
在上篇文章《区块的持久化之BoltDB(四)》中,我们分析了读写Transaction Commit时的各个步骤,其中重要的是与Bucket对应的B+Tree节点的旋转与分裂过程,在这两个过程中会涉及到B+Tree node的删除、新建,对应地,会有磁盘page的回收和分配等操作。为了弄清楚读写Transaction Commit时磁盘页面的变化,同时也为了便于我们分析BoltDB的MVCC机制,我们在介绍只读Transaction查找数据库之前,先来分析写数据库时BoltDB中各页的状态变化。
我们前文分析过,在读写Transaction Commit时,页面的分配和回收可能会伴随着文件大小的调整及remmap过程,根据需要分配的页的情况,可以分为: 1) 需要增加文件大小,不需要remmap; 2) 需要增加文件大小,需要remmap; 3) 不需要增加文件大小,需要remmap;4) 不需要增加文件大小,不需要remmap等情况,如下图所示:
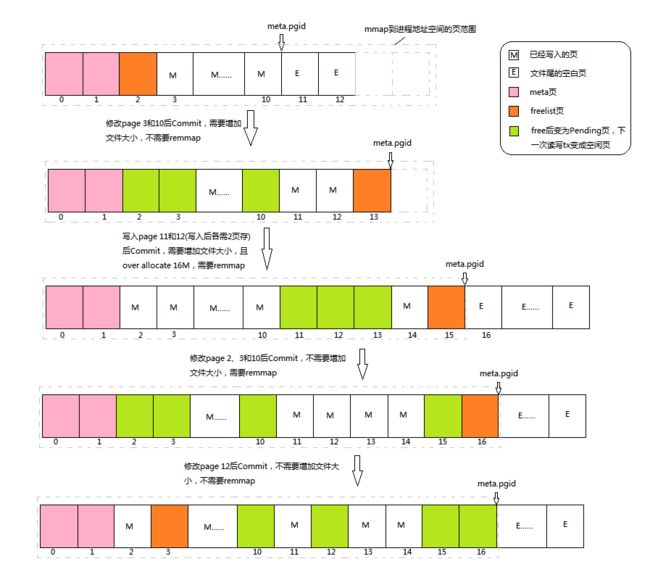
图中灰色虚线框表示mmap映射到内存的页范围,黑色实线框表示一个磁盘页,meta.pgid指向文件内容结尾处,文件实际大小可能大于其中内容大小,这时文件结尾处有空白页,如图中最上面的布局所示。接下来我们结合上图来分析这四种情况下页状态的变化:
需要增加文件大小,不需要remmap
当在bolt.Open()中打开或者创建数据库文件,进行初次mmap内存映射时,如果指定一个较大的options.InitialMmapSize值,就会出现内存映射范围超过实际文件大小的情况。如果meta.gpid没有指向文件结尾处或者说文件结尾处有空白页,那么在打开一个Transaction后,它看到的磁盘布局就有可能是图中第一种情形。需要说明的是,除meta页外,图中标注的页号只是示意,并不代表实际情况。
图中,我们假设在一个读写Transaction中修改page 3和page 10,但是请注意,Transaction并不直接读写page中的数据,而且将其实例化为node后,修改node中的记录,随后在Transaction Commit时,node经过旋转和分裂后再被写入磁盘页。如果我们只是更新了这两个node中的某个Key的值,且值的size没有变化,那么Bucket在rebalance时,将不会发生变化;在spill时,这两个node试着分裂,由于没有增加记录且大小也没有变化,它们均不会被分裂,然而,根据node.spill()中代码(5)处,原来的node将通过freelist.free()被标记为Pending页,同时为原来的node重新分配新的页。需要说明的是,Pending页表示即将(下一次读写Transaction)被释放的页,在本次Transaction中不能被重用。在分配新的页时,db.allocate()中会在freelist查可用的空闲页,我们图中假设的情况下,meta.pgid之前的页没有空闲页,所以将内容结尾处对应的页号page 11分配给新页,并将meta.pgid向后移;这时也会检查是否需要remmap,此时内存映射范围仍大于新的文件内存范围(page 11),故不需要remmap。当两个node均spill()且freelist页重新分配后,通过tx.write()写磁盘,磁盘布局将变成图中第二种情形。需要注意的是,修改后的page 3和page 10现在存于page 11和13,且原来的page 3和page 10中的数据并没有修改。
需要增加文件大小,需要remmap
前一个读写Transaction Commit后,我们再打开一个读写Transaction时,处于Pending状态的页将变成空闲页,可供分配并重写,所以在图中第二种磁盘布局中,page 2、3和10现在均可供分配使用。当向page 11和page 12对应的node中不断写入记录让其size超过页大小*填充率,等到Commit时,两个node将被分裂成四个node,且需要四个新的页来存,所以原来的page 11和page 12变成Pending页,meta.pgid之前的空闲页page 2和page 3先分配给page 11修改后的数据,page 10和新申请的page 14分配给page 12修改后的数据。在申请page 14后,meta.pgid将变成15。在Commit()中,重新分配freelist页时,先将原page 13变成Pending页,然后试着为其分配一页,然而现在meta.pgid之前并无空闲页可以用,而且内存映射文件范围刚好到page 14,所以这时需要remmap将文件映射区增加到page 15,并将meta.page变成16,并把新增的page 15分配给freelist。根据tx.Commit()代码(4)、(7)和(8)处的优化,为freelist分配页时如果没有空闲页,需要移动meta.pgid增加文件内容大小,且mmap映射的范围已经超出文件实际大小时,linux平台下就会增加文件大小。图中我们假设映射文件大小大于16M,所以此时会比实际需要的文件大小多增加16M,多增加的页全部是文件结尾处的空白页。在调用tx.write()写磁盘后,磁盘布局将变成图中第三种情形,其中page 11、12和13的内容没有变化。
不需要增加文件大小,需要remmap
等前一个读写Transaction结束后,新的读写Transaction中page 11、12和13均为空闲页。如果我们依次修改page 2、3和10,它们将变成为Pending页,且page 11、12和13被依次分配给它们对应的node作为其新的存储位置。为freelist重新分配页时,由于没有可用空闲页了,且映射范围已经达到文件内容结尾处或者meta.pgid指示的位置,为了分配新页,需要remmap将映射范围移至当前位置的下一页,即page 17处。同时,page 17处在文件实际大小范围处,故不需要增加文件大小了,这也是over allocate带来的好处,可以减少ftruncate系统调用的次数。Transaction Commit后,磁盘布局将变成图中第四种情形,page 2、3、4和原freelist所在的page 15为Pending页,其中内容没有被修改。
不需要增加文件大小,不需要remmap
当磁盘文件上有足够的空闲页时,不需要增加文件大小和remmap。在图中第四种磁盘布局的基础上,假如我们只修改page 12中某个Key的值,且最后node的size没有超限,那么Commit时node不会分裂成两个,空闲的page 2将分配给它对应的node作为新的存储位置,原来的page 12变成Pending页;随后freelist被重新分配到page 3,此时不需要增加文件映射范围,故不需要remmap,同时freelist也有空闲页重用,所以也不需要调整文件大小。从这里可以看出,最后为freelist重新分配页一方面是为了保证新的freelist页会被写入BoltDB文件,另一方面也用来测试是否有足够的空闲页,如果没有,则需要增加文件大小。
在修改BoltDB中记录时,会发生各种情形,但磁盘布局的变化均是上述四种情况的组合。特别地,B+Tree旋转时若有节点被删除,其对应的page将被直接标记为Pending页,而且不用分配新的页,这种情形可以看作是修改一页的特殊情况。到此,结合我们在《区块的持久化之BoltDB(四)》中分析的读写Transaction Commit时B+Tree的调整过程,我们就完全了解在写BoltDB时,内存中的node和最后磁盘上的page发生了哪些变化,以及最后所处的状态。
在分析完db.Update()读写BoltDB的完整过程后,我们再来看看《区块的持久化之BoltDB(一)》中的典型调用示例中剩下的db.View(),db.Close()较为简单,读者可以自行分析。
//boltdb/bolt/db.go
// View executes a function within the context of a managed read-only transaction.
// Any error that is returned from the function is returned from the View() method.
//
// Attempting to manually rollback within the function will cause a panic.
func (db *DB) View(fn func(*Tx) error) error {
t, err := db.Begin(false)
if err != nil {
return err
}
// Make sure the transaction rolls back in the event of a panic.
defer func() {
if t.db != nil {
t.rollback()
}
}()
// Mark as a managed tx so that the inner function cannot manually rollback.
t.managed = true
// If an error is returned from the function then pass it through.
err = fn(t)
t.managed = false
if err != nil {
_ = t.Rollback()
return err
}
if err := t.Rollback(); err != nil {
return err
}
return nil
}
可以看到,其过程与db.Update()相似,开始调用db.Begin(false)创建了一个只读的Transaction,其过程我们已经在《区块的持久化之BoltDB(二)》中介绍过,这里不再赘述。与db.Update()不同的是,db.View()最后不需要调用Commit(),而且是通过调用t.Rollback()来结束Transaction的。由于只读Transaction并不能修改BoltDB,t.Rollback()实际上是释放mmaplock读锁并从db.txs中移除当前transaction。
在只读Transaction中,主要的操作就是查找Bucket或者K/V记录,示例中是查找名为“widget”的Bucket中的Key为“foo”的记录。我们先来看看通过tx.Bucket()查找Bucket的实现:
//boltdb/bolt/tx.go
// Bucket retrieves a bucket by name.
// Returns nil if the bucket does not exist.
// The bucket instance is only valid for the lifetime of the transaction.
func (tx *Tx) Bucket(name []byte) *Bucket {
return tx.root.Bucket(name)
}
可以看出,仍然是通过Tx的根Bucket开始查找的。
//boltdb/bolt/bucket.go
// Bucket retrieves a nested bucket by name.
// Returns nil if the bucket does not exist.
// The bucket instance is only valid for the lifetime of the transaction.
func (b *Bucket) Bucket(name []byte) *Bucket {
if b.buckets != nil {
if child := b.buckets[string(name)]; child != nil {
return child
}
}
// Move cursor to key.
c := b.Cursor()
k, v, flags := c.seek(name)
// Return nil if the key doesn't exist or it is not a bucket.
if !bytes.Equal(name, k) || (flags&bucketLeafFlag) == 0 {
return nil
}
// Otherwise create a bucket and cache it.
var child = b.openBucket(v)
if b.buckets != nil {
b.buckets[string(name)] = child
}
return child
}
其过程主要为:
- 在父Bucket缓存的子Bucket中查找,若有则返回;
- 查找父Bucket的记录,看是否有目标名字的Bucket记录,如果没有再回返错误。其中的seek()过程我们在《区块的持久化之BoltDB(三)》中已经详细介绍过,这里不再赘述;
- 将查找到的Bucket记录的Value传入openBucket()得到子Bucket;
- 将子Bucket添加到父Bucket的缓存中;
我们再来看看openBucket():
//boltdb/bolt/bucket.go
// Helper method that re-interprets a sub-bucket value
// from a parent into a Bucket
func (b *Bucket) openBucket(value []byte) *Bucket {
var child = newBucket(b.tx)
......
// If this is a writable transaction then we need to copy the bucket entry.
// Read-only transactions can point directly at the mmap entry.
if b.tx.writable && !unaligned {
child.bucket = &bucket{}
*child.bucket = *(*bucket)(unsafe.Pointer(&value[0]))
} else {
child.bucket = (*bucket)(unsafe.Pointer(&value[0]))
}
// Save a reference to the inline page if the bucket is inline.
if child.root == 0 {
child.page = (*page)(unsafe.Pointer(&value[bucketHeaderSize]))
}
return &child
}
主要包括:
- 创建一个新的Bucket;
- 在读写Transaction中,将Value深度拷贝到新Bucket的头部;在只读Transaction,将新Bucket的头部指向Value即可;前面我们介绍过,普通Bucket记录的Value就是Bucket头部,内置Bucket记录的Value是Bucket头和内置page的序列化结果;
- 如果是一个内置Bucket,将新Bucket的page字段指向Value中内置page的起始位置;
可以看出,Bucket()方法查找子Bucket时进行了缓存,一方面可以加快后续的查找过程,另一方面只有缓存下来的子Bucket才在读写Transaction Commit时作再平衡和溢出处理。找到子Bucket后,就可以调用其Get()方法查找K/V记录,请注意,在只读Transaction中调用Bucket的CreateBucket()或者Put()方法将会返回错误。
//boltdb/bolt/bucket.go
// Get retrieves the value for a key in the bucket.
// Returns a nil value if the key does not exist or if the key is a nested bucket.
// The returned value is only valid for the life of the transaction.
func (b *Bucket) Get(key []byte) []byte {
k, v, flags := b.Cursor().seek(key)
// Return nil if this is a bucket.
if (flags & bucketLeafFlag) != 0 {
return nil
}
// If our target node isn't the same key as what's passed in then return nil.
if !bytes.Equal(key, k) {
return nil
}
return v
}
其中核心的调用还是seek()方法,如果找到的是Bucket将返回nil,因为子Bucket只能通过Bucket()方法查找到。至此,只读Transactoin中查找Bucket和K/V对的全过程我们就分析完了。在分析完读写Transaction后再来分析只读Transaction,大家是不是感觉轻松了许多呢?
MVCC
读和写BoltDB的全过程我们都已经了解了,然而,它的MVCC机制是如何的呢?我们介绍过mmaplock读写锁,它在只读Transaction和读写Transaction间作了一定同步,那它是否就破坏了MVCC呢?我们也提到过,读BoltDB文件通过mmap内存映射,而写BoltDB文件是通过fwrite和fdatasync系统调用写文件系统,读写过程并没有锁作同步,再加上meta中的txid是不是就构成了MVCC呢?我们将结合下图为大家分析其MVCC原理:
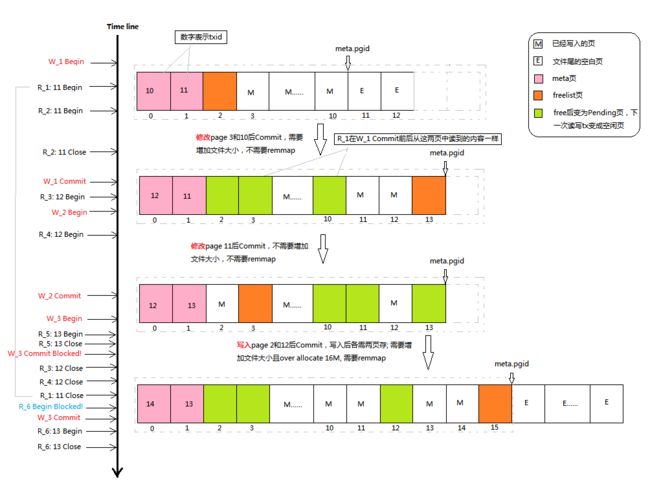
上图中,右边是写BoltDB后磁盘页的变化,左边是按时间顺序对BoltDB进行读或者写的操作集合。其中“W”表示读写Tx,后面的数字表示序号,如“W_1”表示第1个读写Tx;“R”表示只读Tx,下划线后面的数字是序号,冒号后面数字是txid,如“R_1: 11”表示第一个只读Tx,且读到的txid是11。我们前面介绍过,meta中的txid可以当作版本号,所以“R_1: 11”也可以表示读到的版本为11。我们知道,MVCC的基本思路是: 写时增加版本号,读时可能读到不同的版本,读写可以并行。接下来,我们来逐步分析BoltDB如何做多版本控制。
假设BoltDB文件打开后,其磁盘页布局如上图中第一种情形,且mmap初始映射的范围超过文件实际大小。这时W_1开始写数据库,请注意,在W_1 Commit之前,W_1只是修改内存中的node。在W_1修改page 3和page 10时,R_1和R_2开始读数据库,它们读到的版本号均是11,且均占用了mmaplock的读锁。由于W_1只是修改node,并没有修改磁盘页,也没有修改映射区,所以R_1和R_2读到的仍然是版本11的状态。
随后,R_2读结束,W_1准备Commit修改并写磁盘。由于W_1 Commit时不需要remmap,因而不需要抢占mmaplock的写锁,也不需要等mmaplock读锁释放,所以Commit成功,同时将第0页中的meta更新,其中的txid增加为12。请注意,此时R_1并没有结束,它继续读数据库,并可以正常访问page 2和page 3,page 2和page 3中的数据并没有被修改,所以它仍然读到的是版本11的状态,由于版本11中的meta.pgid仍然是11,它不可能读到版本12中更新的page 11和page 12。
然后,R_3、W_2、R_4依次开始,它们读到的均是版本为12的状态。W_2修改数据库后Commit,由于仍然不需要remmap,所以不需要等mmaplock读锁释放,可以正常Commit,同时将数据库最新版本更新为13。随后,W_3和R_5依次开始,它们读到的版本为13。请注意,此时,R_1读到的版本是11,R_3、R_4读到的版本是12,R_5和W_3读到的版本是13,尽管当前实际版本为13,R_3和R_4仍然可以正常读取版本13修改之前的page 11,但由于page 3已经被W_2 Commit时重写了,所以R_1将读到的是版本11的修改版本,将是一个中间状态,然而这并不违背MVCC的思想,即可以容忍读到被修改过的数据。在W_2 Commit时,page 2也被重写了,但在版本11中,page 2存的是freelist,它并未在只读Tx访问到,所以并不影响。
接着,R_5关闭,W_3更新完数据库后试图Commit,然而由于它需要remmap,所以阻塞在mmaplock的写锁处,等待所有读锁释放,即等待所有未关闭只读Transaction结束。一段时间后,R_3、R_4和R_1依次关闭,mmaplock读锁全部释放,W_3 Commit继续。在W_3 remmap完成之前,R_6试图开始读数据库,然而mmaplock写锁已经被占用,它只能阻塞在争用mmaplock的读锁处。所以,在使用BoltDB时,不要在同一个线程或者goroutine中同时使用只读和读写Tx。等W_3 remmap完成后,R_6可以开始读DB。请注意,R_6读到的版本号是13,而不是14!这是因为W_3 Commit()时,remmap后先通过tx.write()将脏页写入磁盘,然后调用tx.writeMeta()更新meta页,由于读写DB并没有锁同步,在W_3向磁盘写脏页时,R_6就已经开始读meta页了,此时两个meta页仍是版本13中的状态,帮它读到的版本号是13,而不是14。根据我们上述的分析,尽管R_6读到的版本是13,由于page 3和page 12并没有被重写,所以它仍然能正常读数据库,只是读到的不是最新版本布局。这里,我们也可以看出为什么BoltDB采用双meta,就是了为避免读写meta页时需要锁同步。如果只有一个meta页,读写meta时必须同步,不然可能会出现读到乱码的情况。
通过上述各读写Tx的推演,我们知道,BoltDB在读写磁盘文件时没有锁同步,并通过双Meta及其中的txid作版本号来实现MVCC机制。同时也可以看出,为了提高BoltDB读写并发,一方面要尽量减少remmap的概率; 另一方面要避免耗时的读Tx。减少remmap的概率可以通过在初次mmap时指定一个较大的options.InitialMmapSize值来实现,然后这只能减少打开数据库文件后开始几次Commit中的remmap概率,一段时间后,映射范围仍然是按需要增加的,如我们图中所示。如果将按需remmap改为over remmap也许是一个优化空间。然而,增加mmap映射范围以减少remmap概率也许并不是我们想要的,如我们图中所示的R_1,由于W_1和W_2 Commit时均不需要remmap,当前数据库版本已经是13,它读到的仍然是11,且它可能读到中间状态。所以我们需要同时考虑避免耗时Tx和增加mmap范围来提高其读写并发。另外,从我们的代码分析中也可以看出,在读写Tx中进行更新操作后Commit时,会触发rebalace和spill过程,如果需要频繁地随机写数据库,这将是一个耗时的过程,所以采用B+Tree的BoltDB并不适合频繁写数据库的情景。
到此,BoltDB的源码阅读和分析就结束了,其他相关话题或者资源,读者可以从其Github上获取。
==大家可以关注我的微信公众号,后续文章将在公众号中同步更新:==
