- 概述
最小二乘法是一种数学优化技术,它通过最小化误差来寻找数据的最佳匹配函数,在曲线拟合中有广泛应用。在一维空间中,若已知个点,现在我们使用最小二乘法对这个点进行曲线拟合。目标就是找到常数,使得数据与直线的误差平方和函数最小。则此时的常数就是这个数据点的最佳匹配函数,同时也得到了这个点的回归方程。
- 理论推导
显然,无法直接由数据点得出常数的值。直接考虑误差平方和函数的形式:对存在, (也就是将误差平方和视为以为自变量的二元函数)。经过这样的转换,现在只需求出二元函数,这类二元函数的极值问题显然是比较容易求解的,令则有:
整理方程组得:
求此方程的解,即得的稳定点:
现在需要进行一步证明该稳定点是的极小值点,此时只需计算在点的黑塞(Hesee)矩阵。
在多元函数的极值理论中将称为二元函数在点的黑塞矩阵。注意到当时,由函数在点的二阶泰勒公式有:
可以证明,当为正定矩阵时,在点处取得极小值;
同理可证,当为负定矩阵时,在点处取得极大值;
详细证明过程请参考数学分析第四版下第十七章第四节泰勒公式与极值146页关于正定矩阵、负定矩阵的定义,在此不再赘述,有兴趣的请自行百度。
在实际运用中,一般使用如下方式进行判断:1).当时,在点处取得极小值;
2).当时,在点处取得极小值;
3).当时,在点处不能取得极值;
4).当时,不能判断在点处是否能取得极值;
因为:
由数学归纳法可以很容易证明当不全相等时,以下等式恒成立:
则有判定1)可知,误差平方和函数在处取得极小值,且该极小值为该函数的最小值。故的回归模型为:,其中
- 最小二乘法的推广
对于多元线性回归模型
其中相互独立且服从分布。
其残差平方和
对参数求偏导得:
转化为矩阵形式为:
得到:
- 实际应用
在Scikit-learn库中,使用LinearRegression实现线性模型的最小二乘法求解。
class sklearn.linear_model.LinearRegression(fit_intercept=True, normalize=False, copy_X=True, n_jobs=1)¶
- Parameters
fit_intercept:是否计算此模型的截距,默认为True,计算截距。
normalize:在需要计算截距时,如果值为True,则变量x在进行回归之前先进行归一化(),如果需要进行标准化则normalize=False。若不计算截距,则忽略此参数。
copy_X:默认为True,将复制X;否则,X可能在计算中被覆盖。
n_jobs:指定用于计算的cpu,如果为-1,则使用所有cpu进行计算。只为n_target>1和运算量足够大的问题进行加速。
- Attributes
coef_:返回模型的估计系数。
intercept_:线性模型的独立项,一维情形下的截距。
- Methods
fit(X,y):使用数据训练模型�
get_params([deep=True]):返回函数LinearRegression()内部的参数值
predict(X):使用模型做预测
score(X,y):返回模型的拟合优度判定系数
为回归平方和与总离差平方和的比值,介于0-1之间,越接近1模型的拟合效果越显著。
set_params(**params):设置函数LinearRegression()内部的参数。
- 实例
使用boston房价数据集进行线性回归的演示:
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import scale
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
# 正确显示中文字符和负号
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
data = load_boston()
# 标准化数据集
X = scale(data.data)
y = data.target
# 拆分数据集为测试集和训练集
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.5)
lmodel = LinearRegression(fit_intercept = True,normalize = False,copy_X=True,n_jobs=1)
lmodel.fit(X_train,y_train)
# 回归模型的系数
lmodel.coef_
array([-0.35105084, 0.7982819 , 0.24039003, 0.81774379, -2.12147393,
2.4506533 , 0.32602751, -3.01123388, 2.99123594, -2.33217099,
-1.9661762 , 0.65463517, -4.79537511])
# 回归模型的截距
lmodel.intercept_
22.390664677581363
# 输出函数内部的全部参数
lmodel.get_params()
{'copy_X': True, 'fit_intercept': True, 'n_jobs': 1, 'normalize': False}
# 设置函数参数n_jobs,使用全部cpu
lmodel.set_params(n_jobs = -1)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=-1, normalize=False)
# 输出模型的拟合优度系数
lmodel.score(X_train,y_train)
0.7584080147755256
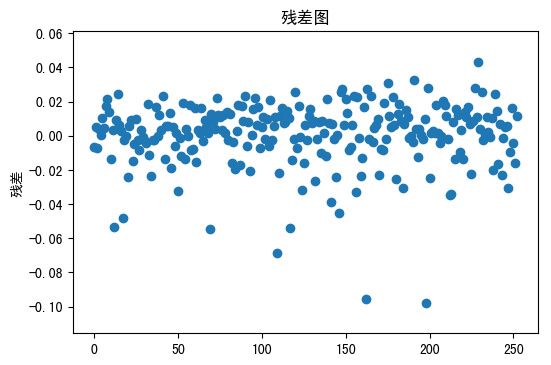
拟合优度约为0.76,拟合效果良好,下面通过绘制残差图,来观察残差的分布情况。
error = pow(lmodel.predict(X_test)-y_test,1)/len(X_test)
plt.figure(1,dpi = 100)
plt.scatter(np.arange(len(error)),error)
plt.ylabel('残差')
plt.title('残差图')
error.mean()
0.0007116874646772689
error.std()
0.01865271004134575
通过残差图还有残差的均值可以发现,残差在0周围波动且不包含任何可预测的信息,拟合效果显著。