无聊的言论
自己其实听过挺多课的,之前也会乱七八糟报一堆课,一直坚信着一个原则,没有输出再多的输入也没什么卵用,其实也真的是这样,输入再多都不如实际的输出一波,希望大家可以认真的把老师的每个例子都能实践出来,我也会给大家说怎么实践以及如何看到自己的结果,大纲就是21天入门的大纲,跟着猴哥走起来!
emmm 其实写了好多又都删了,不知道觉得将老师的课本重复一遍又没什么太大的用途,我们就从算法开始讲起,原理部分就当大家都理解啦,就从第一个算法,梯度下降法,我会把老师讲的东西掰开揉碎写清楚,也许会有些琐碎,选择自己需要的看,这篇文章也是我看了好多文章论文写出来的,希望能有帮助!
梯度下降法快速入门
原理方面请看老师的讲解,这里我们主要来学习实际原理以及实现
前言
梯度下降法(Gradient Descent)是机器学习中最常用的优化方法之一,常用来求解目标函数的极值。
其基本原理非常简单:沿着目标函数梯度下降的方向搜索极小值(也可以沿着梯度上升的方向搜索极大值)。
但是如何调整搜索的步长(也叫学习率,Learning Rate)、如何加快收敛速度以及如何防止搜索时发生震荡却是一门值得深究的学问。接下来本文将分析第一个问题:学习率的大小对搜索过程的影响


来梳理梯度下降法的原理
梯度下降的相关概念
在详细了解梯度下降的算法之前,我们先看看相关的一些概念。
1. 步长(Learning rate):步长决定了在梯度下降迭代的过程中,每一步沿梯度负方向前进的长度。用上面下山的例子,步长就是在当前这一步所在位置沿着最陡峭最易下山的位置走的那一步的长度。
2.特征(feature):指的是样本中输入部分,比如2个单特征的样本(x(0),y(0)),(x(1),y(1)),则第一个样本特征为x(0),第一个样本输出为y(0)。
3. 假设函数(hypothesis function):在监督学习中,为了拟合输入样本,而使用的假设函数,记为hθ(x)。比如对于单个特征的m个样本(x(i),y(i))(i=1,2,...m),可以采用拟合函数如下: hθ(x)=θ0+θ1x。
4. 损失函数(loss function):为了评估模型拟合的好坏,通常用损失函数来度量拟合的程度。损失函数极小化,意味着拟合程度最好,对应的模型参数即为最优参数。在线性回归中,损失函数通常为样本输出和假设函数的差取平方。比如对于m个样本(xi,yi)(i=1,2,...m),采用线性回归,损失函数为:
J(θ0,θ1)=∑i=1m(hθ(xi)−yi)2
其中xi表示第i个样本特征,yi表示第i个样本对应的输出,hθ(xi)为假设函数。
解决实际问题
是为了解决最优化问题,而最优化问题其实就是我们大学中,来求极大值以及极小值的问题
初中时我们就学会了求解二次函数的极值(抛物线的顶点),高中时学习了幂函数,指数函数,对数函数,三角函数,反三角函数等各种类型的函数,求函数极值的题更是频频出现。这些方法都采用了各种各样的技巧,没有一个统一的方案。
大学的时候我们使用微积分,而这个就是一个通用的方案:
找到函数的导数等于0的点,因为在极值(请注意极值不一定是全局极值),导数必然为0.
机器学习中,我们一般将最优化问题统一表述为求解函数的极小值问题:
其中x称为优化变量,f称为目标函数。极大值问题可以转换成极小值问题来求解,只需要将目标函数加上负号即可:

有些时候会对优化变量x有约束,包括等式约束和不等式约束,它们定义了优化变量的可行域,即满足约束条件的点构成的集合。在这里我们先不考虑带约束条件的问题。
一个优化问题的全局极小值x是指对于可行域里所有的x,有:

即全局极小值点处的函数值不大于任意一点处的函数值。局部极小值x
定义为存在一个δ邻域,对于在邻域内:
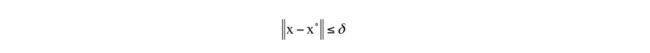
并且在可行域内的所有x,有:
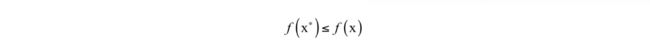
即局部极小值点处的函数值比一个局部返回内所有点的函数值都小。在这里,我们的目标是找到全局极小值。不幸的是,有些函数可能有多个局部极小值点,因此即使找到了导数等于0的所有点,还需要比较这些点处的函数值。
导数与梯度
由于实际应用中一般都是多元函数,因此我们跳过一元函数,直接介绍多元函数的情况。梯度是导数对多元函数的推广,它是多元函数对各个自变量偏导数形成的向量。多元函数的梯度定义为:

其中∇ 称为梯度算子,它作用于一个多元函数,得到一个向量。下面是计算函数梯度的一个例子:
可导函数在某一点处取得极值的必要条件是梯度为0,梯度为0的点称为函数的驻点,这是疑似极值点。需要注意的是,梯度为0只是函数取极值的必要条件而不是充分条件,即梯度为0的点可能不是极值点。
编写一个梯度下降的例子
首先先假设现在我们需要求解目标函数func(x) = x * x的极小值,由于func是一个凸函数,因此它唯一的极小值同时也是它的最小值,其一阶导函数 为dfunc(x) = 2 * x。
import numpy as np
import matplotlib.pyplot as plt
# 目标函数:y=x^2
def func(x): return np.square(x)
# 目标函数一阶导数:dy/dx=2*x
def dfunc(x): return 2 * x
接下来编写梯度下降法函数:
Gradient Descentdef GD(x_start, df, epochs, lr):
""" 梯度下降法。给定起始点与目标函数的一阶导函数,求在epochs次迭代中x 的更新值 :param x_start: x的起始点 :param df: 目标函数的一阶导函数 :param epochs: 迭代周期 :param lr: 学习率 :return: x在每次迭代后的位置(包括起始点),长度为epochs+1 """
xs = np.zeros(epochs+1)
x = x_start
xs[0] = x
for i in range(epochs):
dx = df(x)
# v表示x要改变的幅度
v = - dx * lr
x += v
xs[i+1] = x
return xs
需要注意的是参数df是一个函数指针,即需要传进我们的目标函数一阶导函数。
测试代码如下,假设起始搜索点为-5,迭代周期为5,学习率为0.3:
def demo0_GD():
"""演示如何使用梯度下降法GD()"""
line_x = np.linspace(-5, 5, 100)
line_y = func(line_x)
x_start = -5
epochs = 5
lr = 0.3
x = GD(x_start, dfunc, epochs, lr=lr)
color = 'r'
plt.plot(line_x, line_y, c='b')
plt.plot(x, func(x), c=color, label='lr={}'.format(lr))
plt.scatter(x, func(x), c=color, )
plt.legend()
plt.show()

学习率对梯度下降法的影响
在上节代码的基础上编写新的测试代码demo1_GD_lr,设置学习率分别为0.1、0.3与0.9:
def demo1_GD_lr():
# 函数图像
line_x = np.linspace(-5, 5, 100)
line_y = func(line_x)
plt.figure('Gradient Desent: Learning Rate')
x_start = -5
epochs = 5
lr = [0.1, 0.3, 0.9]
color = ['r', 'g', 'y']
size = np.ones(epochs+1) * 10
size[-1] = 70
for i in range(len(lr)):
x = GD(x_start, dfunc, epochs, lr=lr[i])
plt.subplot(1, 3, i+1)
plt.plot(line_x, line_y, c='b')
plt.plot(x, func(x), c=color[i], label='lr={}'.format(lr[i]))
plt.scatter(x, func(x), c=color[i])
plt.legend()
plt.show()
从下图输出结果可以看出两点,在迭代周期不变的情况下:
- 学习率较小时,收敛到正确结果的速度较慢。
-
学习率较大时,容易在搜索过程中发生震荡。
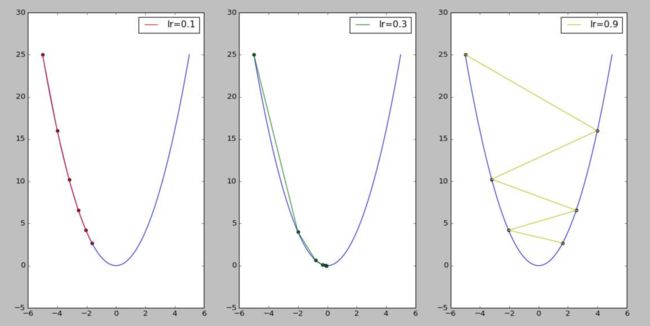 image.png
image.png