川普赢了,这将成为2016年11月8日之后,所有讨论这次总统大选的根本基点。让我感到万分惊讶和沮丧的是,选举结果公布之后成雨后春笋之势的种种复盘之中,各路媒体仍然把民调结果当做一个基本的脉络在把握——「7月份时的邮件门事件曾让川普的支持率反超希拉里」「川普下流言论之后民调显示希拉里有九成胜率」。
拜托,这次选举不就是宣布了民调的破产吗?
我不想说脏话,但是看看《纽约时报》的这张预测图——编辑恬不知耻地将其冠以「赢得大选的几率」的这张图:
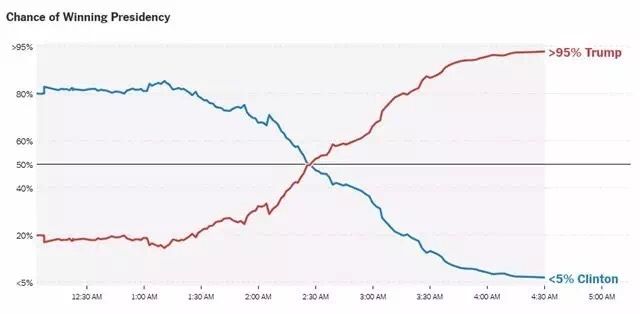
我只能说,如果我是编辑,我会把这张图命名为「我们完全没有任何根据的瞎预测」。
问:「民意」会在短短两小时内完全反转吗?
答:不会。
问:那么,为什么「民调」和「预测」会呢?
答:因为「民调」和「预测」什么都不是。
我没有兴趣去找更多选前各大媒体和调查公司的预测数据贴在这里,相信大家在过去的两三天已经看了很多这些红蓝相间的废品,它们无一例外都与最后结果没有什么联系。英国脱欧公投之前的种种「民调」,也是一样的丑态百出。
下一次还有人拿贴着百分比的饼状图来占领我们的时间线的时候,我们可以对他说:把这些垃圾拿开好吗?
其实相比年年进行的「民调」,对于「激动人心」的美国大选,早有人做出过更大胆的预测尝试。1980年代,耶鲁大学的经济学家根据1912年-1976年的经济数据做出一项回归分析,声称仅需通胀率、GDP增长率等几个数据,套入他们的公式,下一位总统是谁就算出来了。1980年他们预测里根会以55.4%的得票率战胜卡特,最后结果是55.3%,人们咋舌,经济学界轰动。1984年,他们预测里根连任,又算对了。1988年他们预测老布什会轻松战胜杜卡斯基,结果仍如其所料。经济学家们开始洋洋得意,吹嘘其公式的科学性和准确度。直到1992年,根据公式预测老布什会连任,克林顿会落败。
克林顿胜利后,经济学家低调地修改了公式,纠正了「错误」,然后在1996年继续预测,宣布共和党会获胜。然而克林顿以大比分连任,没有人再把这个公式当一回事了。
你也许会说:民调和经济分析不一样,民调可是真正地去采访民众,而不是闭门造车地在家算什么方程。可是,民调本身牵涉到的不确定因素可能比经济分析更多。调查本来就是随机抽取一小部分人,企图用他们的情况来说明整体。这在理想的数学模型里面是成立的——样本越大,结果就越接近真实。但真实的生活千姿百态,所有调查手段都暗藏被蒙蔽的风险。以什么方式进行调查(比如,如果你用电话调查,就已经排除了没有电话或者不爱接电话的样本)、在哪调查、如何统计数据等等决定都足以让调查的「结果」与真实情况谬以千里,更不用说「统计」一词本身所包含的不确定性、研究者的个人偏好、媒体的偏见、政治宣传的需要等等更加难以历数的干扰。
你以为调查者不知道这些不确定因素的存在吗?是啊,他们知道,所以他们决定「修正」自己的数据——而修正的方法,同样无外乎一套闭门造车的公式,而结果,自然并不会比他们「修正」之前好到哪里去,甚至可能更糟。
即使看看这次被「打脸」的统计机构内部,我们也会发现他们根本不可信。
《纽约时报》旗下数据分析网站Upshot预测希拉里有85%的几率获胜,《赫芬顿邮报》预测希拉里的胜率为98.3%,Nate Sliver旗下网站FiveThirtyEight预测希拉里胜率为66.9%,而普林斯顿选举联盟则给出了惊人的99%胜选率。
虽然他们的结论相同——希拉里「大概率」会当选,但统计出的数字有的高达99%,有的却只有66.9%。显然,在得出99%与66.9%的机构当中,最多只有有一家是「正确」的——当然,我们看到,他们都错得离谱。

我一直认为,统计是最廉价的一种「科研」——这种廉价指的不是耗费的金钱少,而是最不需要动脑子、最不需要后续的验证。装模作样地设计一份问卷,找几个人把它们分发出去,拿回来,录入电脑,得出数据,做几幅统计图,然后拍脑袋地想出几个可能根本不符合事实的「结论」写上去,一次「研究」就完成了。我之所以说得这么溜,是因为我自己就做过这样的「研究」——和我在世界各地的同龄人以及我们的教授一样。如果你问我们的那个研究小组,我们认为自己的研究有多少价值,我们会告诉你它并没有什么价值,甚至不值得参考。但是我们还是做了,为了完成一项「科研任务」。
这就是现代学术界的一桩怪现象,它不止发生在中国,还发生在世界的每一个角落。坐在大学舒适的办公室里的学者,用「调查统计」研究肚子疼的概率和世界经济变化之间的联系,同时还教授他们的学生也这样去做。每年全球的学术界出产千千万万这样的垃圾论文,它们浪费了无数纸张和时间,唯一的作用是给出各种稀奇古怪不可信的数据和从中得出的更不可信的结论。
媒体也倚仗这些「研究」结果,将它们作为社会的现实大加宣传。我本人是《经济学人》(The Economist)的「忠实」读者。(顺便一提,我非常高兴他们一直不遗余力地加持的希拉里输掉了选举,真是痛快。看到他们几个月来对川普的丑闻百般挖苦、不断重提,对希拉里的阴暗一面却千方百计地不提或淡化,实在是让我肝火直冒。当然,我敢说下一期他们要悲惨地呼号美国完蛋了,哈哈哈哈。)该刊从创立时起就是全球化和新自由主义的忠实拥趸。在一个月前的10月1日刊中,他们的封面文章 Anti-globalists:Why they’re wrong 就把统计数据用作了鼓吹全球化的有力工具:
Protectionism, by contrast, hurts consumers and does little for workers. The worst-off benefit far more from trade than the rich. A study of 40 countries found that the richest consumers would lose 28% of their purchasing power if cross-border trade ended; but those in the bottom tenth would lose 63%. The annual cost to American consumers of switching to non-Chinese tyres after Barack Obama slapped on anti-dumping tariffs in 2009 was around $1.1 billion, according to the Peterson Institute for International Economics. That amounts to over $900,000 for each of the 1,200 jobs that were “saved”.
「如果没有全球化,最富有的消费者会失去28%的「消费能力」,而最贫穷的十分之一则会失去63%;从奥巴马2009年反倾销后美国用户换用非中国制轮胎每年造成的费用是11亿美元,超过了创造的1200个职位的价值」——我们不禁要问,「最富有的消费者」指的是最富有的百分之几?「消费能力」怎样测算?换用非中国制轮胎的「费用」包括人员工资本身吗?——可惜,这一切都不是武断且不报任何怀疑的《经济学人》的编辑和作者所关心的。他们关心的只不过是这些数据能不能附和他们写这篇文章的观点。
我相信,同时有很多的统计数据会证明,全球化并没有让一些人的生活变得更好。但是我们肯定不会在《经济学人》上看到它们。至于他们标明的这家研究机构——"the Peterson Institute for International Economics"——我们已经在无数的例子里见识过,这些机构的研究成果与它们吓人的名头相比往往是多么不相称。
我做上面说的那项「研究」的时候,也读了三本关于调查问卷的设计方法和统计学基本原理的书。虽然书里说的原理让我们在设计问卷、设置问题时稍微「科学」了一点,但也让我更明白调查这种形式想要反映真实是多么困难。从统计数据这种形式诞生起,人们就对它着迷不已——将千千万万个人、千千万万种状况,缩略为几个简单的数字,这将人类大脑所不能处理的信息变成了可以处理的,但代价,就是我们所面对的信息在或大或小的程度上失真。对于人类心理的调查,是其中失真程度极高的一种:抱有某种心理的人可能很乐意表达,其他的人可能完全不;不同心理的人表达的方式也不同。这次美国大选的中可能还存在着「沉默的螺旋」的作用——川普的支持者因为受到主流舆论的影响和孤立而不敢表达自己,但到了投票站却可以自由地投出一票。不过这就是另一篇文章了。
「谎言分两种,一种是谎言,另一种是统计数据。」下次当在报纸上看到「%」号的时候,记得这句话。