在NLP领域,在神经网络兴起之前,条件随机场(CRF)一直是作为主力模型的存在,就算是在RNN系(包括BERT系)的模型兴起之后,也通常会在模型的最后添加一个CRF层,以提高准确率。因此,CRF是所有NLPer必须要精通且掌握的一个模型,本文将优先阐述清楚与CRF有关的全部基本概念,并详细对比HMM,最后献上BI-LSTM+CRF的实战代码及理解。相信读完本文,将对CRF的认识有一个新的高度。
在阅读本文之前,务必对概率图模型基础有一个全盘的掌握,若对此没有信心的,可以先参考我之前的一篇总结文:概率图模型基础
本文的基本目录如下:
基础知识
1.1 CRF到底是什么?
1.2 如何用CRF建模?
1.3 CRF与HMM的区别是什么?BILSTM+CRF实战
2.1 为什么需要添加CRF层?
2.2 如何计算损失函数?
2.3 实战环节
------------------第一菇 - 基础知识------------------
1.1 CRF到底是什么?
本段主要用于讲述与CRF有关的基础概念。
大部分人理解CRF都会被带到一个奇怪的误区里面(包括我之前),因为总是理解完了HMM以后,就会立马投入到CRF的学习里面,所以就会理所当然的认为CRF就是HMM的升级版(确实从模型效果上可以这么理解),然后一直把HMM的各自概念往CRF上套,之后两厢一对比,就会有点犯迷糊了,好多东西也对不上啊~然后,再一看书里的结论,啥?CRF竟然是判别式模型,HMM是生成式模型!这是什么鬼啦?CRF不就是HMM解除各自限制(有向图变无向图,箭头指的方向更多了吗!?!?),怎么突然就变成判别式模型啦!?废话不多说,如果有此疑问的同学,就说明看对文章了,不要心急慢慢看,我将一一解释清楚;而对此毫无疑问的同学,那可以直接跳到实战环节了哈。
CRF真的是判别式模型!准确说是,判别式无向图模型!
大家要牢记,区别判别式模型与生成式模型最基本的就是去判断模型是对联合分布进行建模,还是对条件分布进行建模。HMM中很显然,模型是对的联合分布进行建模(不清楚的同学,还请移步HMM专区),而CRF则不然,其试图对多个变量在给定观测值后的条件概率进行建模,因此属于判别式模型。(各位抱着学新东西的心态来学CRF,把HMM抛在脑后把)
具体展开来看,若令为观测序列,为与之对应的标记序列,则条件随机场的目标是构建条件概率模型。值得注意的是,标记变量可以是结构型变量,即其分量之间具有某种相关性。就比如在NLP领域中的词性标注任务,观测数据为单词序列(即为),标记为相应的词性序列(即为),且其具有线性序列结构。
1.2 如何用CRF建模?
令表示结点与标记变量中元素一一对应的无向图,表示与结点对应的标记变量,表示结点的邻接结点,若图的每个变量都满足马尔可夫性(即只与其相邻的结点有关),即,
则构成一个条件随机场。而理论上来说,图G可具有任意结构,只要能表示标记变量之间的条件独立性关系即可,但在现实应用中,尤其是对标记序列建模时候,最常用的仍然是链式结构,即“链式条件随机场(chain-structured CRF)”,也是我们接下来主要要讨论的一种条件随机场。

那我们该如何定义呢?
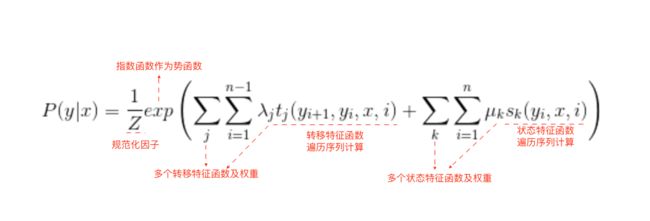
参考《机器学习》第14章的原文,其定义的方式类似马尔可夫随机场模型定义的联合概率。条件随机场使用势函数和图结构上的团来定义条件概率!如上图所示,该链式条件随机场主要包含两种关于标记变量的团,即单个标记变量以及相邻的标记变量。选择合适的势函数,即可得到形如马尔可夫随机场中联合概率的定义。
在条件随机场中,通过选用指数势函数并引入特征函数,条件概率被定义如下,
注意哈,这里的指的是整一个观测序列!而且这里定义的条件概率计算方式,就只是将观测序列作为条件,并不对其作任何独立性假设!!!(这点很重要!也是其是判别式模型的重要依据)
其中,是定义在观测序列的俩个相邻标记位置上的转移特征函数,用于刻画相邻标记变量之间的相关关系以及观测序列对他们的影响。即给定观测序列,其标注序列在及位置上标记的转移概率!而特征函数的定义往往不止一种,因此会有一个下标代表要遍历计算每一种特征函数的取值。
另外,是定义在观测序列的标记位置上的状态特征函数,用于刻画观测序列对标记变量的影响。即表示对于观察序列其位置的标记概率。同理,也有多种特征函数,所以会有下标。
剩下的就比较简单理解,都是参数,为规范化因子,用于确保上式是被正确定义的概率(可以理解为类似softmax的操作)。
总结一下上式,可以理解为如下图,
至此,整个概率的定义想必大家已经烂熟于心了~显然,要运用好条件随机场,最重要的就是要去定义合适的特征函数了。特征函数通常是实值函数,以刻画数据的一些很可能成立或期望成立的经验特性。因此定义特征函数的时候,一般都可以定义一组关于观察序列的二值特征来表示训练样本中某些分布特性,比如词性标注任务,
等等类似的特征函数,能定义好多出来的。因此,小小总结一下,CRF与马尔可夫随机场均使用团上的势函数定义概率,两者在形式上并没有显著区别,只不过CRF处理的是条件概率,而马尔可夫随机场处理的是联合概率。至此,整个CRF的建模已经讲明白了。
1.3 CRF与HMM的区别是什么?
CRF与HMM的一些基本定义的概念区别这边在讲概率图模型和上面的基础定义时已经表述的很清楚了,本段就不继续展开了~这里主要讲一下HMM的标注偏置问题,以及CRF为何能解决这个问题。
其实要想解释清楚标注偏置问题,大家只要看如下贴的一张图即可,

大家可以发现,状态1倾向于转移到状态2,状态2倾向于转移到状态2本身,但是实际计算得到的最大概率路径是1>1>1>1,状态1并没有转移到状态2!这其实是与我们的直觉相悖的~究其本质原因,从状态2转移出去可能的状态包括1,2,3,4,5,概率在可能的状态上分散了,而状态1转移出去的可能状态仅仅为状态1和2,概率更加集中!(大家可以拿笔算一下,是不是这么个理~加深理解)由于局部归一化的影响,隐状态会倾向于转移到那些后续状态可能更少的状态上,以提高整体的后验概率!这就是标注偏置问题!
而CRF如上所述,因为有归一化因子(Z)的存在,其在全局范围内进行了归一化,枚举了整个隐状态序列的全部可能,从而解决了局部归一化带来的标注偏置问题。而这也是CRF在很多问题上,表现比HMM优秀的原因~
------------------第二菇 - BILSTM+CRF实战------------------
介绍了这么多CRF有关的东西,想必各位也是跃跃欲试,我这边也献上一份BILSTM+CRF的实战解析,包括对此模型架构的理解以及源码的解读~
这里贴一个链接,是一个外国小哥写的博客,当初就是看这个博客明白其原理的,所以也特地在这边贴出来,英文好的同学也可以直接看这个链接,我就不单独放在参考文献里了。
为了便于理解,代码都是用Pytorch写的,且还是以命名实体识别任务为具体例子。
如果看到这篇文章的是初学者,也不用慌,就简单理解BILSTM和CRF为一个命名实体识别模型中的两个层。
为了便于理解下面的图示,这边假设我们的数据集有两大类,人名和地名,与之相对应在我们的训练数据集中,有五类标签:
* B-Person
* I-Person
* B-Organization
* I-Organization
* O
假设句子由5个字符组成,即,其中为人名实体,为组织实体,其他字符的标签为"O"。
2.1 为什么需要添加CRF层?
这里先直接贴一张BILSTM-CRF的模型结构图,方便大家理解。
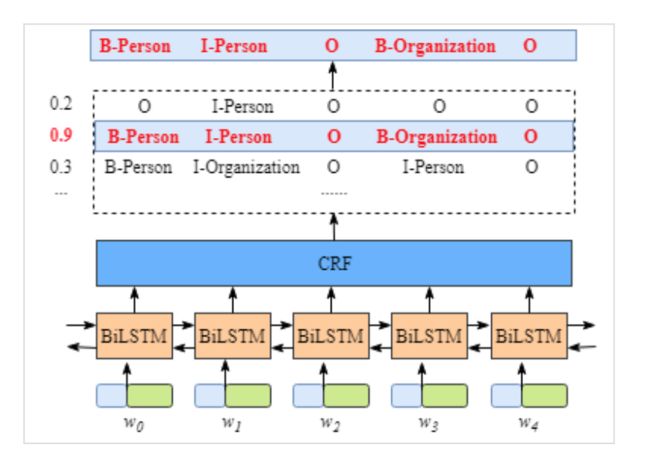
从下往上看,最下面就是输入(字或词向量),由于是序列模型,因此,在“时间”纬度上进行展开,就可以得到如图所示的模型表示,对应于一个时刻,就是输入一个字/词向量(一般都是预先训练得出的)。
首先,是经过BiLSTM的结构单元。这个比较好理解,本质上就是俩个LSTM层,只不过一次是正序输入,一次是倒序输入,然后把俩个结果进行concact(拼接),并输入到CRF层,最后由CRF层输出每一个词的标签~如果没有CRF层的话,传统的神经网络都会加一层softmax层用于归一化并输出每个标签概率。
为了更容易理解CRF层的作用,我们还是先要理清Bi-LSTM的输出。这里再贴一张图,方便大家理解,
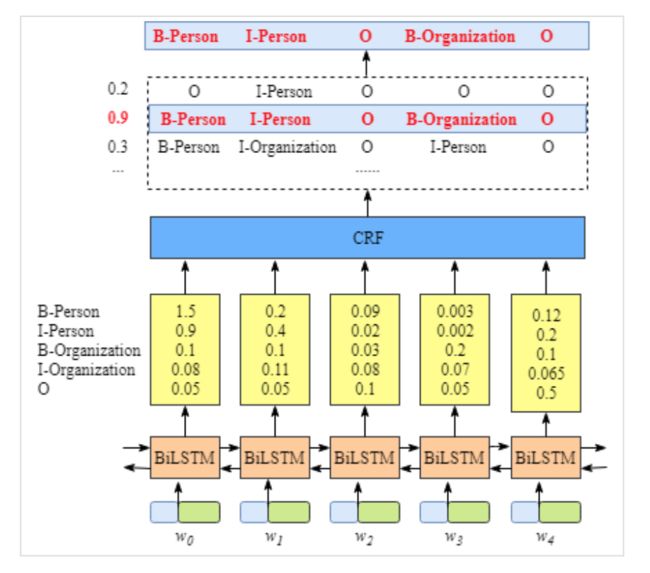
大家可以看到,其输出十分简单清晰,就是对于每一个单词,其对应每一个标签的分值(score)。因此,就算没有CRF层,该模型依旧有效,我们只需要挑选每一个标签对应最大的分值就可以,比如,就是。因此,在原有模型本身就有效的情况下,我们再添加一层CRF的目的肯定只有一个,即提高模型的准确率。
接下来,我们就要重点分析一下,CRF层的作用。先上结论,CRF层的主要作用是为最后预测的标签添加一些约束来保证预测标签的合理性!比如,在命名实体识别任务中,我们可以想到的约束可以是,
1)开头的标签只能是B, O,而不可能是I-
2)B-Person开头的标签,后面不可能接一个I-Organization
。。。
有了如上约束,我们就能保证,最终预测生成的标签序列的不合理性就会大大降低,而单凭BiLSTM的输出来预测是无法保证标签序列的合理性的~
2.2 损失函数的定义及计算
弄清楚了CRF层的作用以后,我们就要来仔细研究研究CRF层的运行原理了,主要从其损失函数的角度来理解。
2.2.1 CRF中的两种分数
在CRF层的损失函数中,有两种形式的score(分数),第一个就是emission score(发射分数),主要就是来自于BiLSTM层的输出(如上图所示),假设我们给每一个标签一个索引,那么第一个单词的emission score就是,~
注:大家可千万注意了,不要把这里的score和HMM里面的发射概率矩阵相混淆!两者可是完全不一样的,在HMM中,每一个单词的发射概率,仅与当前的隐状态层有关!是由隐状态决定了当前单词的发射概率!而这里的发射分数,是由当前输入的序列,决定的当前状态的概率!这里是整一个序列哦!若大家还能记得CRF层的定义和概率模型图(往上翻一翻),想必对此并不会惊讶!而这,也是CRF层能接在神经网络最后一层的主要原因!大家对此一定要有深刻的理解和认识。
第二个就是transition score(转移分数),这个倒是跟HMM中的状态概率转移矩阵相类似,也很好理解,也是模型中主要学习的参数!而且为了使模型更具有鲁棒性,我们额外增加了俩个标签,和,代表句子的开始位置,而非第一个词,同理代表句子的结束位置,这里也贴一张transition score矩阵的图,方便大家理解,

大家从图中应该很清楚可以看到,其能学到很多约束规则!因此,该矩阵也是模型主要训练的一个参数,一般一开始都会初始化一个概率转移矩阵,随着训练的迭代,逐渐合理~因此,接下来,我们就要来看看,其损失函数是如何设计的,才能学到合理的参数~
2.2.2 损失函数的设计
先明确一点,损失函数就是我们要优化的目标,那对于这样一个序列标注问题,我们肯定是希望,正确的序列,是所有的可能序列中,得分最高的!就如同我们作HMM解码的时候,利用维特比算法解码,我们返回的肯定是概率最大的那条路径一般,那反过来,我们训练的时候,自然希望得到的参数,能使得正确路径的概率最大~
有了上述的核心思想,我们再来想一想,如何求解。假设一共有种可能的标签序列组合,记第i个标签序列的得分为,那么所有可能标签序列组合的总得分为,
因此,我们可以设想出一个损失函数,就是真实序列的分数在所有可能的序列中占比最高,即,
由这个损失函数,引出2个问题,
1)如何定义计算每一个序列的得分?
2)如何计算所有标签序列的总得分?
2.2.3 求解一个序列的得分
先来看第一个问题,上述曾提过俩个分数概念,emission score和transition score,因此,一个序列的得分也有这俩个构成。
看到这个公式,大家再与CRF定义相联系,有木有看出点什么花头?没错,这个跟CRF定义的条件概率几乎是类似的哦,基本上可以理解为,BiLSTM的输出(也就是EmissionScore)取代来状态特征函数的位置,而我们要学习的参数也就是转移特征函数及其权重。所有,CRF与神经网络的配套组合并不是强行加上或者巧合,而是有理论作强支撑的哈哈~
我们逐一来理解每一个分数的计算过程,假设我们有一个正确的序列标注为,
那么,
其中,就表示第index个词被标记为label的得分(直接是从神经网络的输出能拿到的)。
而另一个转移分数即为,
其中,就表示label1 到 label2的转移概率,也就是模型要学习的参数~
2.2.4 计算所有序列总分数的方法
至此,每一条路径的总得分,就可以根据上面的式子很轻松的计算得出~但显然,如果真实计算也是如此遍历操作的话,时间复杂度会吃不消的,因此我们需要一个高效的算法来计算~
我们先简化一下损失函数,

简化之后,可以很轻松的看出,前半部分的计算是固定的,我们只需要高效的计算出后半部分即可,
很明显,这里会运用到动态规划的思想(不懂动态规划的,直接去看一下维特比算法,加深理解)来进行求解,即利用的总得分来推出的总得分,最后以此类推,每一次计算都需要利用到上一步计算得到的结果。
这里举一个简单的示例,假设句子长度为3(),标签有2个(),我们学到的Emission Score 矩阵如下(BiLSTM输出),
学习到的Transition Score矩阵如下,
接下来,将演示如何计算总得分,因为是动态规划的思想,只需演绎出其中一步即可~
针对,很轻松,因为没有转移分数,仅有发射分数,因此在第一个位置的总得分即为两种路径的分数总和,而现在两种路径就是两种可能性,要么就是标签1要么就是标签2,而这也是整个动态规划开始的初始条件~)
接下来,我们要求在第二个位置的总得分,注意我们的推导式子就是由推出的,因此我们直接利用计算得出的分数即可~如下图所演示的~
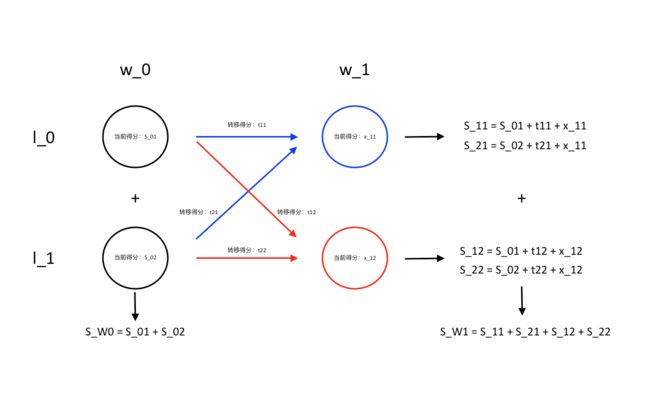
上述的动态核心式子即为,
最终,将在位置的所有状态求和得分相加即是总路径的得分~
有人可能会问,那你这不是只有一个位置的得分了吗?我们不是要求得总路径得分吗?有这个疑惑的同学应该就是还没有领悟到动态规划的精髓,建议自己手动推导一遍,便可迎刃而解~至此,整一个所有序列路径的求和方法,我们已经大致了解清楚了~(多提一句,预测阶段的解码思路,其实就是维特比算法,也是动态规划的思路,十分简单,这里就不多说了~)
2.3 实战环节
上面两节已经把BiLSTM+CRF讲的清清楚楚了~光看理论还不够,我们要深入代码实战环节(注:此乃网上找的一个Pytorch的版本,个人觉得是写的比较好的,只限用于理解理论,并非商业应用)
我们首先导入相应的包和定义一些后面要用到的辅助函数,如下,
import torch
import torch.nn as nn
import torch.optim as optim
torch.manual_seed(1)
# some helper functions
def argmax(vec):
# return the argmax as a python int
# 第1维度上最大值的下标
# input: tensor([[2,3,4]])
# output: 2
_, idx = torch.max(vec,1)
return idx.item()
def prepare_sequence(seq,to_ix):
# 文本序列转化为index的序列形式
idxs = [to_ix[w] for w in seq]
return torch.tensor(idxs, dtype=torch.long)
def log_sum_exp(vec):
#compute log sum exp in a numerically stable way for the forward algorithm
# 用数值稳定的方法计算正演算法的对数和exp
# input: tensor([[2,3,4]])
# max_score_broadcast: tensor([[4,4,4]])
max_score = vec[0, argmax(vec)]
max_score_broadcast = max_score.view(1,-1).expand(1,vec.size()[1])
return max_score+torch.log(torch.sum(torch.exp(vec-max_score_broadcast)))
START_TAG = ""
END_TAG = ""
这里定义的几个辅助函数都比较直观,唯独log_sum_exp可能会对大家造成一点困扰,但其实这是一种考虑数值稳定性的求解办法,具体大家参考这篇博文即可,深究一下也是好事情,不深究的就明白这个函数是为了求即可~
我们接着看模型的定义,
# create model
class BiLSTM_CRF(nn.Module):
def __init__(self,vocab_size, tag2ix, embedding_dim, hidden_dim):
super(BiLSTM_CRF,self).__init__()
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.tag2ix = tag2ix
self.tagset_size = len(tag2ix)
self.word_embeds = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim//2, num_layers=1, bidirectional=True)
# maps output of lstm to tog space
self.hidden2tag = nn.Linear(hidden_dim, self.tagset_size)
# matrix of transition parameters
# entry i, j is the score of transitioning to i from j
# tag间的转移矩阵,是CRF层的参数
self.transitions = nn.Parameter(torch.randn(self.tagset_size, self.tagset_size))
# these two statements enforce the constraint that we never transfer to the start tag
# and we never transfer from the stop tag
self.transitions.data[tag2ix[START_TAG], :] = -10000
self.transitions.data[:, tag2ix[END_TAG]] = -10000
self.hidden = self.init_hidden()
def init_hidden(self):
return (torch.randn(2, 1,self.hidden_dim//2),
torch.randn(2, 1,self.hidden_dim//2))
def _forward_alg(self, feats):
# to compute partition function
# 求归一化项的值,应用动态归化算法
init_alphas = torch.full((1,self.tagset_size), -10000.)# tensor([[-10000.,-10000.,-10000.,-10000.,-10000.]])
# START_TAG has all of the score
init_alphas[0][self.tag2ix[START_TAG]] = 0#tensor([[-10000.,-10000.,-10000.,0,-10000.]])
forward_var = init_alphas
for feat in feats:
#feat指Bi-LSTM模型每一步的输出,大小为tagset_size
alphas_t = []
for next_tag in range(self.tagset_size):
# 取其中的某个tag对应的值进行扩张至(1,tagset_size)大小
# 如tensor([3]) -> tensor([[3,3,3,3,3]])
emit_score = feat[next_tag].view(1,-1).expand(1,self.tagset_size)
# 增维操作
trans_score = self.transitions[next_tag].view(1,-1)
# 上一步的路径和+转移分数+发射分数
next_tag_var = forward_var + trans_score + emit_score
# log_sum_exp求和
alphas_t.append(log_sum_exp(next_tag_var).view(1))
# 增维
forward_var = torch.cat(alphas_t).view(1,-1)
terminal_var = forward_var+self.transitions[self.tag2ix[END_TAG]]
alpha = log_sum_exp(terminal_var)
#归一项的值
return alpha
def _get_lstm_features(self,sentence):
self.hidden = self.init_hidden()
embeds = self.word_embeds(sentence).view(len(sentence),1,-1)
lstm_out, self.hidden = self.lstm(embeds, self.hidden)
lstm_out = lstm_out.view(len(sentence), self.hidden_dim)
lstm_feats = self.hidden2tag(lstm_out)
return lstm_feats
def _score_sentence(self,feats,tags):
# gives the score of a provides tag sequence
# 求某一路径的值
score = torch.zeros(1)
tags = torch.cat([torch.tensor([self.tag2ix[START_TAG]], dtype=torch.long), tags])
for i , feat in enumerate(feats):
score = score + self.transitions[tags[i + 1], tags[i]] + feat[tags[i + 1]]
score = score + self.transitions[self.tag2ix[END_TAG], tags[-1]]
return score
def _viterbi_decode(self, feats):
# 当参数确定的时候,求解最佳路径
backpointers = []
init_vars = torch.full((1,self.tagset_size),-10000.)# tensor([[-10000.,-10000.,-10000.,-10000.,-10000.]])
init_vars[0][self.tag2ix[START_TAG]] = 0#tensor([[-10000.,-10000.,-10000.,0,-10000.]])
forward_var = init_vars
for feat in feats:
bptrs_t = [] # holds the back pointers for this step
viterbivars_t = [] # holds the viterbi variables for this step
for next_tag in range(self.tagset_size):
next_tag_var = forward_var + self.transitions[next_tag]
best_tag_id = argmax(next_tag_var)
bptrs_t.append(best_tag_id)
viterbivars_t.append(next_tag_var[0][best_tag_id].view(1))
forward_var = (torch.cat(viterbivars_t) + feat).view(1, -1)
backpointers.append(bptrs_t)
# Transition to STOP_TAG
terminal_var = forward_var + self.transitions[self.tag2ix[END_TAG]]
best_tag_id = argmax(terminal_var)
path_score = terminal_var[0][best_tag_id]
# Follow the back pointers to decode the best path.
best_path = [best_tag_id]
for bptrs_t in reversed(backpointers):
best_tag_id = bptrs_t[best_tag_id]
best_path.append(best_tag_id)
# Pop off the start tag (we dont want to return that to the caller)
start = best_path.pop()
assert start == self.tag2ix[START_TAG] # Sanity check
best_path.reverse()
return path_score, best_path
def neg_log_likelihood(self, sentence, tags):
# 由lstm层计算得的每一时刻属于某一tag的值
feats = self._get_lstm_features(sentence)
# 归一项的值
forward_score = self._forward_alg(feats)
# 正确路径的值
gold_score = self._score_sentence(feats, tags)
return forward_score - gold_score# -(正确路径的分值 - 归一项的值)
def forward(self, sentence): # dont confuse this with _forward_alg above.
# Get the emission scores from the BiLSTM
lstm_feats = self._get_lstm_features(sentence)
# Find the best path, given the features.
score, tag_seq = self._viterbi_decode(lstm_feats)
return score, tag_seq
上面的注释应该说是很详细了,一开始的初始化定义也都是Pytorch的常规写法(的代码显示的略诡异,大家将就看看吧)~LSTM层也是直接掉的nn里面的,只有CRF层是自己手撸上来的~所以,大家重点关注一下_forward_alg这个函数,就是我们上面讲的求解路径总得分的函数~其中feats就是序列步长,自然是要顺序遍历每一个feat,其中每一个feat又要遍历每一种tag的情况,利用forward_var记录每一个路径的总得分(实时更新),最后在求和即可!应该说看懂了上面的解释的同学,在看这个代码,简直是太简单了哈哈~其他的函数也没啥好特地强调的,大家扫一眼明白即可,对解码不清楚的,直接看代码也难,手动推演一遍,理解的更快~
最后,我们再来看一下主函数,
if __name__ == "__main__":
EMBEDDING_DIM = 5
HIDDEN_DIM = 4
# Make up some training data
training_data = [(
"the wall street journal reported today that apple corporation made money".split(),
"B I I I O O O B I O O".split()
), (
"georgia tech is a university in georgia".split(),
"B I O O O O B".split()
)]
word2ix = {}
for sentence, tags in training_data:
for word in sentence:
if word not in word2ix:
word2ix[word] = len(word2ix)
tag2ix = {"B": 0, "I": 1, "O": 2, START_TAG: 3, END_TAG: 4}
model = BiLSTM_CRF(len(word2ix), tag2ix, EMBEDDING_DIM, HIDDEN_DIM)
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=1e-4)
# Check predictions before training
# 输出训练前的预测序列
with torch.no_grad():
precheck_sent = prepare_sequence(training_data[0][0], word2ix)
precheck_tags = torch.tensor([tag2ix[t] for t in training_data[0][1]], dtype=torch.long)
print(model(precheck_sent))
# Make sure prepare_sequence from earlier in the LSTM section is loaded
for epoch in range(300): # again, normally you would NOT do 300 epochs, it is toy data
for sentence, tags in training_data:
# Step 1. Remember that Pytorch accumulates gradients.
# We need to clear them out before each instance
model.zero_grad()
# Step 2. Get our inputs ready for the network, that is,
# turn them into Tensors of word indices.
sentence_in = prepare_sequence(sentence, word2ix)
targets = torch.tensor([tag2ix[t] for t in tags], dtype=torch.long)
# Step 3. Run our forward pass.
loss = model.neg_log_likelihood(sentence_in, targets)
# Step 4. Compute the loss, gradients, and update the parameters by
# calling optimizer.step()
loss.backward()
optimizer.step()
# Check predictions after training
with torch.no_grad():
precheck_sent = prepare_sequence(training_data[0][0], word2ix)
print(model(precheck_sent))
# 输出结果
# (tensor(-9996.9365), [1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
# (tensor(-9973.2725), [0, 1, 1, 1, 2, 2, 2, 0, 1, 2, 2])
也是比较常规的写法,还带了示例~大家应该很容易理解的!
至此,整一套跟CRF有关的知识点和代码解释已经全部弄清楚了。简单总结一下本文,先是详细解释了一下与CRF有关的一些误区和知识点,接着展示了与CRF有关的用法和计算损失函数的方法,最后献上了详细的代码解读~希望大家读完本文后对CRF的一些概念会有一个全新的认识。有说的不对的地方也请大家指出,多多交流,大家一起进步~