Java线上问题排查思路及Linux常用问题分析命令学习
前言
之前线上有过一两次OOM的问题,但是每次定位问题都有点手足无措的感觉,刚好利用星期天,以测试环境为模版来学习一下Linux常用的几个排查问题的命令。
也可以帮助自己在以后的工作中快速的排查线上问题。
jmap命令
jmap -heap pid 输出当前进程 JVM 堆新生代、老年代、持久代等请情况,GC 使用的算法等信息
jmap -histo:live {pid} | head -n 10 输出当前进程内存中所有对象包含的大小
jmap -dump:format=b,file=/usr/local/logs/gc/dump.hprof {pid} 以二进制输出档当前内存的堆情况,然后可以导入 MAT 等工具进行
1、 jmap -heap pid
输出当前进程JVM堆新生代、老年代、持久代等情况,GC使用的算法等信息。
![[转]Java线上问题排查思路及Linux常用问题分析命令学习文章_第1张图片](http://img.e-com-net.com/image/info10/0e198a71681d4a2d8d70d088c7d3d0b7.png)
2、jmap -histo:live {pid} | head -n 10 输出当前进程内存中所有对象包含的大小
输出当前进程内存中所有对象实例数 (instances) 和大小 (bytes), 如果某个业务对象实例数和大小存在异常情况,可能存在内存泄露或者业务设计方面存在不合理之处。
![[转]Java线上问题排查思路及Linux常用问题分析命令学习文章_第2张图片](http://img.e-com-net.com/image/info10/9a5467d400bd4bb1876c8745f5801e3a.png)
jmap -dump:
命令如下:
mkdir logs
jmap -dump:format=b,file=/tmp/logs/dump.hprof {pid}
-dump:formate=b,file= 以二进制输出当前内存的堆情况至相应的文件,然后可以结合 MAT 等内存分析工具深入分析当前内存情况。
也可以通过JVM参数配置OOM时自动dump当前内存镜像文件。 -XX:+HeapDumpOnOutOfMemoryError 和-XX:HeapDumpPath所代表的含义就是当程序出现OutofMemory时,将会在相应的目录下生成一份dump文件,而如果不指定选项-XX:HeapDumpPath则在当前目录下生成dump文件。
确保应用发生 OOM 时 JVM 能够保存并 dump 出当前的内存镜像。
当然,如果你决定手动 dump 内存时,dump 操作占据一定 CPU 时间片、内存资源、磁盘资源等,因此会带来一定的负面影响。
此外,dump 的文件可能比较大 , 一般我们可以考虑使用 zip 命令对文件进行压缩处理,这样在下载文件时能减少带宽的开销。
下载 dump 文件完成之后,由于 dump 文件较大可将 dump 文件备份至制定位置或者直接删除,以释放磁盘在这块的空间占用。
dump 日志分析
MAT(Memory Analyzer Tool),一个基于 Eclipse 的内存分析工具,是一个快速、功能丰富的 JAVA heap 分析工具,它可以帮助我们查找内存泄漏和减少内存消耗。
使用内存分析工具从众多的对象中进行分析,快速的计算出在内存中对象的占用大小,看看是谁阻止了垃圾收集器的回收工作,并可以通过报表直观的查看到可能造成这种结果的对象。
具体可以参考:Java内存分析工具MAT(Memory Analyzer Tool)安装使用实例 : https://blog.csdn.net/jin_kwok/article/details/80326088 和 基于Java内存dump文件分析解决内存泄漏问题 : https://www.jianshu.com/p/2cf7169ba1c4
jstack命令
printf '%x\n' tid --> 10 进制至 16 进制线程 ID(navtive 线程) %d 10 进制
jstack pid | grep tid -C 30 --color ps -mp 8278 -o THREAD,tid,time | head -n 40
某 Java 进程 CPU 占用率高,我们想要定位到其中 CPU 占用率最高的线程。
(1) 先利用top命令找到CPU占用高的进程pid
也可以通过ps -ef | grep 应用名 来快速定位自己应用的pid
![[转]Java线上问题排查思路及Linux常用问题分析命令学习文章_第3张图片](http://img.e-com-net.com/image/info10/ab166f93ef3a40bba17d3eeab2349205.png)
显示pid:29080
(2) 利用 top 命令可以查出占 CPU 最高的线程 pid (先找到该pid 29080下所有的线程数据)
![[转]Java线上问题排查思路及Linux常用问题分析命令学习文章_第4张图片](http://img.e-com-net.com/image/info10/cffe9c98cb9042d19f9aded93b5e873a.png)
可以看到占用cpu资源最高的为29173
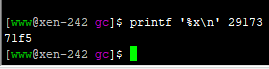
(3) 占用率最高的线程 ID 为29173,将其转换为 16 进制形式 (因为 java native 线程以 16 进制形式输出)
printf '%x\n' 29173
(4) 利用 jstack 打印出 java 线程调用栈信息
jstack 29080 | grep '0x71f5' -A 50 --color
![[转]Java线上问题排查思路及Linux常用问题分析命令学习文章_第5张图片](http://img.e-com-net.com/image/info10/02df8cc9b1d0406e8abcd7014485a52d.jpg)
可以看到这个线程是在做kafka相关的操作。因为这是测试,所以并不是因为CPU真的占用过高的情况。
更多内容也可以参考:
如何使用jstack分析线程状态 : https://www.jianshu.com/p/6690f7e92f27
通过jstack与jmap分析一次线上故障: https://www.cnblogs.com/kingszelda/p/9034191.html
jinfo命令
jinfo可以用来查看正在运行的java运用程序的扩展参数。
查看pid对应的JVM参数,可以到 PerfMa : http://xxfox.perfma.com/jvm/check 校验参数的正确性
jinfo -flags pid
拿到Command line后面的配置参数到perfma中验证查询:
![[转]Java线上问题排查思路及Linux常用问题分析命令学习文章_第6张图片](http://img.e-com-net.com/image/info10/5330b84d37014e58a303f42cf849c8c0.jpg)
这里面好多功能可以去使用。
jstat命令
jstat:Java Virtual Machine statistics monitoring tool JDK自带的一个轻量级小工具。
jstat显示GC执行的情况
jstat -gc 12538 5000
即会每5秒一次显示进程号为12538的java进成的GC情况
![[转]Java线上问题排查思路及Linux常用问题分析命令学习文章_第7张图片](http://img.e-com-net.com/image/info10/5a5b97760de241c2bf1ddf8d4e5cb781.png)
说明:
S0C、S1C、S0U、S1U:Survivor 0/1区容量(Capacity)和使用量(Used)
EC、EU:Eden区容量和使用量
OC、OU:年老代容量和使用量
PC、PU:永久代容量和使用量
YGC、YGT:年轻代GC次数和GC耗时
FGC、FGCT:Full GC次数和Full GC耗时
GCT:GC总耗时
显示内容说明如下(部分结果是通过其他其他参数显示的,暂不说明):
S0C:年轻代中第一个survivor(幸存区)的容量 (字节)
S1C:年轻代中第二个survivor(幸存区)的容量 (字节)
S0U:年轻代中第一个survivor(幸存区)目前已使用空间 (字节)
S1U:年轻代中第二个survivor(幸存区)目前已使用空间 (字节)
EC:年轻代中Eden(伊甸园)的容量 (字节)
EU:年轻代中Eden(伊甸园)目前已使用空间 (字节)
OC:Old代的容量 (字节)
OU:Old代目前已使用空间 (字节)
PC:Perm(持久代)的容量 (字节)
PU:Perm(持久代)目前已使用空间 (字节)
YGC:从应用程序启动到采样时年轻代中gc次数
YGCT:从应用程序启动到采样时年轻代中gc所用时间(s)
FGC:从应用程序启动到采样时old代(全gc)gc次数
FGCT:从应用程序启动到采样时old代(全gc)gc所用时间(s)
GCT:从应用程序启动到采样时gc用的总时间(s)
总结
一般分析CPU或者内存异常情况可以通过以下几步:
查看日志
查看CPU情况
查看TCP情况
查看java线程,jstack
查看java堆,jmap
通过MAT分析堆文件,寻找无法被回收的对象
参考:
Java线上问题排查思路与工具使用 : https://blog.csdn.net/GitChat/article/details/79019454