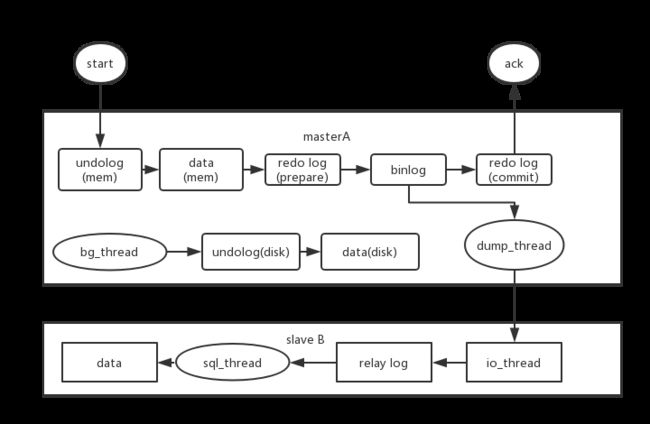
同步的步骤如下
1.在备库B上通过change master命令,设置主库A的ip,端口,用户名,密码,以及要从哪个位置开始请求binlog,这个位置包含文件名和偏移量
2.在备库B上执行start slave命令,这时候备库会启动两个线程,就是图中的io_thread和sql_thread.其中io_thread负责与主库建立连接
3.主库a校验完用户名,密码之后,开始按照备库B传过来的位置,从本地读取binlog,发送给b
4.备库B拿到binlog后,写到本地文件,称为中继日志(relay log)
5.sql_thread读取中继日志,解析出日志里面的命令,并执行
备注:主要采用row格式的日志而不是statement,因为有时候主库与从库或者容灾恢复的时候数据库版本不一致导致的对sql的支持不一定进而导致复制出问题,当然这只是打个比方
主从复制的一些问题以及解决方案
循环复制
假如是双主互备的架构(即互为彼此的从库),就会出现循环复制,当然解决方案也很简单,复制的时候带上一个server id
两个库的server id必须不同,一个库接到binlog并在重放的过程中,生成与原binlog的server id相同的binlog,每个库在收到从自己的主库发过来的日志后,先判断server id,如果跟自己的相同,则表示这个日志是自己生成的,就直接丢弃这个日志
主备延迟
可以通过show slave status查看seconds_behind_master.表示当前备库延迟了多少秒
主备延迟的第一种场景
备库所在的机器性能要比主库所在的机器性能差,导致从库的压力过大
解决方案:可以多接几个从库,分担压力,也可以先将binlog输出到外部系统,比如hadoop这类系统,让外部系统提供统计类查询的能力
第二种场景
就是大事务,因为主库上只有等待事务执行完了才会写入binlog,再传给备库,所以如果一个主库上的语句执行10分钟,那么这个事务很有可能就会导致从库延迟10分钟
当然对大表的操作也要慎重,因为很容易产生大事务
另外一种解决方案就是
开启并行复制
Mysql5.7提供了slave-parallel-type来控制并行复制的策略(是按表还是按行?需要考虑是否保证了事务不被破坏)
1.配置为DATABASE,按库来分发事务
2.配置为LOGICAL_CLOCK,表示的就是类似于组提交的策略
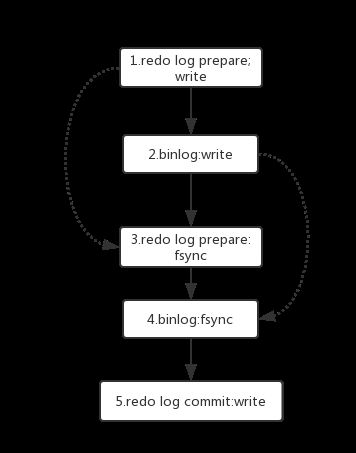
1.同时处于prepare状态的事务,在备库执行时是可以并行的
2.处于prepare状态的事务,与处于commit状态的事务之间,在备库上也是可以同时执行的
而又两个参数如下
1.binlog_group_commit_sync_delay参数,表示的是延迟多少微秒才能fsync,即刷盘
2.binlog_group_commit_sync_no_delay_count参数,表示累积多少次才调用fsync
可以使用这两个参数故意拉长binlog从write到fsync的时间,以此来减少binlog的写盘次数.(即让主库慢一些,从库就相对看起来快一些)
主从切换
当发生故障时就需要进行主从切换
有以下几种切换方案
基于位点的主备切换
假设B原先是A的备库,现在A挂了,主库变成了A',这个时候B就需要和A'进行同步,相同的日志,A的位点和A'的位点可能是不相同的,因此B在切换的时候,就需要先"找同步位点"
但问题是这个位点并不精确
原因如下
假设主库A已经执行完一个insert语句插入了一行数据R,并且已经将binlog传给了A'和B,然后在传完的瞬间主库A的主机就断电了
那么这个时候
1.在从库B上,由于同步了binlog,R这行已经存在
2.在新主库A'上,R这一行也已经存在了,日志位置假设是写在123这个位置之后的
3.我们在从库B上执行change master命令,执行A'的File文件的123位置,就会把插入R这一行的数据的binlog又同步到从库B去执行,这个时候从库B就会报主键冲突,然后停止同步,这个时候需要手动判断是否需要跳过
基于GTID
GTID的全称就是Global Transaction Identifier,也就是全局事务ID,是一个事务在提交的时候生成的,是这个事务的唯一标识.它由两部分组成,格式如下
GTID=server_uuid:gno
- server_uuid是一个实例第一次启动时自动生成的,是全局唯一的
- gno是一个整数,初始值是1,每次提交事务的时候分配给这个事务,并加1
这样每个Mysql实例都维护一个GTID集合,用来对应"这个实例执行过的所有事务"