张超:又拍云系统开发高级工程师,负责又拍云 CDN 平台相关组件的更新及维护。Github ID: tokers,活跃于 OpenResty 社区和 Nginx 邮件列表等开源社区,专注于服务端技术的研究;曾为 ngx_lua 贡献源码,在 Nginx、ngx_lua、CDN 性能优化、日志优化方面有较为深入的研究。
子请求、父请求和主请求
Nginx 所处理的大部分请求,都是在接收到客户端发来的 HTTP 请求报文后创建的,这些请求直接与客户端打交道,称之为主请求;与之相对的则是子请求,顾名思义,子请求是由另外的请求创建的,比如主请求(当然子请求本身也可以创建子请求),当一个请求创建一个子请求后,它就成了该子请求的父请求。从源码层面来说,当前请求的主请求通过 r->main 指针获取,父请求则通过 r->parent 指针获取。
使用子请求机制的意义在于,它能够分散原本集中在单个请求里的处理逻辑,简化任务,大大降低请求的复杂度。例如当既需要访问一个 MySQL 集群,又需要访问一个 Redis 集群时,我们就可以分别创建一个子请求负责和 MySQL 的交互,另外一个负责和 Redis 的交互,简化主请求的业务复杂度。而且创建子请求的过程不涉及任何的网络 I/O,仅仅是一些内存的分配,其代价非常可控,因此在笔者看来,子请求机制是 Nginx 里最为巧妙的设计之一。
子请求创建与驱动
通常需要创建子请求时,模块开发者们可以调用函数 ngx_http_subrequest 来实现,默认情况下,子请求会共享父请求的内存池,变量缓存,下游连接和 HTTP 请求头等数据。当子请求创建完毕后,它会被挂到 r->main->posted_requests 链表上,这个链表用以保存需要延迟处理的请求(不局限于子请求)。因此子请求会在父请求本地调度完毕后得到运行的机会,这通常是子请求获得首次运行机会的手段。
我们知道 Nginx 针对一个 HTTP 请求,将其处理逻辑分别划分到了 11 个不同的阶段。当一个子请求被创建出来后,它首先运行的是 find config 阶段,即寻找一个合适的 location,然后开始后续的逻辑处理。通常,如果一个子请求不涉及任何的网络 I/O 操作,或者定时器处理,一次调度即可完成当前的子请求;而如果子请求需要处理一些网络、定时器事件,那么后续该子请求的调度,都会由这些事件来驱动,这使得它的调度和普通的主请求变得无差别。
既然除第一次外,子请求的驱动可能是由网络事件来驱动的,那么子请求的调度就是乱序的了。假设当前主请求需要向后端请求一个大小 2MB 的资源,我们通过产生两个子请求,分别获取 0-1MB 和 1MB - 2MB 的部分,然后发往下游,因为网络的不确定性,很有可能后者(1MB - 2MB)先获取到并往下游传输。那么此时下游所得到的数据就成了脏数据了。
为了解决这个问题,Nginx 为子请求机制引入了另外一个称为 postpone_filter 的模块。该模块的目的在于,判断当前准备发送数据的请求,是否是“活跃的”,如果当前请求不是“活跃”的,则它期望发送的数据会被暂时保存起来,直到某一刻它“活跃”了,才能将这些数据发往下游。
怎么判断一个请求是否是“活跃”的?我们需要先了解父、子请求之间的保存形式。对于当前请求,它的子请求以链表的方式被维护起来,而前面提到,子请求也可以创建子请求,因此这些请求间完整的保存形式可以理解成一颗分层树,如下图所示。
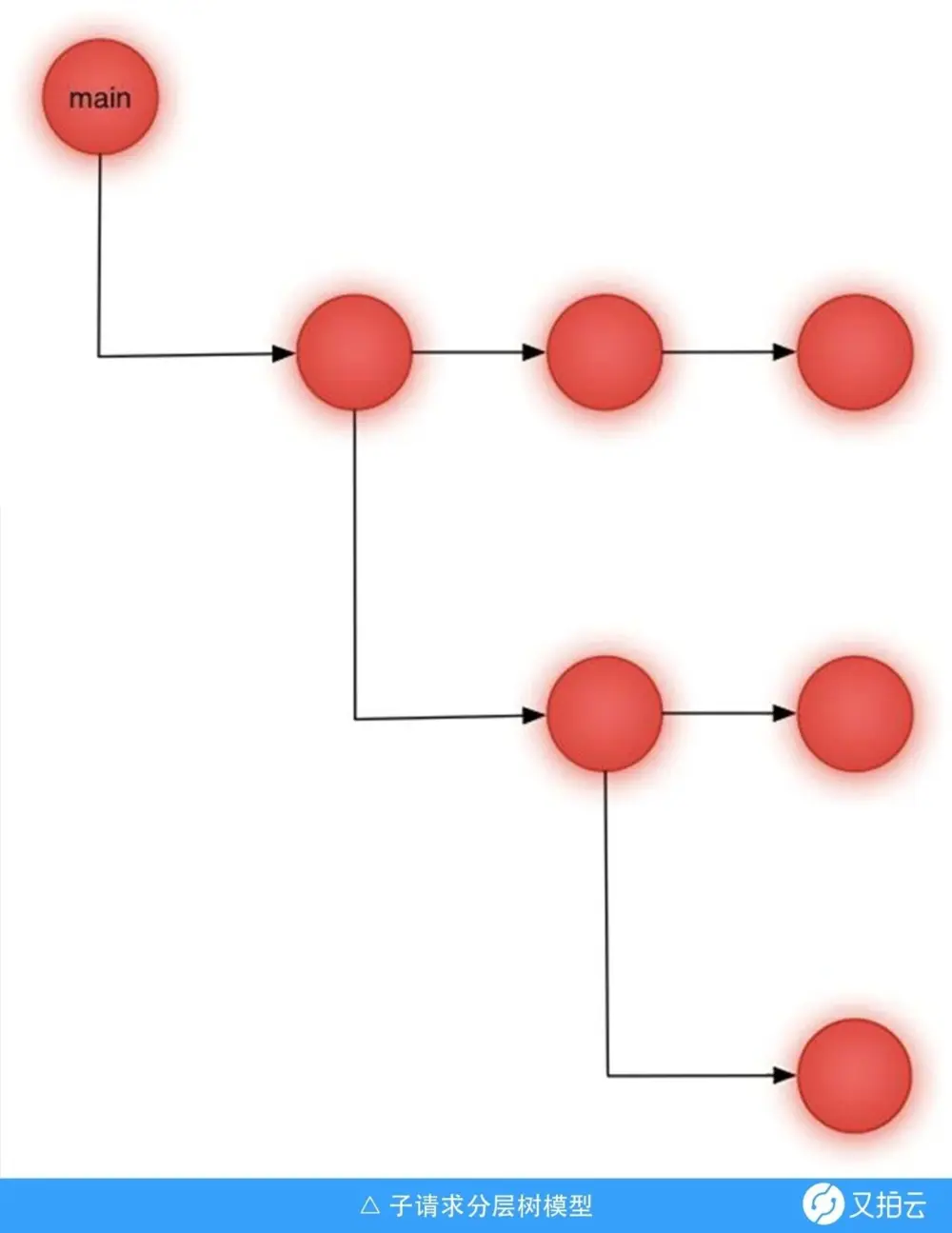
上图中,每个红圈表示一个请求,每一层的请求分别是上一层请求的子请求。从树遍历的角度讲,在这样一棵树上,哪个节点应该最先被处理?结合子请求机制的实际意义来分析,子请求是为了分摊父请求的处理逻辑,降低业务复杂度。换而言之,父请求是依赖于子请求的。很大程度上父请求可能需要等到当前子请求运行完毕后根据子请求反馈的结果来做一些收尾工作。所以需要采用的是类似后序遍历的规则。即上图最右下角的请求是第一个“活跃”的请求。
从源码层面来说,这颗分层树的保存用到了两个数据结构,r->postponed 和 r->parent这两个指针,遍历 r->postponed 来按序访问当前请求的子请求(树中同层的兄弟节点);遍历 r->parent 访问到父请求(树中上一层的父节点)。
postpone_filter 模块会判断当前请求是否“活跃”,如果不“活跃”,则把将要发送的数据临时拦截到它自己的 r->postponed链表上(所以这个链表上其实既有数据也有请求);如果是活跃的,则遍历它的 r->postponed 链表,要么把被临时拦截下来的数据发送出去,要么找到第一个子请求,将其标记为 “活跃”,然后返回。等到该子请求处理结束,重新将其父请求标记为“活跃”,这样一来,当父请求再一次运行到 postpone_filter 模块的时候,又可以遍历 r->postponed 链表,循环往复直到所有请求或者数据处理完毕。感兴趣的同学可以自行阅读相关源码(http://hg.nginx.org/nginx/file/tip/src/http/ngx_http_postpone_filter_module.c)。
使用了子请求机制的模块
目前整个 Nginx 生态圈,有很多使用子请求的例子,最著名的便是 ngx_lua 的子请求和 Nginx 官方的 slice_filter 模块了。
ngx_lua 提供给用户的 API (ngx.location.capture)灵活性非常大。 包括针对是否共享变量也可自行选择。特别地,ngx_lua 的子请求运行时,会阻塞父请求(挂起其对应的 Lua 协程)。直到子请求运行完毕,子请求的响应头、响应体(所以如果响应体比较大,则会消耗很多内存)等信息都会返回给父请求。ngx_lua 的子请求是不经过 postpone_filter模块的,它在一个较早的 filter 模块(ngx_http_lua_capture_filter) 里就完成了对子请求响应体的拦截。
Nginx 官方提供的 slice_filter模块,可以将一个资源下载,拆分成若干个 HTTP Range 请求,这样做最大的好处是分散热点。这个模块允许我们设置一个指令 slice_size,用以设置后续 Range 请求的区间大小。该模块会陆续创建子请求(在前一个完成后),直到所需资源下载完毕。
另外, Nginx/1.13.1 也引入了一个称为 Background subrequests 的机制(用以更新缓存)。基于这个机制,Nginx/1.13.4 引入了一个 mirror 模块,通过创建子请求,可以让用户自定义一些后台任务。比如预热一些资源,直接将它们放入 Nginx 自身的 proxy_cache 缓存中。
陷阱与缺陷
前文说到,子请求创建出来时,复用了父请求的一些数据,这无形中引入了一些坑点。
比如变量缓存,如果在子请求中访问并缓存了某个变量,当后续在父请求中使用时,我们就会得到之前的缓存数据,这可能造成工程师们花费大量的时间和精力去调试这个问题。
另外笔者认为一个非常重大的缺陷是,子请求复用了父请求的内存池,以 slice_filter 模块举例,它将一个 HTTP 请求划分成若干个的子请求,每个子请求向后端发起 HTTP Range 请求,在资源非常大 ,而配置的 slice_size 相对比较小的时候,会造成有大量的子请求的创建,整个资源下载过程可能会持续很长一段时间,这导致父请求的内存池在一段时间内没有释放,加之如果并发数比较大,可能会造成进程内存使用率变得很高,严重时可能会 OOM,影响到服务。因此在考虑使用的时候,需要权衡这些问题,有必要的话可能需要自行修改源码,以满足业务上的需要。
虽然一些缺点是在所难免的,但是子请求机制很大程度上简化了请求的处理逻辑,它分而治之的处理思想非常值得我们去学习和借鉴,无论如何,子请求机制也将是后续进行系统设计时的一大参考范例。
《我眼中的 Nginx》系列:
我眼中的 Nginx(一):Nginx 和位运算
我眼中的 Nginx(二):HTTP/2 dynamic table size update
我眼中的 Nginx(三):Nginx 变量和变量插值
我眼中的 Nginx(四):是什么让你的 Nginx 服务退出这么慢?