Java - Lambda 表达式与 Stream 接口
sschrodinger
2019/10/28
引用
java 8 Stream 原理深度解析 - Dorae
深入理解 Java Stream 流水线 - CarpenterLee
Lambda 表达式
lamda 表达式提供了丰富的语法糖,简化自己的程序,并优化自己的程序速度。
Lambda 实例
Lambda 表达式仅支持函数式编程接口,所谓函数式接口,指的是只有一个抽象方法的接口。
函数式接口可以被隐式转换为 Lambda 表达式。函数式接口可以用 @FunctionalInterface 注解标识。
Java 中有大量的函数式编程接口,如 Runnable、Callable 等。
JDK 1.8 之后,又添加了一个 Java 包存放函数式接口,如下:
// java.util.function.*
public interface Consumer{
/**
* 函数式接口,无返回值,接受一个参数,代表一个消费者
**/
void accept(T t);
// ...
}
public interface Supplier{
/**
* 函数式接口,有返回值,无参数,代表一个生产者
**/
T get();
}
public interface Function{
/**
* 函数式接口,有返回值,有参数
**/
R apply(T t);
// ...
}
// ...
举个例子,当我们需要创建一个线程时,标准的写法如下(使用匿名内部类):
public class Demo {
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("hello,world");
}
}).start();
}
}
lambda 表达式可以更加简略的写代码,如上代码的等效 lambda 表达式如下:
public class Demo {
public static void main(String[] args) {
new Thread
(
() -> { System.out.println("hello,world");}
).start();
}
}
Lambda 语法
在 Java 中,使用 (paramters) -> expression; 或者 (paramters) -> {statements;} 来定义 lambda 表达式。其中,有部分写法可以省略,规则如下:
note
- 可选类型声明:不需要声明参数类型,编译器可以统一识别参数值。
- 可选的参数圆括号:一个参数无需定义圆括号,但多个参数需要定义圆括号。
- 可选的大括号:如果主体包含了一个语句,就不需要使用大括号。
- 可选的返回关键字:如果主体只有一个表达式返回值则编译器会自动返回值,大括号需要指定明表达式返回了一个数值。
lambda 表达式在只有一条代码时还可以引用其他方法或构造器并自动调用,可以省略参数传递,代码更加简洁,引用方法的语法需要使用 :: 符号。lambda 表达式提供了四种引用方法和构造器的方式:
- 引用对象的方法 类::实例方法
- 引用类方法 类::类方法
- 引用特定对象的方法 特定对象::实例方法
- 引用类的构造器 类::new
最常见的方法,比如说遍历打印字符串或者排序,如下:
public class LambdaDemo {
public static void main(String[] args) {
List list = new LinkedList<>();
list.add("1");
list.add("2");
list.sort(String::compareTo);
list.forEach(System.out::println);
}
}
其中 forEach 的实现如下:
default void forEach(Consumer action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
复合 lambda 表达式
实现原理
lambda 表达式是通过 MethodHandler 和 invokeDynamic 实现的。
Stream 接口
stream 接口主要是为了快速处理一些聚合操作,如下一个实实例:
返回以字符 A 开头的字符串的最长长度。
最传统的写法如下:
public long maxLength(List data) {
List list = new LinkedList<>();
for (String s : data) {
if (s.startsWith("A")) list.add(s);
}
long max = -1;
for (String s: list) {
if (max < s.length()) max = s.length();
}
return max;
}
通过两次循环获得最大的值,但是,这样写因为有两次循环,所以会有效率上的损失,改进写法如下:
public long maxLength(List data) {
long max = -1;
for (String s: data) {
if (s.startsWith("A")) {
if (max < s.length()) max = s.length();
}
}
return max;
}
Stream 接口等效于第二种方式,在一次迭代中尽可能多的执行用户指定的操作,避免多次循环导致的效率问题。如下:
public long maxLength(List data) {
return data.stream().filter(s -> s.startsWith("A")).mapToLong(String::length).max().getAsLong();
}
Stream 接口总共分为两种操作,一种为中间操作(Intermediate operations),一种为结束操作(Terminal operations)。
中间操作具体分为两种,为不带状态的中间操作(Stateless)和带状态的中间操作(Stateful)。不带状态的中间操作指元素的处理不受到前面元素的影响,而带状态的中间操作必须要等到所有元素处理完之后才能知道结果。
结束操作也分为两种,为短路操作和非短路操作,短路操作是指不用处理全部元素就可以返回结果,比如找到第一个满足条件的元素。非短路操作要找到所有满足条件的元素才能完成。
如下:
Stream 操作分类
|
|---中间操作(Intermediate operations)
| |
| |---无状态(Stateless)
| | |---unordered() // 返回一个无序的流
| | |---filter() // 按照条件过滤
| | |---map() // 处理流,产生新流
| | |---mapToInt() // 获得一个整数流
| | |---mapToLong() // 获得一个长整型流
| | |---mapToDouble() // 获得一个双实数流
| | |---flatMap() // 扁平化流
| | |---flatMapToInt() // 扁平化流到整形
| | |---flatMapToLong() // 扁平化流到长整形
| | |---flatMapToDouble() // 扁平化流到双实数类型
| | |---peek() // 没有返回值的 map
| |
| |---有状态(Stateful)
| |---distinct() // 实现非重复流
| |---sorted() // 排序
| |---limit() // 取前 x 元素
| |---skip() // 跳过前 x 元素
|
|
|---结束操作(Terminal operations)
|
|---非短路操作
| |---forEach() // 遍历(使用 parallelStream 不保证顺序)
| |---forEachOrdered() // 遍历(保证顺序)
| |---toArray() // 转换成数组
| |---reduce() // 合并流,比如说对流中所有元素求和
| | data.stream().reduce((a, b) -> a + b);
| |---collect() // 收集流
| |---max() // 求最大值
| |---min() // 求最小值
| |---count() // 统计个数
|
|---短路操作(short-circuiting)
|---anyMatch() // 任意一个匹配,返回 true
|---allMatch() // 所有匹配,返回 true
|---noneMatch() // 所有都不匹配,返回 true
|---findFirst() // 找到第一个出现的元素并返回
|---findAny() // 找到任意出现的元素并返回
Stream 接口实现原理
Stream 接口采用流水线的方式执行整个过程,要构建一个流水线,需要解决三个问题:
- 流水线构建
- 流水线方法保存
- 流水线操作执行
- 流水线结果保存
流水线构建 使用 pipeline,Java Stream 中,流水线的中间节点使用 PipelineHelper 来代表一个 stage,每个 stage 就是一个用户指定的操作,如 map、filter 等。多个不同的 stage 连接成一个双向链表,这个双向链表就封装了用户的全部操作。
如下实例:
data.stream().filter(s -> s.startsWith("A")).mapToLong(String::length).max();
构成的流水线如下:
|---------| ----> |---------| -----> |---------| ------> |---------|
| Head | |filter op| | map op | | max op |
|---------| <---- |---------| <----- |---------| <------ |---------|
data source ---------> stage 0 ---------> stage 1 ---------> stage 2 ---------> stage 3
stream() filter() mapToLong() max()
流水线方法保存 采用的是 sink 接口,提供了最重要的四个函数,如下:
interface Sink extends Consumer {
// 开始遍历元素之前调用该方法,通知Sink做好准备。
default void begin(long size) {}
// 所有元素遍历完成之后调用,通知Sink没有更多的元素了。
default void end() {}
// 是否可以结束操作,可以让短路操作尽早结束。
default boolean cancellationRequested() {
return false;
}
// 遍历元素时调用,接受一个待处理元素,并对元素进行处理。Stage把自己包含的操作和回调方法封装到该方法里,前一个Stage只需要调用当前Stage.accept(T t)方法就行了。
default void accept(int value) {
throw new IllegalStateException("called wrong accept method");
}
default void accept(long value) {
throw new IllegalStateException("called wrong accept method");
}
default void accept(double value) {
throw new IllegalStateException("called wrong accept method");
}
// ...
}
一般来说,重写这些函数就可以实现聚合逻辑。例如 filter 实现如下:
@Override
public final Stream filter(Predicate predicate) {
Objects.requireNonNull(predicate);
return new StatelessOp(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
@Override
Sink opWrapSink(int flags, Sink sink) {
return new Sink.ChainedReference(sink) {
// 自己开始的同时,激活下一链
@Override
public void begin(long size) {
downstream.begin(-1);
}
// 预测是否满足要求,满足要求则将其丢给下一链处理
@Override
public void accept(P_OUT u) {
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}
对于稍微复杂的有状态操作,如排序,如下:
private static final class RefSortingSink extends AbstractRefSortingSink {
private ArrayList list;
// 创建一个临时的链表,保存结果
@Override
public void begin(long size) {
if (size >= Nodes.MAX_ARRAY_SIZE)
throw new IllegalArgumentException(Nodes.BAD_SIZE);
list = (size >= 0) ? new ArrayList((int) size) : new ArrayList();
}
// 对临时表进行排序
// 激活下一链处理
// 发送数据到下一链
@Override
public void end() {
list.sort(comparator);
downstream.begin(list.size());
if (!cancellationWasRequested) {
list.forEach(downstream::accept);
}
else {
for (T t : list) {
if (downstream.cancellationRequested()) break;
downstream.accept(t);
}
}
downstream.end();
list = null;
}
// 上一连将其所有的元素加入到临时表中
@Override
public void accept(T t) {
list.add(t);
}
// ...
}
note
- 从流水线的执行上来看,对于无状态的中间操作,是可以通过流水线进行并行的,但是对于有状态的操作,则必须等到所有的数据处理完之后才能够进行下一步,所以,每当有有状态的中间操作,就会多一次循环。
以 filter 函数为例,函数主题返回一个实现了 Stream 接口的 StatelessOp 对象,如下:
public final Stream filter(Predicate predicate) {
Objects.requireNonNull(predicate);
return new StatelessOp(this, StreamShape.REFERENCE, StreamOpFlag.NOT_SIZED) // ... 匿名类实现
}
StatelessOp 是属于 ReferencePipeline 的一个静态内部类。构造函数如下:
// 将上一级 stage 引用加入到该 stage 中
StatelessOp(AbstractPipeline upstream,
StreamShape inputShape,
int opFlags) {
super(upstream, opFlags);
assert upstream.getOutputShape() == inputShape;
}
那么实际上对于 filter 函数,是将上一级的 stage 引用(他自身)加入到了一个新的 stage 中。并返回了那个新的 stage,如下:
|--------------------------|
|---------| | previousStage = stage n |
| stage n | | stage n + 1 |
|---------| |--------------------------|
stream().func() ------------> stream.func().filter() ---------------------------->
流水线执行 使用结束操作唤醒。结束操作也是一个特殊的 stage。根据流水线的双向队列,不考虑结束操作时的执行,如下:
data.stream().filter(s -> s.startsWith("A")).mapToLong(String::length).max();
// |------|>|----------------------------|>|-----------------------|>|------|
// | Head | | filter op | | map op | |max op|
// |------|<|----------------------------|<|-----------------------|<|------|
当执行 max 函数时,会执行如下的语句:
@Override
public final Optional max(Comparator comparator) {
return reduce(BinaryOperator.maxBy(comparator));
}
maxBy 函数很简单,仅仅是返回一个比较器,如下:
public static BinaryOperator maxBy(Comparator comparator) {
Objects.requireNonNull(comparator);
return (a, b) -> comparator.compare(a, b) >= 0 ? a : b;
}
reduce 函数才是一个短路操作,如下:
@Override
public final Optional reduce(BinaryOperator accumulator) {
return evaluate(ReduceOps.makeRef(accumulator));
}
makeRef 函数本质上来说也是生成一个 sink,如下:
public static TerminalOp> makeRef(BinaryOperator operator) {
class ReducingSink implements AccumulatingSink, ReducingSink> {
private boolean empty;
private T state;
public void begin(long size) {
empty = true;
state = null;
}
@Override
public void accept(T t) {
if (empty) {
empty = false;
state = t;
} else {
state = operator.apply(state, t);
}
}
@Override
public Optional get() {
return empty ? Optional.empty() : Optional.of(state);
}
@Override
public void combine(ReducingSink other) {
if (!other.empty)
accept(other.state);
}
}
return new ReduceOp, ReducingSink>(StreamShape.REFERENCE) {
@Override
public ReducingSink makeSink() {
return new ReducingSink();
}
};
}
所有的计算工作都是由 evaluate 函数完成的,如下:
final R evaluate(TerminalOp terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
实际上, stream 流计算有两种模式,一种是串行的方式,一种是并行的方式,首先看串行的方式 evaluateSequential,如下:
@Override
public R evaluateSequential(PipelineHelper helper,
Spliterator spliterator) {
return helper.wrapAndCopyInto(makeSink(), spliterator).get();
}
helper 代表的实际上是除开 max 后的最后一个 stage,即 mapToLong,可以根据如下函数栈追踪到运行的函数,如下:
copyInto(wrapSink(Objects.requireNonNull(sink)), spliterator);
/|\
|
helper.wrapAndCopyInto(makeSink(), spliterator);
copyInto 为运行的核心函数,如下:
final void copyInto(Sink wrappedSink, Spliterator spliterator) {
Objects.requireNonNull(wrappedSink);
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());
spliterator.forEachRemaining(wrappedSink);
wrappedSink.end();
}
else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}
就是该函数启动了整个流水线的执行。
Stream 接口并行化
对于无状态的 stage,是可以开启并行来处理的,主要是用到了 Java 提供的 Fork/Join 框架。
来看 evaluateParallel 函数,如下:
@Override
public R evaluateParallel(PipelineHelper helper,
Spliterator spliterator) {
return new ReduceTask<>(this, helper, spliterator).invoke().get();
}
ReduceTask 是 ForkJoinTask 的一个子类,invoke() 函数就是开启计算流程,get() 函数等待计算完成并返回结果。
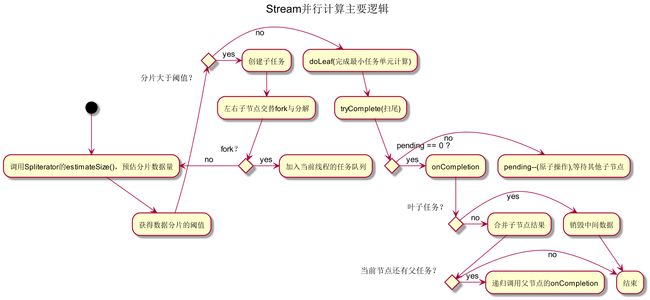
ForkJoinTask 最重要的就是重写 compute 函数
@Override
public void compute() {
Spliterator rs = spliterator, ls; // right, left spliterators
long sizeEstimate = rs.estimateSize();
long sizeThreshold = getTargetSize(sizeEstimate);
boolean forkRight = false;
@SuppressWarnings("unchecked") K task = (K) this;
while (sizeEstimate > sizeThreshold && (ls = rs.trySplit()) != null) {
K leftChild, rightChild, taskToFork;
task.leftChild = leftChild = task.makeChild(ls);
task.rightChild = rightChild = task.makeChild(rs);
task.setPendingCount(1);
if (forkRight) {
forkRight = false;
rs = ls;
task = leftChild;
taskToFork = rightChild;
}
else {
forkRight = true;
task = rightChild;
taskToFork = leftChild;
}
taskToFork.fork();
sizeEstimate = rs.estimateSize();
}
task.setLocalResult(task.doLeaf());
task.tryComplete();
}
使用 Spliterator 迭代器产生数据,并且交叉左右节点执行 fork 函数(即分叉计算),在 tryComplete 中执行结果的合并操作,流程图如下: