1、架构功能需求
笔者在最近的项目中遇到了需要将一个大型组织的全部交换机以及N7000核心交换机配置监控架构的需求。该需求主要有如下的条目:
- N7000配置全端口的详细上下行和监控和报错计数。
- 普通交换机配置Tel1/0/1和Tel1/0/2的上下行监控和报错计数。
- 所有交换机配置运行时间uptime和CPU使用情况监控。
在本次项目中所有交换机的型号都是思科C2960系列。
2、思路设计
由于是一个落地项目,且考虑到需求的数据更新频率是5sec,因此整个框架的数据压力并不是非常大,本着迁移方便和维护简便的原则,把所有的框架全部配置到docker容器环境下。由于N7000需要分端口监控,因此配置了两个数据抓取容器,然后汇总到同一个数据库,然后进行可视化处理。
因此我想到了使用influxdata系列的开源数据工具,这套工具包含了InfluxDB,Telegraf,Chronograf,Kapacitor四项,分别对应了数据库、数据收集、数据可视化呈现、自定义报警四个功能。俗称TICK套餐。不过在本次案例中并不需要使用Chronograf和Kapacitor,原因是有更好的替代品:Grafana。
所有的工具都架设在同一个虚拟机上,这种中小型规模的数据流并不需要集群或者hadoop之类的工具去跑,如果有数据安全的需求,在其他的物理机上对influxdb和telegraf的配置文件做一个动态增量备份就行。
具体流程如下:
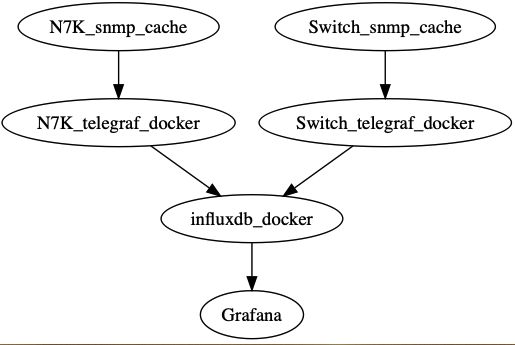
其中数据的抓取处理部分全部在容器中配置。
3、具体流程
① 创建一台虚拟主机
通过VMware等工具在服务器上配置一台4核以上的虚拟机,这台虚拟机将作为容器服务器来运作。
② 安装并配置Telegraf和Influxdb
首先在虚拟机上安装telegraf和influxdb,并且配置/etc/influxdb/influxdb.conf和/etc/telegraf/telegraf.conf。这一步的目的是为了之后起容器的时候能够直接-v调用相关的配置文件,同时可以轻松的修改相关的配置文件。
- 偷懒方法
如果已经在其他机器上配置过influxdb和telegraf,或者从官网获取了原版的conf文件,则可以直接mkdir /etc/influxdb/和mkdir /etc/telegraf/,在里面cp对应的配置conf文件进行配置编辑即可。
$ vim /etc/influxdb/influxdb.conf
$ vim /etc/telegraf/telegraf.conf
- Telegraf安装方法
Ubuntu:
$ wget https://dl.influxdata.com/telegraf/releases/telegraf_1.9.1-1_amd64.deb
$ sudo dpkg -i telegraf_1.9.1-1_amd64.deb
RedHat/CentOS:
$ wget https://dl.influxdata.com/telegraf/releases/telegraf-1.9.1-1.x86_64.rpm
$ sudo yum localinstall telegraf-1.9.1-1.x86_64.rpm
- Influxdb安装方法
Ubuntu:
$ wget https://dl.influxdata.com/influxdb/releases/influxdb_1.7.2_amd64.deb
$ sudo dpkg -i influxdb_1.7.2_amd64.deb
RedHat/CentOS:
$ wget https://dl.influxdata.com/influxdb/releases/influxdb-1.7.2.x86_64.rpm
$ sudo yum localinstall influxdb-1.7.2.x86_64.rpm
- Grafana安装方法
直接起docker容器即可,不需要在本地再次安装。
至于/etc/influxdb/influxdb.conf和/etc/telegraf/telegraf.conf的配置的话,可以去Stack Overflow等网站查看基础配置的设定,根据自身的需求来设置。
③ 配置容器环境
配置完conf文件之后我们来启动telegraf和influxdb的容器进程,这个过程中系统会自动拉取docker.o云端的程序包。请耐心等待。我们也可以通过下面的指令手动拉取:
$ docker pull telegraf
$ docker pull influxdb
或者直接启动容器进程:
- 启动influxdb docker,设置端口8086,当然你也可以设定成你需要的端口。
$ docker run -d \
--name influxdb \
-p 8086:8086 \
-v /etc/influxdb/influxdb.conf:/etc/influxdb/influxdb.conf \
-v /var/lib/influxdb:/var/lib/influxdb \
docker.io/influxdb
- 启动grafana docker
$ docker run \
-d \
-p 3000:3000 \
--name=grafana \
-e "GF_SERVER_ROOT_URL=http://grafana.server.name" \
-e "GF_SECURITY_ADMIN_PASSWORD=secret" \
grafana/grafana
- 启动telegraf docker
$ docker run -d \
--name telegraf \
--network host \
-v /etc/telegraf/telegraf.conf:/etc/telegraf/telegraf.conf \
docker.io/telegraf
这里需要注意的是,我们由于需要监控N7000和交换机,且这两种机器的需求、OID映射都完全不同,因此强烈建议配置两个不同的telegraf.conf文件,起两个不同的容器进行数据收集,这样可以避免大量无效的空条目产生。
至此,本监控框架的基本容器环境配置已经完成,之后开始进行SNMP数据抓取的配置。我们可以通过如下网址进入Grafana图形化监控总台:
http://localhost:3000/
之后的设置会在下面介绍。
④ SNMP交换机数据抓取
SNMP技术是简单网络管理协议(Simple Network Management Protocol)的简称,也就是一种简化的网络管理工具,可以提供管理、数据收集、发包控制等等的简单网络功能,其利用的oid系统对于中小规模的数据抓取需求简直是完美适配。而我们这次选择的telegraf配置工具对于snmp的支持也是非常的完美。
首先通过$ vim /etc/telegraf/telegraf.conf进入telegraf配置文件的编辑模式。在指令模式下/inputs.snmp来到snmp配置部分(telegraf支持的工具超超超多,所以配置文件几千行),之后根据配置文件中的提示来进行配置即可。
其中在oid写入部分一般推荐使用[[inputs.snmp.field]]类的抓取方案。关于oid,是用来对应交换机等硬件的详细状态信息的动态api接口名称,全称Object Identifier。一个可用的案例如下:
[[inputs.snmp]]
agents = ["192.268.0.1"]
## Timeout for each SNMP query.
timeout = "5s"
## Number of retries to attempt within timeout.
retries = 2
## SNMP version, values can be 1, 2, or 3
version = 2
## SNMP community string.
community = "YourCommunity"
## The GETBULK max-repetitions parameter
max_repetitions = 30
## measurement name
name="snmpd"
[[inputs.snmp.field]]
name="sysuptime"
oid="1.3.6.1.2.1.1.3.0"
[[inputs.snmp.field]]
name="cpu5sec"
oid=".1.3.6.1.4.1.9.9.109.1.1.1.1.6.1"
[[inputs.snmp.field]]
name="cpu1min"
oid=".1.3.6.1.4.1.9.9.109.1.1.1.1.7.1"
[[inputs.snmp.field]]
name="cpu5min"
oid=".1.3.6.1.4.1.9.9.109.1.1.1.1.8.1"
有了oid的对照表,我们就可以精确抓到相关交换机硬件软件的动态数据信息。通过,snmp还提供相关的工具帮我们直接验证oid的可用性。我们可以安装snmpwalk检测工具,以CentOS为例:
$ yum install -y net-snmp
$ yum install -y net-snmp-utils
然后可以用下面的指令格式查询oid的有效性。同时有个注意点,在telegraf的inputs.snmp部分写入的oid,必须是oid树结构的末梢,如果飞末梢会导致读到的是数据表而非单一值,而无法写入influxdb中。
$ snmpwalk -v 2 -c YourCommunity
在确定所有的oid可用的情况下,就可以编辑telegraf.conf并保存,然后重新起一个telegraf docker容器开始进行数据的收集了,顺利的话数据会立刻被写入到influxdb中对应的database里面。然后我们就可以前往Grafana平台进行使用了。
⑤ 思科C2960常用oid表
考虑到思科官网oid查询系统的反人类程度,以及大多数人并不会特地去官网下载oid对照映射手册,下面会列出思科C2960系列最常用的一些oid对照表。至于N7000系列的端口对照表还是请动手下载官方手册进行查询,因为那是一个无序表,链接为:思科设备OID对照查询工具。
# 获取端口Index
snmpwalk -v 2c -c Public 192.168.232.25 1.3.6.1.2.1.2.2.1.1
# 获取端口列表及其描述
snmpwalk -v 2c -c Public 192.168.232.25 1.3.6.1.2.1.2.2.1.2
# 获取端口Mac地址
snmpwalk -v 2c -c Public 192.168.232.25 1.3.6.1.2.1.2.2.1.6
# 获取IP地址对应的Index
snmpwalk -v 2c -c Public 192.168.232.25 1.3.6.1.2.1.4.20.1.2
# 获取端口的Up/Down情况
snmpwalk -v 2c -c Public 192.168.232.25 1.3.6.1.2.1.2.2.1.8
# 获取端口入流量(Bytes)
snmpwalk -v 2c -c Public 192.168.232.25 1.3.6.1.2.1.2.2.1.10
# 获取端口出流量(Bytes)
snmpwalk -v 2c -c Public 192.168.232.25 1.3.6.1.2.1.2.2.1.16
# 获取过去5秒的CPU load (cpu繁忙的百分比)
snmpwalk -v 2c -c Public 192.168.232.25 1.3.6.1.4.1.9.2.1.56.0
# 获取过去1分钟的CPU load (cpu繁忙的百分比)
snmpwalk -v 2c -c Public 192.168.232.25 1.3.6.1.4.1.9.2.1.57.0
# 获取过去5分钟的CPU load (cpu繁忙的百分比)
snmpwalk -v 2c -c Public 192.168.232.25 1.3.6.1.4.1.9.2.1.58.0
# 获取内存当前使用情况(bytes)
snmpwalk -v 2c -c Public 192.168.232.25 1.3.6.1.4.1.9.9.48.1.1.1.5
# 获取内存当前空闲多少(bytes)
snmpwalk -v 2c -c Public 192.168.232.25 1.3.6.1.4.1.9.9.48.1.1.1.6
# 获取设备序列号
snmpwalk -v 2c -c Public 192.168.232.25 1.3.6.1.2.1.47.1.1.1.1.11.1
或
snmpwalk -v 2c -c Public 192.168.232.25 1.3.6.1.4.1.9.3.6.3.0
# 获取设备名称
snmpwalk -v 2c -c Public 192.168.232.25 1.3.6.1.2.1.1.5.0
⑥ Grafana图形化监控平台配置
在我们布置完多个telegraf数据收集容器和对应的snmp设置+influxdb容器+grafana容器之后,我们终于可以前往grafana网页图形化监控平台进行设置了。
-
导入数据库
首先我们需要导入对应的数据库,前往Grafana的设置界面,点击Add Database:
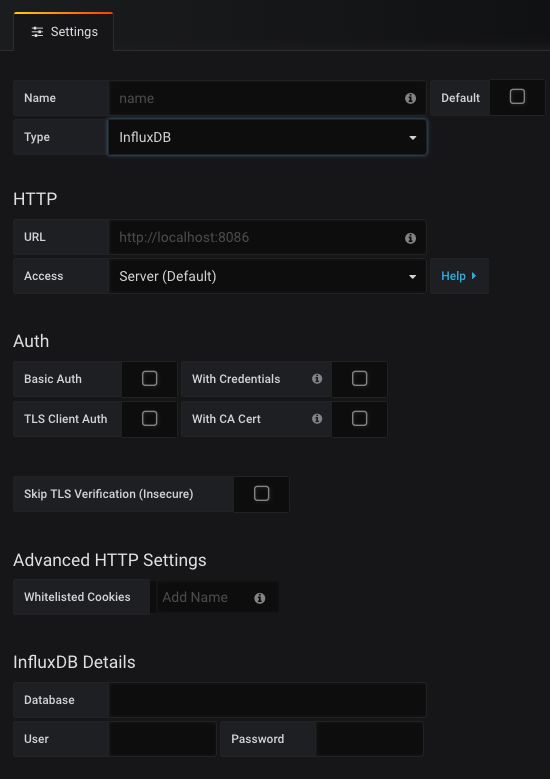 添加数据库
添加数据库
我们需要输入自定义名称Name,数据库所在对应的地址和端口(默认http://localhost:8086),然后设置需要抓取的database的名称和对应的账号密码。之后Save&Test就添加完毕了。 -
设置dashboard/设置变量
在添加了数据库之后,我们就需要开始自定义图形表,我们首先需要创建一个面板,然后在面板中设定各种panel,具体的设置方法可以查看Grafana官方Docs,对于Panel的设定有详细的介绍。
这里我们要主要介绍的技巧是Grafana的$Variable功能,这个功能对于数据库有重要的价值,我们可以设置数据库tag或者field的筛选条件来产生一个变量组,这个变量组或多个变量组会以下拉表单的形式出现在整个dashboard的最上方,作为一个筛选条件来进行使用。有了这些变量,我们面对大量多为的数据存储结构的时候,可以用极少的面板完成对海量数据的呈现。具体方法如下:
Query代表了数据库的筛选语句,用来获得tag或者field的全值;Regex是正规表示法筛选,可以筛选出需要的所有变量,不支持并集
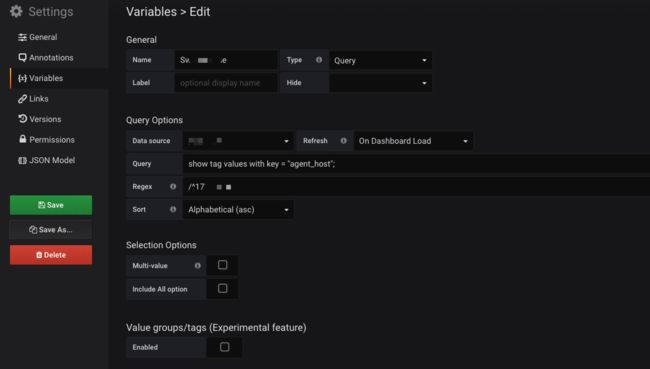 Dashboard变量设置
Dashboard变量设置
 变量表单效果
变量表单效果
- 批量化panel生成
Grafana之所以成为我们监控架构图形化的选择,除了开源工具这个属性之外,更重要的原因是Grafana支持Json编辑模式,也就是可以直接通过json脚本代码来生成相关的面板,对于几十到几百量级的面板,用python脚本直接生成json是最合适的。
我们可以制作一个【面板组】,这个代表了一个最小的面单组合单位,然后前往Dashboard设置面板,可以在JSON Model下看到整个面板的完全脚本代码。这个代码是高度规律的,所以我们动手直接撸一个脚本来做循环输出就行。大致思路介绍如下,直接在panel[]结构里获得面板组代码集,然后用循环直接去做关键词替换然后重复堆叠架构就行了,这种批量生成空间复杂度非常低,哪怕数万行也是秒出:
def SwhFuckingNum(i):
with open('./file2','r+') as d1:
infos=d1.readlines()
d1.seek(0,0)
for line in infos:
yaxe = (i-1)*5
line=line.replace('thefuckingport',str(i))
d1.write(line)
d1.close()
这部分有两个注意点,一、注意每个面板的左上定位点(x,y)的位置和面板尺寸的关系,做好自动演进。 二、单个面板以','结尾,最后一个面板无需','结尾。
最后将生成的panel JSON(可能有数万甚至数十万)集放到Dashboard的panel[]中即可。不过一般在panel数量多于400的情况下,就不推荐单一面板堆放了。因为Grafana的优化并不是非常出色,在多面板情境下的反馈速度会变得很慢。
关于Grafana的panel JSON构造,我会在之后的更新中详细介绍。
-
最终呈现
最后呈现的就是一个非常密集可读的监控面板,如图:
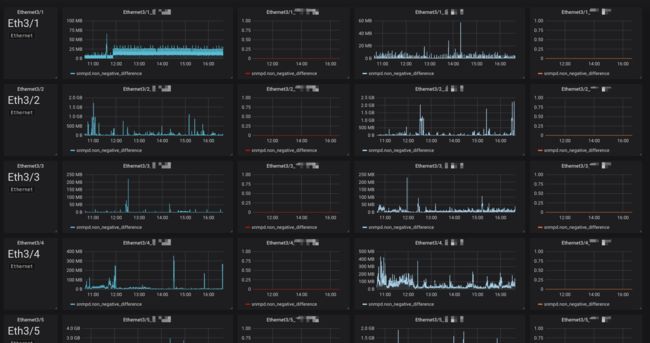 N7000全端口监控面板
N7000全端口监控面板