在Ben Schmaus之前的一篇文章中,我们分享了断路器实现背后的原则。在那篇文章中,Ben讨论了Netflix API如何与我们面向服务体系结构中数十个系统交互,这使得API天生更容易受到堆栈中任何系统故障或延迟的影响。本文的其余部分将更深入地介绍我们的API和其他系统如何隔离故障、降低负载并保持对故障的弹性。
容错是一种要求,而不是特性
Netflix API每天接收超过10亿的请求,这反过来又向几十个底层子系统转出数十亿次请求(平均比例为1:6,峰值为每秒10万次依赖请求)。

这一切都发生在跨越数千个EC2实例的云中。
即使每个依赖项本身都具有极棒的可用性和正常运行时间,这么多变量也会导致间歇性故障。
如果不采取措施确保容错,每个依赖项的正常运行时间为99.99%,则会导致每个月2小时以上的停机(99.99%^30 = 99.7% 正常运行时间= 一个月2+小时)。
当一个API依赖项在高容量,请求延迟增加(导致请求线程阻塞)的情况下失败,它会很快(秒或亚秒以下)使所有可用的Tomcat(或Jetty等其他容器)请求线程饱和,并导致整个API崩溃。

因此,高容量、高可用性的应用程序需要在其体系结构中构建容错功能,而不是指望基础设施为它们解决这个问题。
Netflix DependencyCommand实现
Netflix的面向服务架构允许每个团队根据自己的需要自由选择最佳传输协议和格式(XML、JSON、Thrift、协议缓冲区等),因此这些方法可能会因服务的不同而有所不同。
在大多数情况下,提供服务的团队还分发一个Java客户端库。
因此,诸如API之类的应用程序实际上将底层依赖关系视为第三方客户端库,它是“黑盒”实现的。进而影响容错的实现方式。
根据以上架构上的考虑,我们选择了组合多种容错方法的解决方案:
网络超时和重试
根据每个依赖分离单独的线程池
信号量(通过tryAcquire,而不是阻塞调用)
断路器
这些容错方法各有优缺点,但是当它们结合在一起时,在用户请求和底层依赖项之间提供了一个全面的保护屏障。

Netflix DependencyCommand实现将网络绑定的依赖调用封装起来,它倾向于在一个单独的线程中执行,并且定义了针对任何失败或拒绝(下面的步骤3、4、5a、6b)执行的回退逻辑,而不管触发它的是哪种类型的容错(网络或线程超时、线程池或信号量拒绝、断路器)。
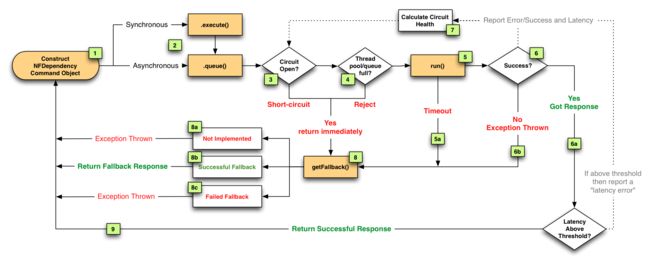
我们认为将依赖调用隔离到单独的线程中所带来的好处要超过缺点(在大多数情况下)。此外,由于API正逐步向增加并发性迈进,因此通过使用相同的并发解决方案实现容错和性能提高是双赢的。换句话说,单独线程的使用在很多用例中起到了积极的作用,它提升了执行调用的并发性,提升了Netflix的用户体验。
因此,现在大多数依赖调用路由到一个单独的线程池,如下列图所示:

如果一个依赖项延迟时(子系统最坏的失败情况),它可能会使自己线程池中的所有线程饱和,但是Tomcat请求线程将超时或立即拒绝,而不是阻塞。

除了隔离的好处和依赖调用的并发执行之外,我们还利用了单独的线程来支持请求合并(自动批处理),以提高整体效率和减少用户请求延迟。
信号量代替线程,用于不进行网络调用时的依赖项执行(例如那些只执行内存缓存查找的线程),因为独立线程的开销对于这些类型的操作来说太高了。
我们还使用信号量来防止不可信的回退。每个DependencyCommand都能够定义一个回退函数(后面会详细讨论),该函数在用户调用线程上执行,不应该执行网络调用。它不相信所有的实现都能正确遵守这个协议,而是需要信号量的保护,因此,如果实现涉及了一些隐含的网络调用,那么回退本身并不能影响整个应用程序,因为它能够阻塞的线程数量有限。
尽管使用了带有超时的单独线程,我们仍然在网络层级设置超时和重试(通过与客户端库所有者、监控、审计等的交互)。
DependencyCommand线程层级的超时是第一道防线,不管底层依赖客户端如何配置或执行,但是网络超时仍然很重要,否则高度隐蔽的网络调用可能会无限期地占满依赖线程池。
当DependencyCommand超过一定的错误阈值(比如10秒内50%的错误率)时,就会触发线路跳闸,然后拒绝所有请求,直到健康检查成功为止。
这主要用于在底层系统出现问题时释放压力(即减轻负载),并在知道可能会失败时通过快速失败(或返回fallback)来减少用户请求延迟,而不是让每个用户请求等待超时发生。
当发生故障时,我们如何响应用户请求?
上述每个选项,超时、线程池或信号量拒绝或短路,都将导致不能为我们的客户请求检索最友好的响应内容。
立即失败(“快速失败”)会抛出异常,使应用程序降低负载,直到依赖项恢复正常。这比请求“堆积”更可取,因为它使Tomcat请求线程处理到健康依赖项的请求,并在失败的依赖项恢复后快速恢复。
然而,通常在“回退模式”中,有几个更合适的方式可以提供响应,以减少故障对用户的影响。无论什么原因导致失败,以及它是如何被拦截的(超时、拒绝、短路等),请求总是在返回给用户之前通过回退逻辑(上面流程图中的第8步),让DependencyCommand做一些“快速失败“之外的事情。
我们根据对用户体验的影响,使用了这些回退方法:
缓存:如果实时依赖项不可用,则从本地或远程缓存检索数据,即使数据最终已过期
最终一致性:队列写入(如在SQS中),在依赖项再次可用时继续
存根数据:当无法检索个性化选项时,恢复到默认值
空响应(“Fail Silent”):返回null或空列表,ui可以忽略他们
这项工作的目的是为我们的用户保持最大的正常运行时间,同时保持最大的功能数量,让他们尽可能享受最丰富的Netflix体验。因此,我们的目标是让回退传递的响应尽可能接近实际依赖项所传递的响应。
示例用例
下面是关于线程、网络超时和重试如何结合的例子:
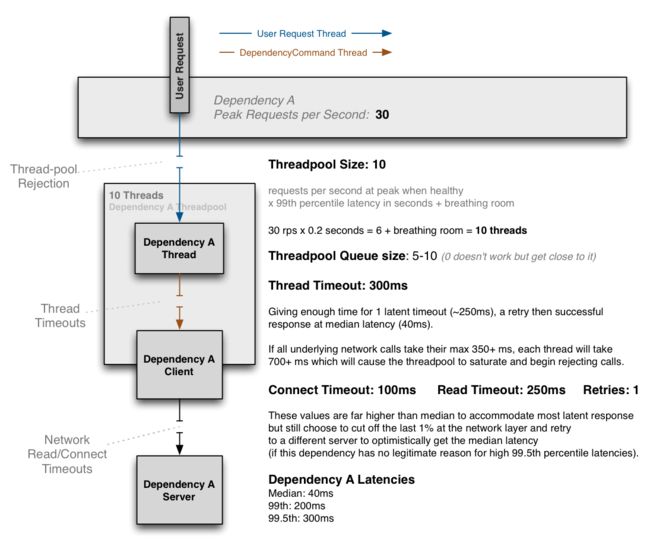
上面的图显示了一个示例配置,其中依赖项一般不会达到99.5%处(99.5%用户都会在那段时间内返回),因此缩短网络超时,并立即重试,大多数情况下,重试请求会在平均延迟时间内完成,这样这一切都会在300ms的线程超时时间内完成。
这个依赖关系有时也会达到99.5%处(即懒加载缓存未命中),网络超时将设置高于此值,例如0或1次重试需要325ms,线程超时需要设置更高(350ms+)。
threadpool的大小是10,可以处理99%处的突发请求,但是当一切正常时,这个threadpool通常只有1或2个线程处于活动状态,用来处理大多数平均耗时为40ms的请求调用。
当正确配置时,DependencyCommand层的超时很罕见,但是万一网络延迟以外的因素影响了时间,或者在最坏的情况下connect+read+retry+connect+read的组合仍然超过了配置的全部超时,就需要保护。
配置的激进性和方向上的权衡因为依赖项的不同而不同。
当性能特征发生变化时,或者在发现问题时,可以根据需要实时更改配置,而不会因为出现问题或错误配置而导致整个应用程序宕机。
结论
本文讨论的方法对我们在不影响(或限制影响)用户体验的情况下对系统、基础设施和应用程序级故障的容忍度和恢复能力产生了显著影响。
尽管这个新的DependencyCommand弹性系统在过去的8个月里取得了成功,但是我们在提高容错策略和性能方面还有很多工作要做,特别是在我们功能、设备、客户和国际市场份额不断增加的时候。
java达人
ID:drjava
(长按或扫码识别)
