哈夫曼编码
任务要求
设有字符集:S={a,b,c,d,e,f,g,h,i,j,k,l,m,n.o.p.q,r,s,t,u,v,w,x,y,z}。
给定一个包含26个英文字母的文件,统计每个字符出现的概率,根据计算的概率构造一颗哈夫曼树。
并完成对英文文件的编码和解码。
要求:
(1)准备一个包含26个英文字母的英文文件(可以不包含标点符号等),统计各个字符的概率
(2)构造哈夫曼树
(3)对英文文件进行编码,输出一个编码后的文件
(4)对编码文件进行解码,输出一个解码后的文件
(5)撰写博客记录实验的设计和实现过程,并将源代码传到码云
(6)把实验结果截图上传到云班课
哈夫曼编码
哈夫曼树的基本概念
- 哈夫曼(Huffman)树又称作最优二叉树,它是n个带权叶子结点构成的所有二叉树中,带权路径长度最小的二叉树。
- “路径”就是从树中的一个结点到另一个结点之间的分支构成的部分,而分支的数目就是路径长度。
- 树的路径长度:就是从树根到每一结点的路径长度之和。
- 考虑带权的结点,结点的带权路径长度为:从该结点到树根之间的路径长度与结点上权的乘积。
- 树的带权路径长度WPL(weighted path length):树中所有叶子结点的带权路径长度之和。
- 假设一个有n个带权叶子结点的二叉树,其权值为{w1,w2,....wn},每个叶子结点带权wk,每个叶子的路径长度为 lk,则从根结点
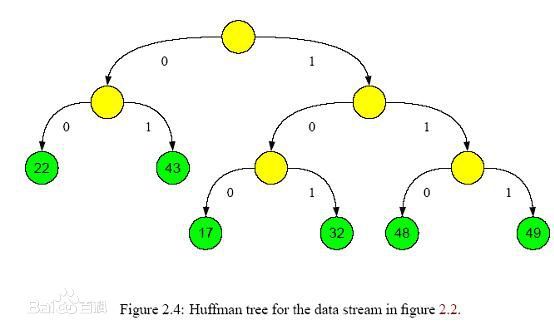
哈夫曼编码
- 哈夫曼编码是哈夫曼树的一个应用。在数字通信中,经常需要将传送的文字转换成由二进制字符0、1组成的二进制串,这一过程被
称为编码。在传送电文时,总是希望电文代码尽可能短,采用哈夫曼编码构造的电文的总长最短。 - 由常识可知,电文中每个字符出现的概率是不同的。假定在一份电文中,A,B,C,D四种字符出现的概率是4/10,1/10,3/10,
2/10,若采用不等长编码,让出现频率低的字符具有较长的编码,这样就有可能缩短传送电文的总长度。
分析及实现过程
- 读取文件中的字符并存入数组
读取文件
File file = new File("/Users/wby/IdeaProjects/NEW/HaFuManTree/src/test.txt");
//mac 设置路径的方法不太一样:/Users/wby/IdeaProjects/NEW/HaFuManTree/src/test.txt
Reader reader = new FileReader(file);
BufferedReader bufferedReader = new BufferedReader(reader);
String temp = bufferedReader.readLine();存入数组
char characters[] = new char[temp.length()];
for (int i = 0; i < temp.length(); i++) {
characters[i] = temp.charAt(i);
}- 计算每个字母出现的频率,存入另一数组
计算出频率存到frequency[]并输出
double frequency[] = new double[27];
//最后一个是加入空格
System.out.println("概率为:");
int num = 0;
for (int i = 0; i < characters.length; i++) {
if (characters[i] == ' ') {
num++;
}
frequency[26] = (float) num / characters.length;
}
for (int j = 97,i=0; j <= 122; j++,i++) {
//计数
int number = 0;
for (int m = 0; m < characters.length; m++) {
if (characters[m] == (char) j) {
number++;
}
/*frequency[j - 97] = (float) number / characters.length;*/
frequency[j - 97] = (float) number / characters.length;
}
// System.out.println("每个字符的概率是" + "\n" + Arrays.toString(frequency));
System.out.println();
System.out.print((char) j + ":"+frequency[i]);
}- 构造哈夫曼树
设置结点数组,有两个或两个以上,最后一个结点设置为根结点
while (nodes.size() > 1) {
Collections.sort(nodes);
HaFuMan left = nodes.get(nodes.size() - 1);
HaFuMan right = nodes.get(nodes.size() - 2);
HaFuMan parent = new HaFuMan('无', left.getWeight() + right.getWeight());
parent.setLeft(left);
left.setCode("0");
parent.setRight(right);
right.setCode("1");
nodes.remove(left);
nodes.remove(right);
nodes.add(parent);
}左子树为0右子树为1
if (root != null) {//判断根是否为空
queue.offer(root);
root.getLeft().setCode(root.getCode() + "0");
root.getRight().setCode(root.getCode() + "1");
}判断不为null,将它加入到队列
if (node.getRight() != null) {
queue.offer(node.getRight());
node.getRight().setCode(node.getCode() + "1");
}判断根是否为空
if (node.getLeft() != null) {
queue.offer(node.getLeft());
node.getLeft().setCode(node.getCode() + "0");- 新建文件夹编码并输出
设置编码
String result1 = "";
List temp1 = HaFuMan.breadth(root);
for (int i = 0; i < characters.length; i++) {
for (int j = 0; j < temp1.size(); j++) {
if (characters[i] == temp1.get(j).getData()) {
result1 += temp1.get(j).getCode();
}
}
}
设置文件输入流并打印
System.out.println("\n"+"编码:");
System.out.println(result1);
File file2 = new File("/Users/wby/IdeaProjects/NEW/HaFuManTree/src/test2.txt");
Writer writer = new FileWriter(file2);
writer.write(result1);
writer.close();- 新建文件夹解码并输出
设置解码
String result2 = "";
String current="";//定义最后的解码过程
while(sT.size()>0) {
current = current + "" + sT.get(0);
sT.remove(0);
for (int p = 0; p < newlist1.size(); p++) {
if (current.equals(newlist1.get(p))) {
result2 = result2 + "" + newlist.get(p);
current="";
}将文件解密并存入test3输出
System.out.println("\n"+"解码:"+"\n"+"F"+result2);
File file3 = new File("/Users/wby/IdeaProjects/NEW/HaFuManTree/src/test3.txt");
Writer writer1 = new FileWriter(file3);
writer1.write(result2);
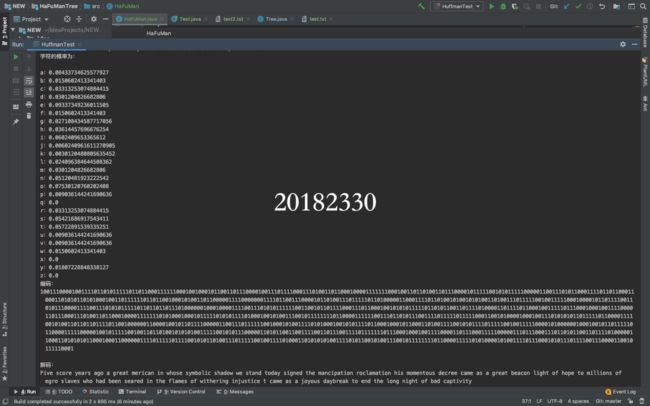
writer.close();实现结果
参考资料
哈夫曼树原理,及构造方法
mac的路径怎么写
哈夫曼树及其应用