前言
记录二叉树算法的学习过程,方便以后回顾。
二叉树的概念可查看 leetcode 二叉树
遍历动态图,请查看 leetcode 树的遍历 - 介绍
以如下二叉树为例
const TREE = {
value: 'A',
left: {
value:'B',
left: {
value:'C',
left: null,
right: null,
},
right: {
value:'D',
left: null,
right: null,
},
},
right: {
value:'E',
right: {
value:'F',
left: null,
right: {
value:'G',
left: null,
right: null
}
}
}
};

一、深度优先遍历(DFS)
1.1 前序遍历
首先访问根节点,然后遍历左子树,最后遍历右子树。A,B,C,D,E,F,G
1.1.1递归法
按照根左右的顺序,依次处理单个节点。
/**
* @description: 前序遍历二叉树
* @param {Object} root
* @param {Function} fn
*/
function preorderTraversal (root, fn) {
if (!root) return;
const { value, left, right } = root;
fn(value);
preorderTraversal (left, fn);
preorderTraversal (right, fn);
}
1.1.2迭代法
迭代的本质就是遍历,所以要想办法生成一个按照根左右排序的数组,这里需要用到栈的后进先出的特性。
因为前序遍历要先处理左子树,再处理右子树,所以可以先把右子树添加到栈中,再把左子树添加到栈中,而栈的特性是后进先出,实现了先处理的是左子树。
/**
* @description: 前序遍历二叉树
* @param {Object} root
* @param {Function} fn
*/
function preorderTraversal (root, fn) {
if (!root) return;
const stack = [];
stack.push(root);
while (stack.length) {
const { value, left, right } = stack.shift();
fn(value);
right && stack.unshift(right);
left && stack.unshift(left);
}
}
1.1.1 前序遍历测试用例:
function testPreorder() {
const res = [];
preorderTraversal (TREE, function (data){
res.push(data);
});
console.log(res.join(','));
}
1.2中序遍历
首先遍历左子树,然后访问根节点,最后遍历右子树。C,B,D,A,E,F,G
1.2.1 递归法
/**
* @description: 中序遍历二叉树
* @param {Object} root
* @param {Function} fn
*/
function inorderTraversal(root, fn) {
if (!root) return;
const { value, left, right } = root;
inorderTraversal(left, fn);
fn(value);
inorderTraversal(right, fn);
}
1.2.2 迭代法
第一步:中序遍历的顺序是左根右, 第一个获取的节点应该是最左边的节点,所以需要遍历获取左子树
第二步:遍历结束后,出栈处理左子树(第一次出栈)
为了方便分析,请看以下几种情况
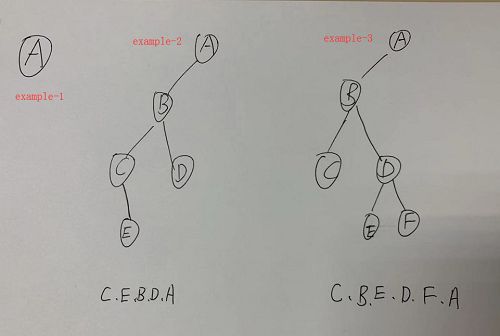
情况1:只有根节点
此时出栈的节点,就是根节点情况2:左子树是
C,而且C有右子树E
此时出栈的节点是C,而C既是左子树,又是根节点,所以处理完C后,不能的直接去处理B,而应该先处理E-
情况3:左子树是
C,D有左子树E,右子树F
此时出栈的节点是C,而C只是左子树,所以处理完C后,会向上继续处理B总结:考虑到树的各种情况,第一个出栈的节点可能是
左子树也可能是根节点,所以这里统一当做根节点,处理完当前节点后,下个处理的应该是当前节点的右子树()
第三步:处理右节点
- 如果当前节点的右子树不存在,就会继续出栈,出栈的元素为,当前节点的根节点
- 如果当前节点的右子树存在,这里就有点像递归了,处理右节点的逻辑和第一次处理根节点的过程一样
/**
* @description: 中序遍历二叉树
* @param {Object} root
* @param {Function} fn
*/
function inorderTraversal(root, fn) {
if (!root) return;
const stack = [];
let node = root;
while(node || stack.length){
// 遍历添加左子树
while (node) { // 如果 node存在,至少执行一次入栈操作
stack.unshift(node);
node = node.left;
}
// 出栈
node = stack.shift();
fn(node.value);
// 转向
node = node.right;
}
}
1.2.3 中序遍历测试用例:
function testInorder() {
const res = [];
inorderTraversal(TREE, function (data){
res.push(data);
});
console.log(res.join(','));
}
1.3 后序遍历
首先遍历左子树,然后遍历右子树,最后访问树的根节点。 C,D,B,G,F,E,A
1.3.1递归法
/**
* @description: 后序遍历二叉树
* @param {Object} root
* @param {Function} fn
*/
function postorderTraversal(root, fn) {
if (!root) return;
const { value, left, right } = root;
postorderTraversal(left, fn);
postorderTraversal(right, fn);
fn(value);
}
1.3.2迭代法
第一步:后序遍历的顺序是左右根,所以需要遍历获取左子树
第二步:遍历结束后,出栈处理左子树(第一次出栈)

- 情况一:只有根节点
此时出栈的节点,就是根节点 - 情况2:左子树是
C,而且C有右子树E
此时出栈的节点是C,而C既是左子树,又是根节点,所以不能直接去处理C,根据左右根的顺序,应该先处理E,之后再处理C(这里和中序遍历是不一样的) - 情况3:左子树是
C,D有左子树E,右子树F
此时出栈的节点是C,而C只是左子树,所以处理完C后,应该先处理D, 之后再继续处理B
总结:后序遍历在中序遍历的基础上,还需要考虑处理右子树和根节点的顺序,要先判断右子树是否已经处理。
/**
* @description: 后序遍历二叉树
* @param {Object} root
* @param {Function} fn
*/
function postorderTraversal (root, fn){
if (!root) return;
const stack = [];
let node = root;
let last; // 上次处理的节点
while (node || stack.length) {
// 遍历添加左子树
while (node) { // 如果 node存在,至少执行一次入栈操作
stack.unshift(node);
node = node.left;
}
// 获取栈顶元素, 不直接出栈的原因是,如果右子树没被处理,根节点不应该出栈
node = stack[0];
if (!node.right || last === node.right) { // 如果右子树不存在,或者右子树已经处理过,就可以处理根节点
stack.shift(); // 出栈
const { value } = node;
fn(value);
last = node;
node = null;
} else { // 如果右子树没有处理过,先处理右子树
node = node.right;
}
}
}
1.3.3 后序遍历测试用例:
function testPostorder() {
const res = [];
postorderTraversal(TREE, function (data){
res.push(data);
});
console.log(res.join(','));
}
二、广度优先遍历(BFS)
广度优先遍历,又称为层级遍历,即从根节点开始,按照宽度,从上到下一层一层的处理节点。A,B,E,C,D,F,G
这里要用到队列的先进先出特性。使用数组模拟队列操作,通过 unshift() 从数组头部添加节点,通过 pop() 从尾部取出节点。
第一步:先把根节点A放进队列
此时 queue = [A]
第二步:处理根节点A,然后把根节点A的直接左子树B和右子树E放进队列中
此时 queue = [E, B]
第三步:因为先放进 B, 所以处理 B,然后把B的直接左子树C和右子树D放进队列中
此时 queue = [D, C, E]
依次进行...
/**
* @description: 广度优先遍历二叉树
* @param {Object} root
* @param {Function} fn
*/
function bfsTraversal(root, fn) {
if(!root) return;
let queue = [root];
while (queue.length) {
const node = queue.pop();
const { value, left, right } = node;
fn(value);
left && queue.unshift(left);
right && queue.unshift(right);
}
}
广度优先遍历测试用例:
function testBFS() {
const res = [];
bfsTraversal(TREE, function (data){
res.push(data);
});
console.log(res.join(','));
}
三、参考
慕课网:Javascript实现二叉树算法
奇舞周刊:算法 ——— 从栈 & 队列 到 BFS & DFS
JavaScript 二叉树遍历专题:算法描述与实现
二叉树的前序,中序,后序遍历方法总结