15.1基本概念
规则学习是从训练数据中学习一组能用于对未见示例进行判别的规则。

规则可分为两类:命题规则和一阶规则
命题规则由原子命题和逻辑连接词构成简单陈述句。
一阶规则基本成分是能描述事物的属性或关系的原子公式,能够表达复杂的关系,也被称为关系型规则
命题规则是一阶规则的特例,一阶规则的学习比命题规则复杂。
15.2 序贯覆盖

一般有两种策略:
自顶向下:从比较一般的规则开始,逐渐添加新文字以缩小规则覆盖范围,直到满足预定条件为止,“生成测试法”,容易产生泛化性能好的规则
自底向上:从比较特殊的规则开始,逐渐删除文字以扩大规则覆盖范围,直到满足条件为止,更适用于训练样本较少的情形,在假设空间非常复杂的任务上使用
规则生成过程中涉及一个评估规则优劣的标准

集束搜索:每轮保留最优的b个逻辑文字,在下一轮均用于构建候选集,再把候选集中最优的b个留待下一轮使用
多分类问题:当学习关于第C个类的规则时,将所有属于类别C的样本作为正例,其他类别的作为反例
15.3 剪枝优化
(摘转 https://blog.csdn.net/taoqick/article/details/72818496)后剪枝
REP 剪枝
REP方法是一种比较简单的后剪枝的方法,在该方法中,可用的数据被分成两个样例集合:一个训练集用来形成学习到的决策树,一个分离的验证集用来评估这个决策树在后续数据上的精度,确切地说是用来评估修剪这个决策树的影响。
这个方法的动机是:即使学习器可能会被训练集中的随机错误和巧合规律所误导,但验证集合不大可能表现出同样的随机波动。所以验证集可以用来对过度拟合训练集中的虚假特征提供防护检验。
该剪枝方法考虑将书上的每个节点作为修剪的候选对象,决定是否修剪这个结点有如下步骤组成:
1:删除以此结点为根的子树
2:使其成为叶子结点
3:赋予该结点关联的训练数据的最常见分类
4:当修剪后的树对于验证集合的性能不会比原来的树差时,才真正删除该结点
因为训练集合的过拟合,使得验证集合数据能够对其进行修正,反复进行上面的操作,从底向上的处理结点,删除那些能够最大限度的提高验证集合的精度的结点,直到进一步修剪有害为止(有害是指修剪会减低验证集合的精度)。
REP是最简单的后剪枝方法之一,不过由于使用独立的测试集,原始决策树相比,修改后的决策树可能偏向于过度修剪。这是因为一些不会再测试集中出现的很稀少的训练集实例所对应的分枝在剪枝过如果训练集较小,通常不考虑采用REP算法。
尽管REP有这个缺点,不过REP仍然作为一种基准来评价其它剪枝算法的性能。它对于两阶段决策树学习方法的优点和缺点提供了了一个很好的学习思路。由于验证集合没有参与决策树的创建,所以用REP剪枝后的决策树对于测试样例的偏差要好很多,能够解决一定程度的过拟合问题。
PEP
悲观错误剪枝法是根据剪枝前后的错误率来判定子树的修剪。该方法引入了统计学上连续修正的概念弥补REP中的缺陷,在评价子树的训练错误公式中添加了一个常数,假定每个叶子结点都自动对实例的某个部分进行错误的分类。
把一颗子树(具有多个叶子节点)的分类用一个叶子节点来替代的话,在训练集上的误判率肯定是上升的,但是在新数据上不一定。于是我们需要把子树的误判计算加上一个经验性的惩罚因子。对于一颗叶子节点,它覆盖了N个样本,其中有E个错误,那么该叶子节点的错误率为(E+0.5)/N。这个0.5就是惩罚因子,那么一颗子树,它有L个叶子节点,那么该子树的误判率估计为:

这样的话,我们可以看到一颗子树虽然具有多个子节点,但由于加上了惩罚因子,所以子树的误判率计算未必占到便宜。剪枝后内部节点变成了叶子节点,其误判个数J也需要加上一个惩罚因子,变成J+0.5。那么子树是否可以被剪枝就取决于剪枝后的错误J+0.5在的标准误差内。对于样本的误差率e,我们可以根据经验把它估计成各种各样的分布模型,比如是二项式分布,比如是正态分布。
那么一棵树错误分类一个样本值为1,正确分类一个样本值为0,该树错误分类的概率(误判率)为e(e为分布的固有属性,可以通过统计出来),那么树的误判次数就是伯努利分布,我们可以估计出该树的误判次数均值和标准差:
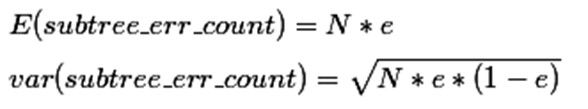

使用训练数据,子树总是比替换为一个叶节点后产生的误差小,但是使用校正后有误差计算方法却并非如此,当子树的误判个数大过对应叶节点的误判个数一个标准差之后,就决定剪枝:
这个条件就是剪枝的标准。当然并不一定非要大一个标准差,可以给定任意的置信区间,我们设定一定的显著性因子,就可以估算出误判次数的上下界。
话不多说,上例子:(9、7识别错误的个数)
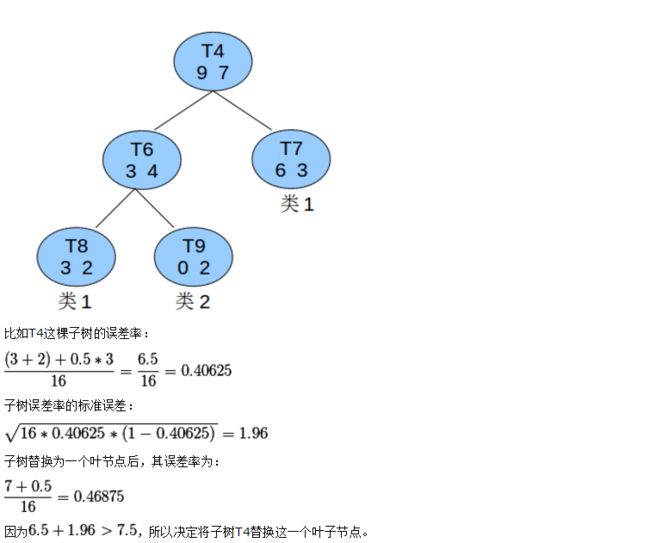
在上述例子中T8种的类1可以认为是识别错误的T4这棵子树的估计错误为5,T4子树的最后叶子节点为3个
上述是悲观错误剪枝。
悲观剪枝的准确度比较高,但是依旧会存在以下的问题:
1.PeP算法实用的从从上而下的剪枝策略,这种剪枝会导致和预剪枝同样的问题,造成剪枝过度。
2.Pep剪枝会出现剪枝失败的情况。d
RIPPER
在众多分类算法中,决策树作为一种基于有监督学习的层次模型被大量使用,其有一种其他算法难以比拟的优点:可解释性强——通过将学习到的决策树可以很轻易的转换成“如果…那么”形式的规则。但决策树规则的建立依赖于树的生成,树的建立过程是对整个空间的递归划分、建立局部模型的过程,往往比较耗时,那么有没有方法可以跳过这一过程呢?答案就是规则归纳算法。
不同于树归纳,其不需要建立搜索树而是采用深度优先搜索策略直接从数据集生成规则且每次生成一条,在构造规则的过程中利用了决策树的特点,通过诸如比较每个属性的信息增益不断贪心地添加规则前件,并且在每条规则的建立过程中使用后剪枝对规则进行裁剪,每条规则逐次生成然后加入到规则库中直到无法再添加更多规则。为了尽可能减少过拟合现象,在规则加入到规则库以后一样有剪枝步,这使得归纳算法有较好的过拟合现象。规则归纳算法的一个例子是RIPPER算法,其从一系列算法的基础上发展而来,与传统决策树算法如C4.5相比,其算法效率大大提升,而正确率相差不大。
先从一个很基础的规则算法REP说起,REP的意思是Reduced Error Pruning,意即减少错误剪枝,其把训练集分成独立的生长集和剪枝集,在生长集上贪心地产生规则并在剪枝集上不断被简化直到规则的准确性下降。作为一个很基础的算法其满足规则归纳的各个要件,描绘了RIPPER算法大体框架。然后是在REP算法上发展起来的IREP,其最主要的改变是使用了先剪枝与后剪枝结合的办法。接下来是IREP*算法,相比于IREP,其引入了最小描述长度用于判断停止条件,并且在剪枝时使用了新的度量标准1。而RIPPER算法则是在IREP*的基础上加入了优化阶段,其产生在IREP*产生的规则上进一步调整后的结果。
RIPPER算法的主框架分为两个部分:生成规则与优化规则。
生成规则部分是一个两层的循环,其中外循环每次生成一条规则修剪后添加到规则库,内循环则是每次为规则增加一个前件;优化部分则是根据规则库里的规则构造备选规则,并使用MDL准则挑选出最佳规则加入规则库。下面介绍算法细节部分。
1.准备阶段
这个阶段首先计算每个类别的先验概率。由于RIPPER算法本身是二分类算法,所以对于多分类的数据集需要根据先验概率的降序转换为二分类问题,每次对先验概率较低的类别建立规则。假设完整的数据集为D,每次对一个类别的数据建立规则并加入到规则库中:如完整数据集的类C1,C2,…Cn先验概率为p1≤p2≤…≤pn,那么首先对C1建立规则,规则建立完成后将其覆盖的数据从D中删除。
2.为正例生成规则
这个阶段的输入是数据集D,正例类别C与其先验概率p,注意这里的数据集D是上一次生成规则阶段筛除部分数据后的数据集。首先需要计算的是在默认规则下的描述长度,这个描述长度将作为一个参考值使用,算法生成的规则不应该比默认规则有更长的描述长度。在这个阶段中,将生成若干条规则直到无法继续,这些规则的后件都是类别C,每一条规则的生成都经历增长和剪枝两个阶段,增长阶段从空规则开始,每次增加一个前件;剪枝阶段则从最后一个被添加的前件逆序往前剪枝。首先需要将数据集D分为独立的增长集Grow与修剪集Prune,通常两者的比例控制在2:1。
2.1规则增长阶段
这个阶段使用的数据集为增长集Grow。规则的增长从空规则开始(任何实例都被空规则覆盖),类似于决策树的建立过程,其每次在所有可能的属性与阈值之间挑选合适的组合作为前件添加到规则之中。度量的标准是信息增益,不同于其他决策树,这里的信息增益并非期望熵的减少,而是来源于信息论里对一个正例编码所需比特的减少。
2.2规则修剪阶段
修剪阶段使用修剪集Prune来检验规则的泛化能力。在这个阶段,从最后一项被添加的前件开始往前依次删去规则的一个前件,计算其在修剪集上的准确率(即被规则覆盖的数据中真正正例的比例)。算法选择准确率最高且前件尽可能少的规则,但该规则的准确率至少要比空规则高。记待修剪的规则R=(a1,a2,…a6),下表展示了修剪的过程
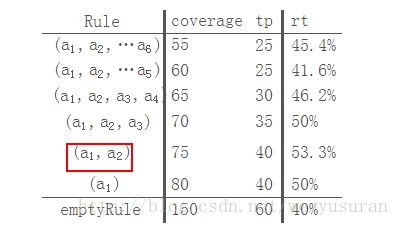
比较得出当规则只有两个前件时准确率最高,因此把前件a3,a4,a5,a6都删除。在某些文献中,剪枝时度量标准是最大化p−n/p+n,其中p是修剪集中被规则覆盖的正例,n是被规则覆盖的负例,其实两者是等价的,其实质仍是最大化修剪集上的准确率。
一旦规则被剪枝完成,则试图把其添加到规则库中,计算规则库的描述长度并更新最小描述长度。若添加规则后的描述长度比最小描述长度多64位时则停止添加规则,并把刚添加的规则从库中删去。如果规则覆盖的实例数量太少或者准确率过低一样也会导致添加失败。如果规则添加成功,则将其覆盖的实例从D中删去,重新划分Grow与Prune进入规则增长与修剪阶段。直到某个规则添加失败,该循环结束,不再产生新的规则,而是进入优化阶段。
3.优化阶段
此时针对阶段2生成的规则库进行优化,通过构造备选规则,算法对规则库里的每条规则都进行优化。类似于阶段2,此阶段使用的也是数据集D,且每优化一条规则都需要将最终规则覆盖的实例从D中删去然后优化下一条规则直到所有规则都被优化。规则优化的顺序同生成阶段规则添加的顺序。
3.1优化规则R
首先仍然是数据集D划分为Grow与Prune,策略与阶段2并没有什么不同。对于规则R,首先检测其在数据集D中的覆盖率,如果没有实例被覆盖那就没有优化的必要了。规则的优化通过构造额外两个备选规则实现,算法取三者中描述长度较小的规则。
备选规则一:仍然是从空规则开始,利用Grow生成规则并剪枝,但这里并不是直接使用Prune作为剪枝集,剪枝时的度量标准亦有所变化。对于Prune中的每个实例,如果其被规则库中R以后的任意规则覆盖,那么将其从Prune中删除。换言之,当针对规则Ri构造备选规则时,Prune中的任意实例都不能被规则Ri+1,Ri+2,…覆盖。其次,剪枝时需要计算的是规则在整个修剪集上的准确率而不是被覆盖的数据中的准确率(在阶段2的修剪阶段,计算的是tptp+fp,在这里计算的是tp+tntotal)。剪枝完成后的规则即是备选规则一。
备选规则二:此时从规则R开始继续添加前件并剪枝。首先对于Grow,筛选出其中所有被R覆盖的实例作为增长集,然后使用2.1中的方法继续往R添加前件直到无法继续增长。然后使用Prune剪枝,使用的是整个修剪集上的准确率。注意与备选规则一的异同,两者分别从空规则、原规则开始增长,增长集也不一样;而在剪枝部分,备选规则一对修剪集有一个预处理的过程,两者使用的都是整个修剪集上的准确率。
接下来便是将三者分别放入规则库中比较描述长度了,取最短者作为最终采纳的规则,然后更新数据集D并取下一条规则进行优化。在优化阶段,所有的规则都需要经过构造备选规则的优化,而整个优化阶段亦重复数次。到这里,针对某一类别建立的规则库便已确定了,若是多分类的话便更新最外层的数据集D(阶段1所提到的),将规则库覆盖的实例从中删去,然后挑选下一个类别,从阶段2重新开始构建规则并优化。因此在多分类问题中,根据先验概率的大小,每个类别都会生成一个规则库,它们与一条空规则(前件为空,后件为先验最大的类别)共同组成算法最终生成的规则库。
RIPPER算法由于不需要事先建立完整决策树,因此效率比C4.5等要高,复杂度为ο(Nlog2N),并且可以使用很大的数据集上,同时在算法效果上,其不亚于C4.5生成的规则。另,算法的一个具体实现可以参考Weka中的JRip算法。
4. 一阶规则学习
受限于命题逻辑表达能力命题规则学习难以处理对象之间的"关系" (relation),而关系信息在很多任务中非常重要。因此需用一阶逻辑表示,并且要使用一阶规则学习。所谓一阶逻辑表示其实就是利用比较,将原来的单一的表示用比较的方式来描述,如花的颜色为淡红色,另一只花的颜色比第一只更红。 于是其表达形式变化不大,还是由逻辑头和逻辑体构成,但是描述方式发生了变化:
更好(X,Y)←更好(X,Z)⋀更好(Z,Y)
无论是逻辑头还是逻辑体都变成了“更好(X,Y)”的形式,表示X比Y更好。
FOIL(First-Order Inductive Learner)算法是著名的一阶规则学习算法,它遵循序贯覆盖框架旦采用自顶向下的规则归纳策略。FOIL使用 “FOIL增益”(FOIL gain) 来选择文字:
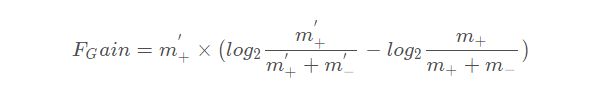
FOIL可大致看作命题规则学习与归纳逻辑程序设计之间的过渡,其自顶向下的规则生成过程不能支持函数和逻辑表达式嵌套,因此规则表达能力仍有不足;但它是把命题规则学习过程通过变量替换等操作直接转化为一阶规则学习,因此比一般归纳逻辑程序设计技术更高效。
5. 归纳逻辑程序设计(ILP)
归纳逻辑程序设计(Inductive Logic Programmi, ILP) 在一阶规则学习中引入了函数和逻辑表达式嵌套。
5.1 最小一般泛化
归纳逻辑程序设计采用自底向上的规则生成策略,直接将一个或多个正例所对应的具体事实(grounded fact)作为初始规则,再对规则逐步进行泛化以增加其对样例的覆盖率。泛化操作可以是将规则中的常量替换为逻辑变量,也可以是删除规则体中的某个文字。
以一下的例子用于辅助理解:
更好(1,10)←根蒂更蜷(1,10)∧声音更沉(1,10)∧脐部更凹(1,10)∧触感更硬(1,10)
更好(1,15)←根蒂更蜷(1,15)∧脐部更凹(1,15)∧触感更硬(1,15)
首先取出左边相同的逻辑文字:根蒂更蜷,脐部更凹,触感更硬;将相同的位置的10和15用Y代替,于是就有了更一般的表达:
更好(1,Y)←根蒂更蜷(1,Y)∧脐部更凹(1,Y)∧触感更硬(1,Y)
这个时候再来了另外的一个规则:
更好(2,10)←颜色更深(2,10)∧根蒂更蜷(2,10)∧敲声更沉(2,10)∧脐部更凹(2,10)∧触感更硬(2,10)

5.2 逆归结
1965年,逻辑学家J. A. Robinson提出:一阶谓词演算中的演绎推理能用一条十分简洁的规则描述,这就是数理逻辑中著名的归结原理(resolution principle)。二十多年后,计算机科学家s. Muggleton 和w. Buntine针对归纳推理提出了"逆归结" (inverse resolution)。所谓归结,就是基于合取范式的操作:

归结、逆归结都能容易地扩展为一阶逻辑形式;与命题逻辑的主要不同之处是,一阶逻辑的归结、逆归结通常需进行合一置换操作:
置换: 用某些项来替换逻辑表达式中的变量;
合一: 用一种变量置换令两个或多个逻辑表达式相等。
在现实任务中,ILP系统通常先自底向上生成一组规则,然后再结合最小一般泛化与逆归结做进一步学习。
摘转至【https://blog.csdn.net/kabuto_hui/article/details/84594421】