这篇博客先介绍在dpdk中使用到的一些优化点[后期如果遇到其他的会完善],然后是NUMA架构,看了官方说明,对于10Gbit/s光口,能每秒发送/接收1480w+的64Byte[以太帧头+ip头+tcp头+数据]的数据包,为什么性能这么好?一方面与我们平时编码习惯相关,另一方面dpdk的源码是值得研究的。以下列出的优化点与具体的网卡性能方面的优化不一样,后者是个有挑战性的事情,下面的一些点可以使用到与dpdk无关的开发中。
- likely和unlikely的使用
在dpdk的example中,很多语句使用了如下的函数:
153 /* Send burst of TX packets, to second port of pair. */
154 const uint16_t nb_tx = rte_eth_tx_burst(port ^ 1, 0,
155 bufs, nb_rx);
156
157 /* Free any unsent packets. */
158 if (unlikely(nb_tx < nb_rx)) {
159 uint16_t buf;
160 for (buf = nb_tx; buf < nb_rx; buf++)
161 rte_pktmbuf_free(bufs[buf]);
162 }
253 /* Read packet from the ring */
254 nb_pkt = rte_ring_sc_dequeue_burst(conf->rx_ring, (void **)mbufs,
255 burst_conf.ring_burst);
256 if (likely(nb_pkt)) {
257 int nb_sent = rte_sched_port_enqueue(conf->sched_port, mbufs,
258 nb_pkt);
259
260 APP_STATS_ADD(conf->stat.nb_drop, nb_pkt - nb_sent);
261 APP_STATS_ADD(conf->stat.nb_rx, nb_pkt);
262 }
126 /* Branch prediction helpers. */
127 #ifndef likely
128 #define likely(c) __builtin_expect(!!(c), 1)
129 #endif
130 #ifndef unlikely
131 #define unlikely(c) __builtin_expect(!!(c), 0)
132 #endif
其中__builtin_expect原型如下:
long __builtin_expect(long exp, long c);!!(c)的效果是得到一个布尔值,该函数的作用是更好的分支预测;使用likely() ,执行if后面的语句的机会更大,使用unlikely(),执行else后面的语句的机会更大,原理“It optimizes things by ordering the generated assembly code correctly, to optimize the usage of the processor pipeline. To do so, they arrange the code so that the likeliest branch is executed without performing any jmp instruction (which has the bad effect of flushing the processor pipeline).”
主要是分支预测失误,指令的跳转带来的性能会下降很多。为什么呢?从《深入理解计算机系统》书上摘取,p141:“另一方面,错误预测一个跳转要求处理器丢掉它为该跳转指令后所有指令已经做了的工作,然后再开始用从正确位置处起始的指令去填充流水线,大约会浪费20〜40个时钟周期”;从汇编代码层面理解参考文末第一个引用。
- 指令预取
这里仅介绍的cache数据预取[空间局部性和时间局部性]。分为硬件预取和软件预取,前者根据不同的架构如NetBurst,由底层硬件预取单元根据一定条件自动激活预取,“一定的条件”比较复杂,比如读取的数据是回写的内存模型;没有连续的存储指令等,但有时并不一定能提高程序的执行效率。如在访问的数据结构没有规律的情况下,那么硬件预取会占用更多的带宽,浪费一级cache的空间,淘汰了程序本身存放在一级cache中的数据。
用的较多的是软件预取,由指令PREFETCH0~PREFETCH2,PREFETCHNTA组成,在开发过程中,把即将用到的数据从内存中加载到cache,后期直接命中cache,减小了从内存直接读取的延迟,减小了处理器的等待时间。
对于一级cache,延迟为3〜5个指令周期,二级cache为十几个指令周期,三级cache为几十个。
在dpdk例子中,常看到这样的语句:
341 /* for traffic we receive, queue it up for transmit */
342 uint16_t i;
343 rte_prefetch_non_temporal((void *)bufs[0]);
344 rte_prefetch_non_temporal((void *)bufs[1]);
345 rte_prefetch_non_temporal((void *)bufs[2]);
346 for (i = 0; i < nb_rx; i++) {
347 struct output_buffer *outbuf;
348 uint8_t outp;
349 rte_prefetch_non_temporal((void *)bufs[i + 3]);
350 /*
351 * workers should update in_port to hold the
352 * output port value
353 */
354 outp = bufs[i]->port;
355 /* skip ports that are not enabled */
356 if ((enabled_port_mask & (1 << outp)) == 0)
357 continue;
358
359 outbuf = &tx_buffers[outp];
360 outbuf->mbufs[outbuf->count++] = bufs[i];
361 if (outbuf->count == BURST_SIZE)
362 flush_one_port(outbuf, outp);
363 }
rte_prefetch_non_temporal的功能与PREFETCH0对应,即将数据存放在每一级cache中,在使用完一次后是可以被淘汰出动的。“Prefetch a cache line into all cache levels (non-temporal/transient version)
The non-temporal prefetch is intended as a prefetch hint that processor will use the prefetched data only once or short period, unlike the rte_prefetch0() function which imply that prefetched data to use repeatedly.”
其实现是内嵌汇编代码:
42 static inline void rte_prefetch0(const volatile void *p)
43 {
44 asm volatile ("pld [%0]" : : "r" (p));
45 }
57 static inline void rte_prefetch_non_temporal(const volatile void *p)
58 {
59 /* non-temporal version not available, fallback to rte_prefetch0 */
60 rte_prefetch0(p);
61 }
- cache相关
主要点是cache line,example中好些结构声明末尾有如下形式:
106 struct lcore_queue_conf {
107 unsigned n_rx_port;
108 unsigned rx_port_list[MAX_RX_QUEUE_PER_LCORE];
109 } __rte_cache_aligned;
#define RTE_CACHE_LINE_SIZE 64
#define __rte_cache_aligned __attribute__((__aligned__(RTE_CACHE_LINE_SIZE)))
就是定义一个变量时要按照cache line对齐,这样做的好处是一方面防止多线程中的false sharing而导致“抖动”问题,影响性能,另一方面如果变量所占空间跨line,则可能需要几次从内存加载和存储,再然后呢要求变量地址cache line对齐可能会浪费点内存空间。
cache line有四种状态,分别是modified,exclusive, shared, invalid,即MESI协议,为了解决一致性问题而出现的。很多理论性的可以查下wiki,我也记不清楚。“在dpdk中,避免多个核访问同一个内存地址或者数据结构。这样,每个核都避免与其他核共享数据,减少因为错误的数据共享而导致cache一致性的开销。”
具体cache相关的基础知识点可参考《深入理解计算机系统》,理解cache的工作原理,能写出较高效的代码。
- 本地内存
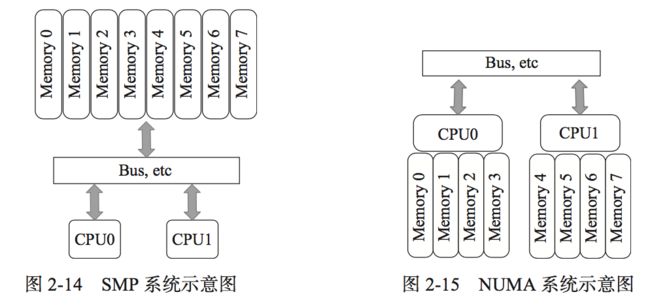
这个点与NUMA架构有关,在此之前,有必要解释下SMP架构。
SMP(Symmetric Multi Processing),即对称多处理系统,特点如下:
a)所有的CPU共享全部资源,如总线,内存和I/O系统等;
b)所有处理器都是平等的,没有主从关系;
c)内存是统一结构,统一寻址的(UMA:Uniform Memory Access);
d)cpu和内存,cpu之间是通过一条总线连接起来的;
但有以下缺点:
a)扩展能力非常有限;
b)随着cpu个数增加,系统总线成为了瓶颈,cpu与内存之间的通信延迟加大;
故出现了NUMA(Non Uniform Memory Access Architecture),即非一致存储器访问,特点如下:
a)cpu和本地内存拥有更小的延迟与更大的带宽;
b)整个内存可作为一个整体,任何cpu都能访问,跨本地内存访问较访问本地内存慢一些;
c)每个cpu可以有本地总线,和内存一样,访问本地总线延迟低,添吐率高;
两者如下图所示:
而在dpdk中的example使用中,可以看见如下代码使用方式:
150 /* helper to create a mbuf pool */
151 struct rte_mempool *
152 rte_pktmbuf_pool_create(const char *name, unsigned n,
153 unsigned cache_size, uint16_t priv_size, uint16_t data_room_size,
154 int socket_id)
根据该线程所在的socket_id去创建内存;
1183 int
1184 rte_eth_rx_queue_setup(uint8_t port_id, uint16_t rx_queue_id,
1185 uint16_t nb_rx_desc, unsigned int socket_id,
1186 const struct rte_eth_rxconf *rx_conf,
1187 struct rte_mempool *mp)
1265 int
1266 rte_eth_tx_queue_setup(uint8_t port_id, uint16_t tx_queue_id,
1267 uint16_t nb_tx_desc, unsigned int socket_id,
1268 const struct rte_eth_txconf *tx_conf)
根据该线程所在的socket_id去创建端口的收发队列;
161 struct rte_ring *
162 rte_ring_create(const char *name, unsigned count, int socket_id, unsigned flags)
根据该线程所在的socket_id去创建无锁环形buffer。
还有无锁的使用,cpu亲和性,ddio,内存交叉访问等...
参考:
https://kernelnewbies.org/FAQ/LikelyUnlikely
http://docs.oracle.com/cd/E19253-01/819-7057/6n91f8su6/index.html
http://www.cs.umd.edu/class/sum2003/cmsc311/Notes/Memory/direct.html
https://en.wikipedia.org/wiki/MESI_protocol
https://en.wikipedia.org/wiki/False_sharing
https://en.wikipedia.org/wiki/Symmetric_multiprocessing
https://en.wikipedia.org/wiki/Non-uniform_memory_access
http://www.tuicool.com/articles/j6vY7nq