![推荐系统遇上深度学习(七十一)-[华为]一种消除CTR预估中位置偏置的框架_第1张图片](http://img.e-com-net.com/image/info10/a58aef0a04e349bfba062cc15de2a164.jpg)
本文介绍的论文是:《PAL: A Position-bias Aware Learning Framework for CTR Prediction in Live Recommender Systems》
论文下载地址为:https://dl.acm.org/citation.cfm?id=3347033
在之前的youtube论文介绍中,曾经简单介绍过一些解决位置偏置的方法,本文来详细介绍下华为提出的解决广告推荐中位置偏置的方法。
1、背景
在广告推荐场景中,为了最大化广告收入,往往通过CTR * BID(BID是广告被点击一次平台所能获得的收入)对广告进行排序,BID基于广告主的出价,一般来说是平台不能控制的(当然有些平台有智能出价或者OCPC等调价方式),所以CTR预估显得至关重要。
一般的推荐系统,通过收集用户和广告的交互信息,来离线训练点击率预估模型,并应用于线上。但用户和广告的交互信息中存在一个很重要的影响因素,那就是广告的展示位置。
对于不同的位置来说,点击率是不同的,展示位置越靠前,则点击率越高。对于同一个广告来说,当它展示位置越靠前时,点击率同样是越高的,下面的两张图证明了这一点:
![推荐系统遇上深度学习(七十一)-[华为]一种消除CTR预估中位置偏置的框架_第2张图片](http://img.e-com-net.com/image/info10/fb9cb5f9e8bf4b7088db4ae536c6a12e.jpg)
这也就是说,收集到的训练样本中存在位置偏置(position bias)信息,用户点击某个广告,并非出于喜好,有可能仅仅与展示位置有关。所以在建模过程中有必要对这一部分位置偏置信息进行建模。
下一节中,我们来介绍一些消除位置偏置的方法。
2、解决位置偏置方法
首先我们假设收集到的离线训练数据为S={(xi,posi->yi)},其中xi是特征向量,包括用户特征、广告特征、交互特征和上下文特征,posi是广告展示的位置,yi是用户的点击结果。
一般的解决位置偏置的方法有两种,作为特征(as a feature)和作为模块(as a module)
2.1 位置信息作为特征
该方法的示意图如下所示:
![推荐系统遇上深度学习(七十一)-[华为]一种消除CTR预估中位置偏置的框架_第3张图片](http://img.e-com-net.com/image/info10/86b51dbb6e4a4c378717897e85c38642.jpg)
该方法把位置信息作为特征。在离线训练时,输入特征是特征向量和位置信息的拼接[x,pos],而在线上推断时,我们无法获取实时的位置信息,那么此时的做法有两种:
第一种做法就是一种暴力探索的方法,首先固定位置为1,然后计算所有广告相应的点击率,将点击率最高的一个广告放在第一个位置,接下来在固定位置为2,计算剩余广告相应的点击率,将点击率最高的广告放在第二个位置,依次类推。这样的做法显然是不可取的,主要是计算复杂度太高,线上性能无法保证。
第二种做法是当前工业界最为常见的做法,即固定为某一个位置,计算每个广告在该位置下的点击率,从而进行排序。但是,位置不同,所得到的推荐结果也相差很大,所以我们需要找到一个合适的位置,来得到最好的线上效果。此时往往需要通过线下评估的方式,即通过不同位置在相同测试集上的表现,来决定线上使用哪个位置。显然这种做法泛化性也是无法得到保证的。
2.2 位置信息作为模块
上面分析了将位置信息作为特征输入的不足之处,因此本文提出了一种将位置信息作为一个模块单独预测的方法,将在第三节中进行介绍。
值得一提的是,youtube在论文《Recommending What Video to Watch Next: A Multitask Ranking System》中也提出了一种作为模块的方法,来回顾一下:
![推荐系统遇上深度学习(七十一)-[华为]一种消除CTR预估中位置偏置的框架_第4张图片](http://img.e-com-net.com/image/info10/960f7f045bb54639901ca6fd33e7e299.jpg)
通过一个shallow tower(可理解为比较轻量的模型)来预测位置偏置信息,输入的特征主要是一些和位置偏置相关的特征。在sigmoid前,将shallow tower的输出结果加入进去。而在预测阶段,则不考虑shallow tower的结果。
3、PAL框架
本文提出的消除位置偏置信息的框架称为Position-bias Aware Learning framework (PAL) 。其基于如下的假设,即用户点击广告的概率由两部分组成:广告被用户看到的概率和用户看到广告后,点击广告的概率。

该假设可进一步进行化简,首先,用户是否看到广告只跟广告的位置有关系;其次,用户看到广告后,是否点击广告与广告的位置无关。此时公式可写作:
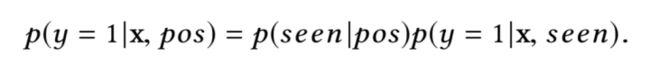
基于该假设,就可以分开建模,PAL的框架如下图所示:
![推荐系统遇上深度学习(七十一)-[华为]一种消除CTR预估中位置偏置的框架_第5张图片](http://img.e-com-net.com/image/info10/5bf3df0cf0b94db4b0d1750fcc0f5a60.jpg)
可以看到,两个模块是联合进行训练的,如果分开进行优化,两个模块的训练目标不同,可能导致整个的系统是次优化的。
损失函数采用交叉熵损失:
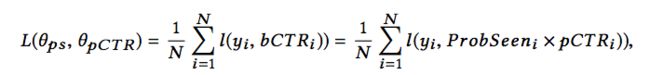
这里再说一下,论文中并没有给出训练位置信息的模块所使用的特征,可以参考youtube论文中的思路,加入位置特征和上下文特征来训练。
4、实验结果
本文主要对比了下图中两个模型,左边是本文提出的PAL框架,右边是将位置信息作为输入特征的方法,作为BASE:
![推荐系统遇上深度学习(七十一)-[华为]一种消除CTR预估中位置偏置的框架_第6张图片](http://img.e-com-net.com/image/info10/c30eca51c9994da7b19152d0415c37cb.jpg)
来看下实验结果,首先看下离线训练结果。由于在测试集上,BASE方法需要一个固定位置,因此本文尝试了1-10位置作为固定位置时,BASE方法的效果和PAL方法的对比:
![推荐系统遇上深度学习(七十一)-[华为]一种消除CTR预估中位置偏置的框架_第7张图片](http://img.e-com-net.com/image/info10/381ce436248c49e0b6388c6eef6ea648.jpg)
从离线结果来看,PAL方法并非是最优的方法。接下来看线上的效果,文章对比了PAL和固定位置是1、5、9时BASE方法的结果:
![推荐系统遇上深度学习(七十一)-[华为]一种消除CTR预估中位置偏置的框架_第8张图片](http://img.e-com-net.com/image/info10/869c1d733ca047a480e562bb96e53ab5.jpg)
尽管离线训练的效果并非是最优的,但是PAL相较于BASE方法,线上效果取得了巨大的提升。
5、总结
本文提出了一种消除位置偏置对点击率预估影响的框架。该框架下,将位置信息当作一个单独的模块,而非作为一个输入特征进行训练,线上效果取得了巨大的提升。