0x00 前言
一直以来,爬虫与反爬虫技术都时刻进行着博弈,而新浪微博作为一个数据大户更是在反爬虫上不遗余力。常规手段如验证码、封IP等等相信很多人都见识过……
当然确实有需要的话可以通过新浪开放平台提供的API进行数据采集,但是普通开发者的权限比较低,限制也比较多。所以如果只是做一些简单的功能还是爬虫比较方便~
应该是今年的早些时候,新浪引入了一个Sina Visitor System(新浪访客系统),也不知道是为了提高用户体验还是为了反爬虫,或许是兼而有之。实际结果就是,爬虫取回来的页面全部变成Sina Visitor System了
怎么办呢,我们先来看看这个Sina Visitor System是怎么回事
0x01 分析
也许有人没有见过这个页面,那说明你的浏览器里存有新浪微博的cookie,你可以打开浏览器的隐身模式,然后进入新浪微博首页,就可以看到下面这个样子
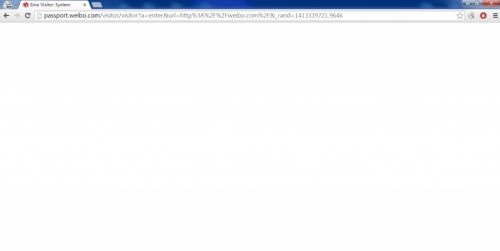
大概过上几秒钟才能进入正常的页面,访问其他weibo.com下的页面如某个用户的主页也是同样的情况
我们可以通过Sina Visitor System的网页源码来看看它到底做了什么
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131Sina Visitor Systemvarurl = url || {};(function() {this.l =function(u, c) {try{vars =document.createElement("script");s.type ="text/javascript";s[document.all ?"onreadystatechange":"onload"] =function() {if(document.all &&this.readyState !="loaded"&&this.readyState !="complete") {return}this[document.all ?"onreadystatechange":"onload"] =null;this.parentNode.removeChild(this);if(c) {c()}};s.src = u;document.getElementsByTagName("head")[0].appendChild(s)}catch(e) {}};}).call(url);//流程入口wload(function() {try{if(!Store.CookieHelper.get('SRF')) {//尝试从cookie获取用户身份,获取失败走创建访客流程tid.get(function(tid, where, confidence) {incarnate(tid, where, confidence);});}else{//用户身份存在,尝试恢复用户身份restore();}}catch(e) {//出错error_back();}});//跳转回初始页面varreturn_back =function(response) {if(response['retcode'] ==20000000) {varurl ="http://weibo.com/";if(url !="none") {window.location.href = url;}}else{//出错error_back(response['msg']);}};//向新浪域发送请求,为新浪域种下访客 cookievar cross_domain =function(response) {varfrom ="weibo";if(response['retcode'] ==20000000) {varcross_domain_intr ="http://login.sina.com.cn/visitor/visitor?a=crossdomain&cb=return_back&s="+encodeURIComponent(response['data']['sub']) +"&sp="+ encodeURIComponent(response['data']['subp']) +"&from="+ from +"&_rand="+ Math.random();url.l(cross_domain_intr);}else{//出错error_back(response['msg']);}};//为用户赋予访客 cookievar incarnate =function(tid, where, conficence) {vargen_conf ="";varfrom ="weibo";varincarnate_intr ="http://passport.weibo.com/visitor/visitor?a=incarnate&t="+encodeURIComponent(tid) +"&w="+ encodeURIComponent(where) +"&c="+ encodeURIComponent(conficence) +"&gc="+ encodeURIComponent(gen_conf) +"&cb=cross_domain&from="+ from +"&_rand="+ Math.random();url.l(incarnate_intr);};//恢复用户在weibo域下的cookievar restore =function() {varfrom ="weibo";varrestore_intr ="http://passport.weibo.com/visitor/visitor?a=restore&cb=restore_back&from="+ from +"&_rand="+ Math.random();url.l(restore_intr);};varrestore_back =function(response) {//身份恢复成功走广播流程,否则走创建访客流程if(response['retcode'] ==20000000) {varurl ="http://weibo.com/";varalt = response['data']['alt'];varsavestate = response['data']['savestate'];if(alt !=''&& url !="none") {varparams ='entry=sso&alt='+ alt +'&returntype=META&url='+ url +'&gateway=1&savestate='+ savestate;window.location.href ='http://login.sina.com.cn/sso/login.php?'+ params;}else{cross_domain(response);}}else{tid.get(function(tid, where, confidence) {incarnate(tid, where, confidence);});}};//出错情况返回原页面varerror_back =function(msg) {varurl ="http://weibo.com/";if(url !="none") {if(url.indexOf('ssovie4c55=0') === -1) {url += (((url.indexOf('?') === -1) ?'?':'&') +'ssovie4c55=0');}window.location.href ='http://weibo.com/login.php';}else{document.getElementById('message').innerHTML ='Error occurred'+ (msg ? (': '+ msg) :'');}}
view rawSina VIsitor System.htmlhosted with ❤ byGitHub
代码不是很多,而且还有中文注释,新浪还真是照顾我们……
根据中文注释就可以知道,它先是判断用户请求中是否携带cookie,如果有就直接进入正常页面,否则就要走访客流程了。
对用户来讲,除非你是第一次进入weibo.com,否则一定会有cookie,自然不会卡在这个页面。而一般的爬虫是不携带cookie的,除非进行了模拟登录或者把已有的cookie放入爬虫的请求中去,否则取回的结果就是Sina Visitor System了
0x02 换个思路
如果从正常角度来想这个问题,肯定是顺着它的代码逻辑来,既然它要检测cookie,那么我们就用爬虫模拟登陆一下或者在HTTP请求中带上已有的cookie不就得了?没错,这样是可行的,但是要注意,模拟登录可能会遇到验证码,而cookie也有一定的有效期,更重要的是这两种方法都需要一个账号,因此这些方法都不是长久之计。
说来也巧,刚好在知乎上看到这样的页面
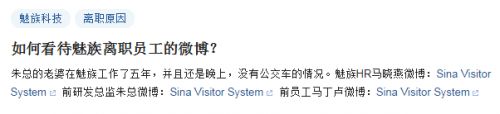
知乎会自动把用户发的链接转换成对应页面的标题,可以看到这里显示的也是Sina Visitor System,说明知乎的爬虫似乎也遇到问题了
但是如果你有注意搜索引擎中新浪微博的结果,就会发现完全不是这样

这说明了什么?说明新浪微博为了让自己的结果呈现在搜索引擎中,对来自搜索引擎的爬虫是“来者不拒”
那么,我们就来试验一下。我用Python写了一个小程序,从一个微博用户的主页中取出该用户的昵称
12345678910111213importrequestsimport rer = requests.get("http://weibo.com/rmrb")p_nick = re.compile(r"CONFIG['onick']='(.*?)'")m_nick = re.findall(p_nick,r.text)iflen(m_nick) ==1:printm_nick[0]else:print"Not found!"#输出#Not found!
view rawtestnospider.pyhosted with ❤ byGitHub
设置一下User-Agent,把自己伪装成搜索引擎爬虫,具体用什么随意啦~谷歌、必应都可以,或者仅仅用spider也行!
1234567891011121314importrequestsimport reuser_agent = {'User-agent':'spider'}r = requests.get("http://weibo.com/rmrb",headers=user_agent)p_nick = re.compile(r"CONFIG['onick']='(.*?)'")m_nick = re.findall(p_nick,r.text)iflen(m_nick) ==1:printm_nick[0]else:print"Not found!"#输出#人民日报
view rawtestspider.pyhosted with ❤ byGitHub
0x03 总结
这个有意思的技巧再一次说明了大道至简~这里我没有进一步进行试验了,如果你有兴趣的话可以试试在设置User-Agent为spider的情况下新浪是否会采取那些反爬虫策略(^_^)
原文:http://www.codeweblog.com/%E5%B0%8F%E6%8A%80%E5%B7%A7%E7%BB%95%E8%BF%87sina-visitor-system-%E6%96%B0%E6%B5%AA%E8%AE%BF%E5%AE%A2%E7%B3%BB%E7%BB%9F/
其他爬取新浪微博参考:http://blog.csdn.net/springzfx/article/details/38435069