查看进程

- $HADOOP_HOME/sbin/yarn-daemon.sh start resourcemanager 启动
- $HADOOP_HOME/sbin/yarn-daemon.sh stop resourcemanager 停止
(4) 启动日志服务器:在hadoop01上运行 sbin/mr-jobhistory-daemon.sh start historyserver,启动后jps查看一下进程

- $HADOOP_HOME/sbin/mr-jobhistory-daemon.sh start historyserver 启动
- $HADOOP_HOME/sbin/mr-jobhistory-daemon.sh stop historyserver 停止
14、 查看一下HDFS的WEB页面 http://hadoop01:9870

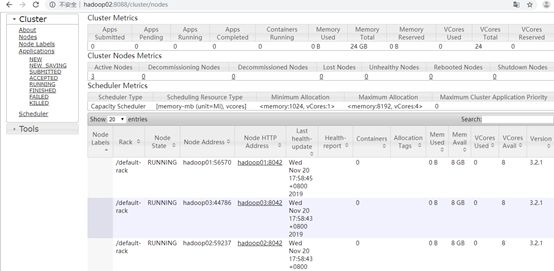
15、 访问查看yarn Web下http://hadoop02:8088/cluster ,集群中有3个节点。