ERNIE是百度自研的持续学习语义理解框架,该框架支持增量引入词汇(lexical)、语法 (syntactic) 、语义(semantic)等3个层次的自定义预训练任务,能够全面捕捉训练语料中的词法、语法、语义等潜在信息。
ERNIE2.0实现了在中英文16个任务上的最优效果,具体效果见下方列表。
一、ERNIE2.0中文效果验证
我们在 9 个任务上验证 ERNIE 2.0 中文模型的效果。这些任务包括:自然语言推断任务 XNLI;阅读理解任务 DRCD、DuReader、CMRC2018;命名实体识别任务 MSRA-NER (SIGHAN2006);情感分析任务 ChnSentiCorp;语义相似度任务 BQ Corpus、LCQMC;问答任务 NLPCC2016-DBQA 。
1、自然语言推断任务
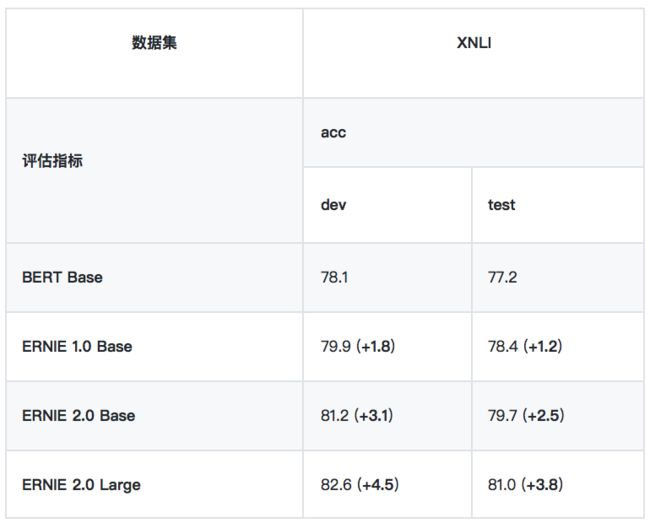
• XNLI
XNLI 是由 Facebook 和纽约大学的研究者联合构建的自然语言推断数据集,包括 15 种语言的数据。我们用其中的中文数据来评估模型的语言理解能力。[链接: facebookresearch/XNLI]
2、阅读理解任务
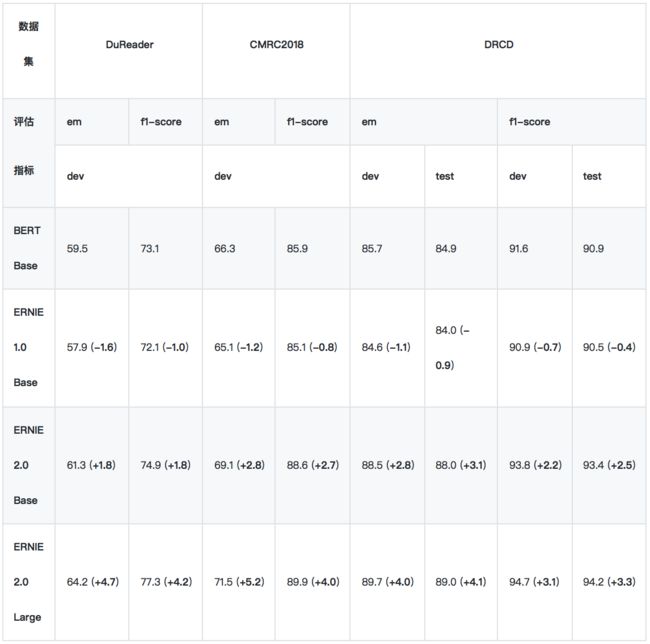
*实验所用的 DuReader 抽取类、单文档子集为内部数据集。
*实验时将 DRCD 繁体数据转换成简体,繁简转换工具:skydark/nstools
*ERNIE 1.0 的预训练数据长度为 128,其他模型使用 512 长度的数据训练,这导致 ERNIE 1.0 BASE 在长文本任务上性能较差, 为此我们发布了 ERNIE 1.0 Base (max-len-512) 模型 (2019-07-29)
• DuReader
DuReader 是百度在自然语言处理国际顶会 ACL 2018 发布的机器阅读理解数据集,所有的问题、原文都来源于百度搜索引擎数据和百度知道问答社区,答案是由人工整理的。实验是在 DuReader 的单文档、抽取类的子集上进行的,训练集包含15763个文档和问题,验证集包含1628个文档和问题,目标是从篇章中抽取出连续片段作为答案。[链接: https://arxiv.org/pdf/1711.05073.pdf]
• CMRC2018
CMRC2018 是中文信息学会举办的评测,评测的任务是抽取类阅读理解。[链接: ymcui/cmrc2018]
• DRCD
DRCD 是台达研究院发布的繁体中文阅读理解数据集,目标是从篇章中抽取出连续片段作为答案。我们在实验时先将其转换成简体中文。[链接: DRCKnowledgeTeam/DRCD]
3、命名实体识别任务
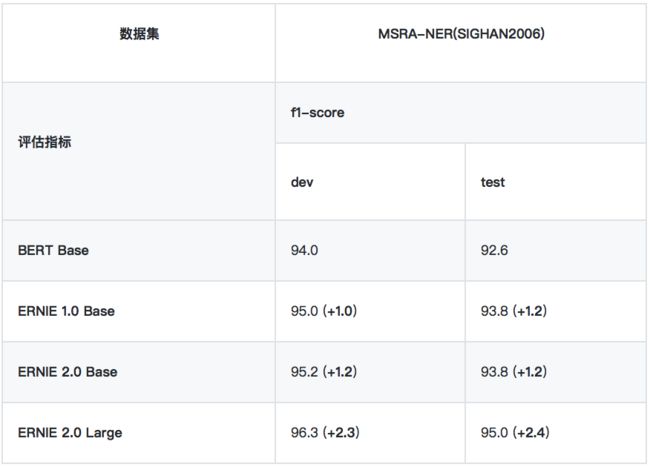
• MSRA-NER (SIGHAN2006)
MSRA-NER (SIGHAN2006) 数据集由微软亚研院发布,其目标是识别文本中具有特定意义的实体,包括人名、地名、机构名。
4、情感分析任务
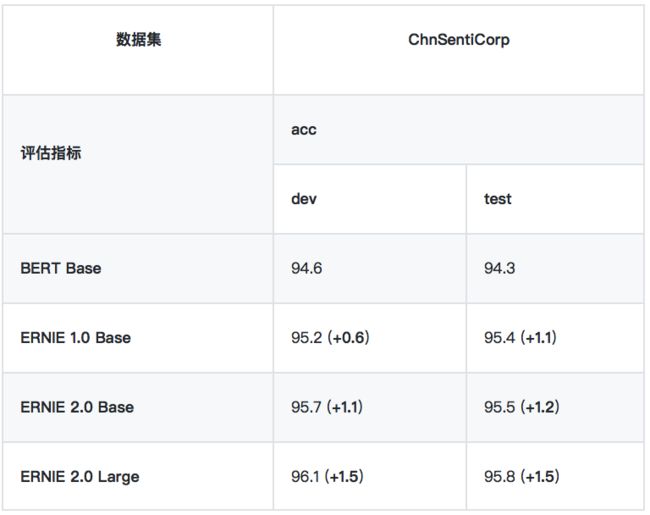
• ChnSentiCorp
ChnSentiCorp 是一个中文情感分析数据集,包含酒店、笔记本电脑和书籍的网购评论。
5、问答任务

• NLPCC2016-DBQA
NLPCC2016-DBQA 是由国际自然语言处理和中文计算会议 NLPCC 于 2016 年举办的评测任务,其目标是从候选中找到合适的文档作为问题的答案。[链接: http://tcci.ccf.org.cn/conference/2016/dldoc/evagline2.pdf]
6、语义相似度
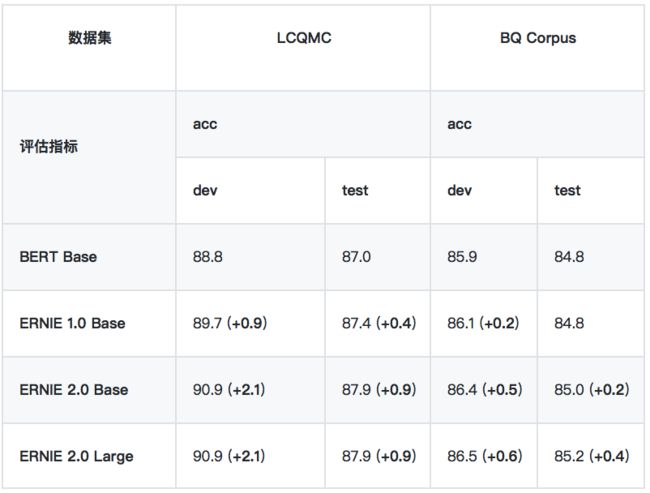
*LCQMC 、BQ Corpus 数据集需要向作者申请,LCQMC 申请地址:LCQMC: A Large-scale Chinese Question Matching Corpus, BQ Corpus 申请地址:The BQ Corpus: A Large-scale Domain-specific Chinese Corpus For Sentence Semantic Equivalence Identification
• LCQMC
LCQMC 是在自然语言处理国际顶会 COLING 2018 发布的语义匹配数据集,其目标是判断两个问题的语义是否相同。[链接: LCQMC:A Large-scale Chinese Question Matching Corpus]
• BQ Corpus
BQ Corpus 是在自然语言处理国际顶会 EMNLP 2018 发布的语义匹配数据集,该数据集针对银行领域,其目标是判断两个问题的语义是否相同。[链接: The BQ Corpus: A Large-scale Domain-specific Chinese Corpus For Sentence Semantic Equivalence Identification]
二、英文效果验证
ERNIE 2.0 的英文效果验证在 GLUE 上进行。GLUE 评测的官方地址为 GLUE Benchmark ,该评测涵盖了不同类型任务的 10 个数据集,其中包含 11 个测试集,涉及到 Accuracy, F1-score, Spearman Corr,. Pearson Corr,. Matthew Corr., 5 类指标。GLUE 排行榜使用每个数据集的平均分作为总体得分,并以此为依据将不同算法进行排名。
1、GLUE - 验证集结果
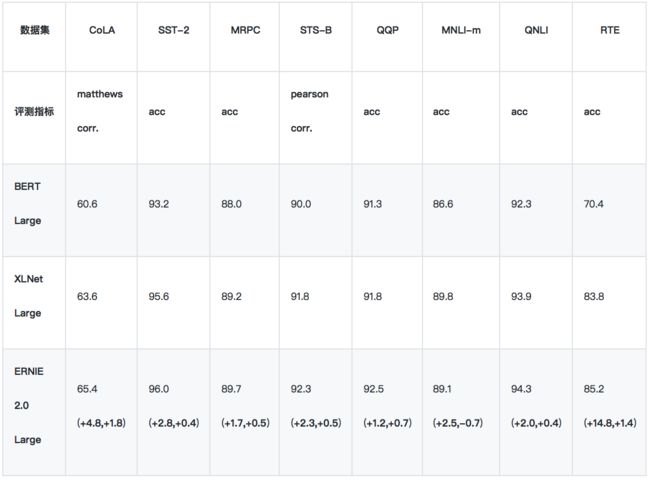
我们使用单模型的验证集结果,来与 BERT/XLNet 进行比较。
2、GLUE - 测试集结果
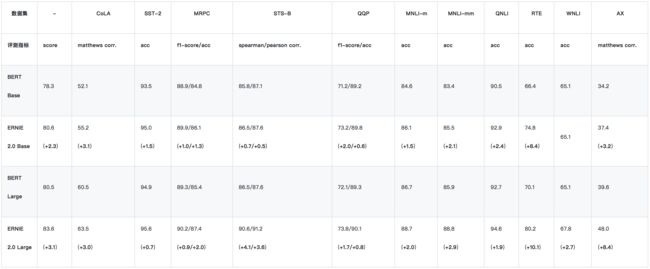
由于 XLNet 暂未公布 GLUE 测试集上的单模型结果,所以我们只与 BERT 进行单模型比较。上表为ERNIE 2.0 单模型在 GLUE 测试集的表现结果。
三、真实用户点评
“评分表数据很炸裂啊”
“我觉得你们这个模型太棒了,既能学习到实体embedding,又能学到Word embedding”
“ERNIE2.0创新地将过去单一的预训练流程拆解为串行的多个预训练任务,无疑是最大的贡献”
“ERNIE2.0的使用很方便”
“通过预训练模型BERT, ERNIE, BERT-wwm在公开数据集的对比,发现ERNIE表现较好,原因是采用了非正式数据进行预训练”
“ERNIE2.0创新性的运用了连续增量式多任务学习”
…
大家用了都说好,感觉来试用吧。
划重点!
查看ERNIE模型使用的完整内容和教程,请点击下方链接,建议Star收藏到个人主页,方便后续查看。
GitHub:PaddlePaddle/ERNIE

版本迭代、最新进展都会在GitHub第一时间发布,欢迎持续关注!
也邀请大家加入ERNIE官方技术交流QQ群:760439550,可在群内交流技术问题,会有ERNIE的研发同学为大家及时答疑解惑。
