全文共2760字,预计学习时长6分钟或更长

机器学习算法变革了视觉领域与NLP(自然语言处理)领域,那音乐领域呢?近年来,音乐信息检索(MIR)发展势头迅猛。本文将探讨如何将NLP领域的技术应用到音乐领域。
近期, 在Chuan、Agres和 Herremans (2018)联合发表的一篇论文中,他们论述了用Word2vec(NLP的一种常用工具)表示复调音乐的过程。下文将对该过程展开深入探究。

Word2vec
有了词嵌入模型,就可以用代表语义的向量来表示词语,机器学习模型也能够更轻松地对其进行处理。而托马斯·米科洛夫等人在2013年提出的嵌入模型Word2vec,能够高效地创造语义向量空间(Mikolov et al., 2013)。
Word2vec模型的本质是一个简单的单层神经网络,该网络的构建方式有两种:1) 使用连续词袋(CBOW);2)使用Skip-gram 模型。这两种方式效率都很高,训练耗时也相对较短。此次研究用到了Skip-gram 模型,因为米科洛夫等人曾表示,该模型在处理较小的数据集方面更为高效。Skip-gram 模型选取当前词w_t作为输入层,并在输出层context window(上下文窗口)显示预测的关联词。

网上流传的一些图片让人误以为Skip-gram网络输出的只是context window中的一个单词,而非多个。那么怎样让Skip-gram表示整个context window呢?
训练Skip-gram网络时,我们使用了样本对,包括当前输入词和从context window随机选取的一个词。Skip-gram的传统训练目标是使用Softmax函数计算
,但这种方法运算量过大,成本过高。所幸,噪声对比估计 (Gutmann & Hyvärine, 2012)以及负采样 (Mikolov et al, 2013b)能够解决这一问题。先用负采样大致定义一个新目标,即将真实词的概率最大化,将噪声样本的概率最小化。之后只需要一个简单的二进制的逻辑回归,就能把噪声样本从真实词中分离出来。

能否用单词形式表示音乐?
音乐与语言本质上是相互联系的。二者均包含遵循一套语法规则的连续事件。更重要的是,二者均能使人产生预想。比如,如果有人说:“我要去披萨店买个……”,显然,你会预想他要买的是披萨。而如果有人现在哼一句“祝你生日”,然后戛然而止……正如话语一样,旋律也能引起人的预想,而这些预想能够通过脑电图进行测量,比如测量大脑中事件的相关电位N400(Besson & Schön, 2002)。
既然语言与单词间存在一定的相似度,那么语言表示常用模型可否有效地表示音乐呢?为了将MIDI(音序)文件转换为“语言”,要对音乐“片段”进行定义,这里的音乐片段相当于语言中的单词。将数据集中的音乐全部切分为相同长度,相互间不重叠的片段,每个片段长度为一个节拍。每个节拍的长度由MIDI 工具箱进行估算,不同片段的节拍长度可以不同。所有片段音高的等级都会保留下来,这里音高等级指的是不包含音阶信息的音高。
下图为肖邦作品67第4首,即A小调第47号玛祖卡舞曲第一小节,图中展示了如何决定片段的长度。在这里,一个节拍长度为一个四分音符。


Word2vec学习调性——音乐的分布式语义假设
在语言中,分布式语义假设是向量嵌入的驱动力。根据该假设,“在同一上下文中出现的词往往有相同的意思(Harris, 1954) ”。这些词转换到向量空间后,几何位置相近。那么Word2vec模型是否会用类似的方式表示音乐呢?
数据集
Chuan 等人用了包含八种不同音乐流派的MIDI 数据集,包含古典乐、重金属乐,他们从130,000支曲子中根据流派分类挑选出23,178首作为数据集。在挑选出的曲子中,总共分出了4,076种不同的片段。
超参数
Word2vec模型的训练只用到数据集中最常出现的500个片段(或词),其他词都用一个伪字代替。这一步骤提高了Word2vec模型的精确度,因为模型内的词可以包含更多的信息。此外还有其他超参数,如学习速率(设为0.1),window_size(设为4),训练步骤的数量(设为1,000,000),嵌入大小(设为256)。
和弦
要评价Word2vec模型是否成功地获取了音乐片段的语义,还需要了解和弦。
从音乐片段构成的词汇表中,识别出所有包含三和弦的音乐片段。用罗马数字标记这些片段的音级(这在乐理中很常见),比如,在C调中,和弦C为I级,和弦G为V级。之后,用余弦距离计算在向量空间中,不同音级和弦的相互距离。
在一个N维空间中,两个非零向量A和B之间的余弦距离的计算方式为:
其中θ为A和B的夹角,Ds为余弦相似度:
按乐理校对来讲,I级和弦和V级和弦之间的“调性”距离应当小于I级和弦和III级和弦之间的“调性”距离。下图表示一个C大调三和弦与其他和弦之间的距离。
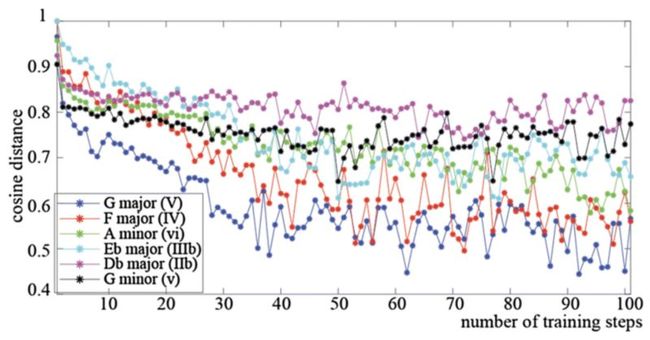
显然,I级三和弦与V级和弦, IV级和弦还有vi和弦之间的距离更小,这与音乐中这几个和弦间“调性相近”的理论吻合。也就是说,Word2vec模型学会了表现音乐片段之间的关系。
Word2vec空间中和弦之间的余弦距离似乎反映了和弦在乐理中的功能!
调
巴赫的十二平均律曲集(WTC)的24首前奏曲中,每首前奏曲都包含一个调,所以24首前奏曲涵盖了包括大调和小调在内的全部24个调。对于新的嵌入空间是否获取了有关调的信息的问题,可以通过研究十二平均律曲集求证。
把数据集扩大后,十二平均律曲集的各个前奏曲都被转换为其他大调或小调(取决于原来调的不同),导致每首前奏曲都出现了12种版本。将这些调的各个片段映射到先前训练的向量空间,使用K-Means进行聚类,就得到了新数据集中不同前奏曲的质心。将这些前奏曲转换为调,就保证了质心之间的余弦距离仅受调的影响。
在不同调的前奏曲中,质心之间产生的余弦距离如下图所示。正如预期那样,不同的五度和音的调性非常接近,图中对角线旁边较暗的区域即为证明。调性相差很大的调(例如F和F#)表现为橙色,说明Word2vec空间反映了调之间的调性距离,证实猜想成立。

类比
关于Word2vec有一个有趣的图像,表现的是向量空间中,国王→女王,男人→女人之间的转换过程 (Mikolov et al., 2013c),这也就说明了向量转换能够传达意义。那么向量是否也能传达音乐中的意义?
首先,我们检测了复调片段中的和弦,查看从C大调到G大调(I-V)和弦对的向量。不同I-V向量之间的夹角非常相似(见右图),甚至可以看作是五度和音构成的多维圆。这也再次证明,类比的概念可能存在于音乐领域的Word2vec空间中,但要得到更清楚的例子,还需要更多调查研究。


其他应用-Word2vec能否生成乐曲?
Chuan 等人 (2018) 简单探讨了Word2vec模型通过替代音乐片段来生成新的音乐的过程。他们表示,这只是一个初步测试,该系统可作为一种表示方法用于更综合的系统中,如LSTM。论文中还有更多细节描述,在此不作赘述。下图为研究结果。


结论
Chuan、Agres与Herremans (2018)建立了一个Word2vec模型,可以捕捉复调音乐的音调属性,而无需将实际音符输入模型之中。他们的论文有力地证明了,在词嵌入中能够找到关于调与和弦的信息。那么可否用Word2vec表示音乐呢?答案是肯定的,可以用Word2vec表示复调音乐。这就打开了一种新思路:还可以将这种表现形式嵌入其他模型中,用以捕捉音乐的时间信息。

留言 点赞 关注
我们一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”