姓名:闫伟 学号:15020150038
转载自:https://zhuanlan.zhihu.com/p/47341761
【嵌牛导读】:OpenCV是Intel开发并维护的一种常用的计算机视觉库,它在道路交通领域有着广泛的应用
【嵌牛鼻子】:Python OpenCV
【嵌牛提问】:如何用基于计算机视觉技术的方法计算道路上的车流量
【嵌牛正文】:
在本教程,我们只用到 Python 和 OpenCV,以及在背景减除算法辅助下使用一点很简单的运动检测原理。
项目所有代码地址见文末。
以下是我们的整体计划:
理解用于前景检测的背景去除算法的主要理念
OpenCV图像过滤器
为进一步数据操作创建数据处理工作流
最终我们会得到如视频所示的结果:
背景去除算法
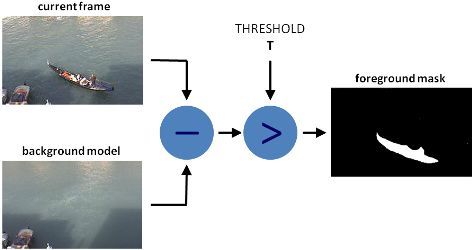
有不少算法可以用于背景去除,但它们的主要理念都比较简单。
假设你有一段自己房间的监控视频,在其中一些视频帧上没有人也没有宠物出现,那么基本上画面就是静止的,我们称之为 background_layer,即背景层。所以要想获取视频画面上的移动物体,我们只需:
foreground_objects = current_frame - background_layer
但在一些情况下,我们无法得到静止帧,因为出现光线发生改变,某些物体被人拿走,或者总是处于移动状态等等。在这些情况下,我们需要保存一定数量的帧,努力找出哪些像素大部分是一样的,然后让这些像素成为 background_layer 的一部分。整体上的区别是我们该如何获取 background_layer 和用于实现更精准检测的额外过滤操作。
在本文,我们会用 MOG 算法执行背景减除操作,经过处理后的背景会如下所示:

图:左为原始帧,右为MOG进行背景减除后的帧
可以看到,前景蒙版中存在一些噪声数据,我们要使用一些过滤方法将它们去除。
此时我们的代码如下所示:
import osimport loggingimport logging.handlersimport randomimport numpy as npimport skvideo.ioimport cv2import matplotlib.pyplot as pltimport utils# 没有它会出现一些奇怪的错误cv2.ocl.setUseOpenCL(False)random.seed(123)# ============================================================================IMAGE_DIR = "./out"VIDEO_SOURCE = "input.mp4"SHAPE = (720, 1280) # HxW# ============================================================================def train_bg_subtractor(inst, cap, num=500): ''' BG substractor need process some amount of frames to start giving result ''' print ('Training BG Subtractor...') i = 0 for frame in cap: inst.apply(frame, None, 0.001) i += 1 if i >= num: return capdef main(): log = logging.getLogger("main") # 用缓存中的500帧创建MOG背景减除器和阴影检测 bg_subtractor = cv2.createBackgroundSubtractorMOG2( history=500, detectShadows=True) # 设置图像源 # 你还可以用CV2 cap = skvideo.io.vreader(VIDEO_SOURCE) # 跳过500帧,训练背景减除器 train_bg_subtractor(bg_subtractor, cap, num=500) frame_number = -1 for frame in cap: if not frame.any(): log.error("Frame capture failed, stopping...") break frame_number += 1 utils.save_frame(frame, "./out/frame_%04d.png" % frame_number) fg_mask = bg_subtractor.apply(frame, None, 0.001) utils.save_frame(frame, "./out/fg_mask_%04d.png" % frame_number)# ============================================================================if __name__ == "__main__": log = utils.init_logging() if not os.path.exists(IMAGE_DIR): log.debug("Creating image directory `%s`...", IMAGE_DIR) os.makedirs(IMAGE_DIR) main()
过滤
在我们这个项目中,需要这些过滤器:Threshold(http://docs.opencv.org/3.1.0/d7/d4d/tutorial_py_thresholding.html),Erode(http://docs.opencv.org/3.1.0/d9/d61/tutorial_py_morphological_ops.html),Dilate(http://docs.opencv.org/3.1.0/d9/d61/tutorial_py_morphological_ops.html),Opening(http://docs.opencv.org/3.1.0/d9/d61/tutorial_py_morphological_ops.html),Closing(http://docs.opencv.org/3.1.0/d9/d61/tutorial_py_morphological_ops.html)。
可以点开链接,详细阅读它们的工作原理。
现在我们就用这些过滤器来移除前景蒙版中的噪声数据。
首先,我们用 Closing 移除各区域中的间隙,然后用 Opening 移除 1-2 个像素点,之后用 Dilate 让物体变得更粗一些。
def filter_mask(img): kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (2, 2)) # 填充所有细小的孔洞 closing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel) # 移除噪声 opening = cv2.morphologyEx(closing, cv2.MORPH_OPEN, kernel) # 用Dilate融合相邻斑点 dilation = cv2.dilate(opening, kernel, iterations=2) # threshold th = dilation[dilation < 240] = 0 return th
经过以上处理后,我们的前景变成这样:

借助轮廓来检测物体
在物体检测这部分,我们使用标准的带有参数的 cv2.findContours 方法:
cv2.CV_RETR_EXTERNAL — get only outer contours.cv2.CV_CHAIN_APPROX_TC89_L1 - use Teh-Chin chain approximation algorithm (faster)def get_centroid(x, y, w, h): x1 = int(w / 2) y1 = int(h / 2) cx = x + x1 cy = y + y1 return (cx, cy)def detect_vehicles(fg_mask, min_contour_width=35, min_contour_height=35): matches = [] # 寻找外部轮廓 im, contours, hierarchy = cv2.findContours( fg_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_TC89_L1) # 按照宽度和高度过滤 for (i, contour) in enumerate(contours): (x, y, w, h) = cv2.boundingRect(contour) contour_valid = (w >= min_contour_width) and ( h >= min_contour_height) if not contour_valid: continue # 获取边界框的中心点 centroid = get_centroid(x, y, w, h) matches.append(((x, y, w, h), centroid))return matches
在画面出口区域,我们增加了一些根据高度、宽度的过滤,并添加了形心(centroid)。
创建处理工作流
你一定知道在机器学习和计算机视觉中并没有一个很神奇的算法能解决所有事情,即便假想有这么一种算法存在,我们也不会用它,因为这样在大规模应用时就不会很有效。例如,几年前 Netflix 悬赏 3 百万美元征集效果最好的电影推荐算法,其中有个团队就创建了这样一种算法,却无法大规模解决问题,结果对 Netflix 几乎没有用处。
所以现在我们创建一个简单的处理工作流,当然不是出于大规模应用考虑,而是为了更方便,但二者的理念是一样的。
class PipelineRunner(object): ''' Very simple pipline. Just run passed processors in order with passing context from one to another. You can also set log level for processors. ''' def __init__(self, pipeline=None, log_level=logging.DEBUG): self.pipeline = pipeline or [] self.context = {} self.log = logging.getLogger(self.__class__.__name__) self.log.setLevel(log_level) self.log_level = log_level self.set_log_level() def set_context(self, data): self.context = data def add(self, processor): if not isinstance(processor, PipelineProcessor): raise Exception( 'Processor should be an isinstance of PipelineProcessor.') processor.log.setLevel(self.log_level) self.pipeline.append(processor) def remove(self, name): for i, p in enumerate(self.pipeline): if p.__class__.__name__ == name: del self.pipeline[i] return True return False def set_log_level(self): for p in self.pipeline: p.log.setLevel(self.log_level) def run(self): for p in self.pipeline: self.context = p(self.context) self.log.debug("Frame #%d processed.", self.context['frame_number']) return self.contextclass PipelineProcessor(object): ''' Base class for processors. ''' def __init__(self): self.log = logging.getLogger(self.__class__.__name__)
输入构建器会取一列处理器,按顺序运行。每个处理器都是这项工作的一部分。我们来创建轮廓检测处理器。
class ContourDetection(PipelineProcessor): ''' Detecting moving objects. Purpose of this processor is to subtrac background, get moving objects and detect them with a cv2.findContours method, and then filter off-by width and height. bg_subtractor - background subtractor isinstance. min_contour_width - min bounding rectangle width. min_contour_height - min bounding rectangle height. save_image - if True will save detected objects mask to file. image_dir - where to save images(must exist). ''' def __init__(self, bg_subtractor, min_contour_width=35, min_contour_height=35, save_image=False, image_dir='images'): super(ContourDetection, self).__init__() self.bg_subtractor = bg_subtractor self.min_contour_width = min_contour_width self.min_contour_height = min_contour_height self.save_image = save_image self.image_dir = image_dir def filter_mask(self, img, a=None): ''' This filters are hand-picked just based on visual tests ''' kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (2, 2)) # 找到所有细小孔洞 closing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel) # 移除噪声数据 opening = cv2.morphologyEx(closing, cv2.MORPH_OPEN, kernel) # 用Dilate融合邻近斑点 dilation = cv2.dilate(opening, kernel, iterations=2) return dilation def detect_vehicles(self, fg_mask, context): matches = [] # 找到外部轮廓 im2, contours, hierarchy = cv2.findContours( fg_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_TC89_L1) for (i, contour) in enumerate(contours): (x, y, w, h) = cv2.boundingRect(contour) contour_valid = (w >= self.min_contour_width) and ( h >= self.min_contour_height) if not contour_valid: continue centroid = utils.get_centroid(x, y, w, h) matches.append(((x, y, w, h), centroid)) return matches def __call__(self, context): frame = context['frame'].copy() frame_number = context['frame_number'] fg_mask = self.bg_subtractor.apply(frame, None, 0.001) # just thresholding values fg_mask[fg_mask < 240] = 0 fg_mask = self.filter_mask(fg_mask, frame_number) if self.save_image: utils.save_frame(fg_mask, self.image_dir + "/mask_%04d.png" % frame_number, flip=False) context['objects'] = self.detect_vehicles(fg_mask, context) context['fg_mask'] = fg_mask return contex
我们将背景减除、过滤和目标检测部分融合在一起。
现在,我们创建一个处理器,能把在不同视频帧上检测到的物体连接在一起,并创建路径,也会计算进入出口区域的车辆数量。
''' Counting vehicles that entered in exit zone. Purpose of this class based on detected object and local cache create objects pathes and count that entered in exit zone defined by exit masks. exit_masks - list of the exit masks. path_size - max number of points in a path. max_dst - max distance between two points. ''' def __init__(self, exit_masks=[], path_size=10, max_dst=30, x_weight=1.0, y_weight=1.0): super(VehicleCounter, self).__init__() self.exit_masks = exit_masks self.vehicle_count = 0 self.path_size = path_size self.pathes = [] self.max_dst = max_dst self.x_weight = x_weight self.y_weight = y_weight def check_exit(self, point): for exit_mask in self.exit_masks: try: if exit_mask[point[1]][point[0]] == 255: return True except: return True return False def __call__(self, context): objects = context['objects'] context['exit_masks'] = self.exit_masks context['pathes'] = self.pathes context['vehicle_count'] = self.vehicle_count if not objects: return context points = np.array(objects)[:, 0:2] points = points.tolist() # 若路径为空,则添加新的点 if not self.pathes: for match in points: self.pathes.append([match]) else: # 根据点之间的最小距离将新点和旧路径连接在一起 new_pathes = [] for path in self.pathes: _min = 999999 _match = None for p in points: if len(path) == 1: # 最后一个点和当前点之间的距离 d = utils.distance(p[0], path[-1][0]) else: # 根据两个前面的点预测新点 # 并计算预测的新点和当前点的距离 xn = 2 * path[-1][0][0] - path[-2][0][0] yn = 2 * path[-1][0][1] - path[-2][0][1] d = utils.distance( p[0], (xn, yn), x_weight=self.x_weight, y_weight=self.y_weight ) if d < _min: _min = d _match = p if _match and _min <= self.max_dst: points.remove(_match) path.append(_match) new_pathes.append(path) # 如果当前帧没有匹配,不要丢弃路径 if _match is None: new_pathes.append(path) self.pathes = new_pathes # 添加新路径 if len(points): for p in points: # 不要添加应当已经被计算的点 if self.check_exit(p[1]): continue self.pathes.append([p]) # 只保存路径中最后N个点 for i, _ in enumerate(self.pathes): self.pathes[i] = self.pathes[i][self.path_size * -1:] # 计算车辆,并丢弃计算后的路径: new_pathes = [] for i, path in enumerate(self.pathes): d = path[-2:] if ( # 至少需要两个点来计算 len(d) >= 2 and # 前面的点不在出口区域 not self.check_exit(d[0][1]) and # 当前点在出口区域 self.check_exit(d[1][1]) and # 路径长度大于最小值 self.path_size <= len(path) ): self.vehicle_count += 1 else: # 防止和已在出口区域的路径相连 add = True for p in path: if self.check_exit(p[1]): add = False break if add: new_pathes.append(path) self.pathes = new_pathes context['pathes'] = self.pathes context['objects'] = objects context['vehicle_count'] = self.vehicle_count self.log.debug('#VEHICLES FOUND: %s' % self.vehicle_count) return context
这里稍微有些复杂,我们一步步说。
图像中的绿色蒙版表示出口区域,就是我们计算车辆数量的地方。例如,我们会只计算长度超过 3 个点(以去除一些噪声数据)的路径,以及绿色区域的第 4 个点。
我们使用蒙版,是因为相比使用向量算法,它的操作更高效更简单。只需用“binary and”操作检查区域内的点,就行了。我们的设置如下:
EXIT_PTS = np.array([ [[732, 720], [732, 590], [1280, 500], [1280, 720]], [[0, 400], [645, 400], [645, 0], [0, 0]]])base = np.zeros(SHAPE + (3,), dtype='uint8')exit_mask = cv2.fillPoly(base, EXIT_PTS, (255, 255, 255))[:, :, 0]
现在我们将路径上的点相连。
new_pathes = []for path in self.pathes: _min = 999999 _match = None for p in points: if len(path) == 1: # 最后一个点和当前点的距离 d = utils.distance(p[0], path[-1][0]) else: # 根据前面2个点预测接下来的点 # 并计算预测的新点和当前点之间的距离 xn = 2 * path[-1][0][0] - path[-2][0][0] yn = 2 * path[-1][0][1] - path[-2][0][1] d = utils.distance( p[0], (xn, yn), x_weight=self.x_weight, y_weight=self.y_weight ) if d < _min: _min = d _match = p if _match and _min <= self.max_dst: points.remove(_match) path.append(_match) new_pathes.append(path) # 若当前帧未匹配,不要丢弃路径 if _match is None: new_pathes.append(path)self.pathes = new_pathes# 添加新路径if len(points): for p in points: # do not add points that already should be counted if self.check_exit(p[1]): continue self.pathes.append([p])# 只保存路径中最后N个点for i, _ in enumerate(self.pathes): self.pathes[i] = self.pathes[i][self.path_size * -1:]
在第一帧,我们只将所有点添加为新路径。
接着如果长度等于 1,对于缓存中的每个路径我们会尝试找到新检测到的物体的点(形心),它和路径的最后一个点的欧几里得距离最小。
如果长度大于 1,那么用路径中的最后两个点我们预测同一条线上的新的点,并找到它和当前点之间的最小距离。
将具有最小距离的点添加至当前路径末尾,并从列表移除。
如果经过这部操作后还剩有一些点,我们将其添加为新路径。
另外我们还限制路径中的点的数量。
# 计算车辆,并丢弃计算后的路径:new_pathes = []for i, path in enumerate(self.pathes): d = path[-2:] if ( # 需要至少两个点来计算 len(d) >= 2 and # 前面的点不在出口区域中 not self.check_exit(d[0][1]) and # 当前点在出口区域中 self.check_exit(d[1][1]) and # 路径长度大于最小值 self.path_size <= len(path) ): self.vehicle_count += 1 else: # 防止和已在出口区域中的路径相连 add = True for p in path: if self.check_exit(p[1]): add = False break if add: new_pathes.append(path)self.pathes = new_pathescontext['pathes'] = self.pathescontext['objects'] = objectscontext['vehicle_count'] = self.vehicle_countself.log.debug('#VEHICLES FOUND: %s' % self.vehicle_count)return context
现在我们尝试计算进入出口区域内的车辆数量。完成这一步,我们只需取路径中最后两个点,在出口区域检查它们,还要确保长度应大于限制条件。
剩余部分就是防止发生回连,将新点连接至当前区域中的点。
最后两个处理器是 CSV 写入器,用于创建 CSV 格式的报告文件,可视化调试和创建美观的图形。
class CsvWriter(PipelineProcessor): def __init__(self, path, name, start_time=0, fps=15): super(CsvWriter, self).__init__() self.fp = open(os.path.join(path, name), 'w') self.writer = csv.DictWriter(self.fp, fieldnames=['time', 'vehicles']) self.writer.writeheader() self.start_time = start_time self.fps = fps self.path = path self.name = name self.prev = None def __call__(self, context): frame_number = context['frame_number'] count = _count = context['vehicle_count'] if self.prev: _count = count - self.prev time = ((self.start_time + int(frame_number / self.fps)) * 100 + int(100.0 / self.fps) * (frame_number % self.fps)) self.writer.writerow({'time': time, 'vehicles': _count}) self.prev = count return contextclass Visualizer(PipelineProcessor): def __init__(self, save_image=True, image_dir='images'): super(Visualizer, self).__init__() self.save_image = save_image self.image_dir = image_dir def check_exit(self, point, exit_masks=[]): for exit_mask in exit_masks: if exit_mask[point[1]][point[0]] == 255: return True return False def draw_pathes(self, img, pathes): if not img.any(): return for i, path in enumerate(pathes): path = np.array(path)[:, 1].tolist() for point in path: cv2.circle(img, point, 2, CAR_COLOURS[0], -1) cv2.polylines(img, [np.int32(path)], False, CAR_COLOURS[0], 1) return img def draw_boxes(self, img, pathes, exit_masks=[]): for (i, match) in enumerate(pathes): contour, centroid = match[-1][:2] if self.check_exit(centroid, exit_masks): continue x, y, w, h = contour cv2.rectangle(img, (x, y), (x + w - 1, y + h - 1), BOUNDING_BOX_COLOUR, 1) cv2.circle(img, centroid, 2, CENTROID_COLOUR, -1) return img def draw_ui(self, img, vehicle_count, exit_masks=[]): # 为图像添加绿色蒙版 for exit_mask in exit_masks: _img = np.zeros(img.shape, img.dtype) _img[:, :] = EXIT_COLOR mask = cv2.bitwise_and(_img, _img, mask=exit_mask) cv2.addWeighted(mask, 1, img, 1, 0, img) # 画出顶部区域 cv2.rectangle(img, (0, 0), (img.shape[1], 50), (0, 0, 0), cv2.FILLED) cv2.putText(img, ("Vehicles passed: {total} ".format(total=vehicle_count)), (30, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (255, 255, 255), 1) return img def __call__(self, context): frame = context['frame'].copy() frame_number = context['frame_number'] pathes = context['pathes'] exit_masks = context['exit_masks'] vehicle_count = context['vehicle_count'] frame = self.draw_ui(frame, vehicle_count, exit_masks) frame = self.draw_pathes(frame, pathes) frame = self.draw_boxes(frame, pathes, exit_masks) utils.save_frame(frame, self.image_dir + "/processed_%04d.png" % frame_number) return context
CSV 写入器会按时间保存数据,因为我们需要用它做进一步分析。我用的是这种格式往 unixtimestamp 中添加额外的帧定时:
开始时间 =1 000 000 000,fps=10,我会得到如下结果
帧1=1 000 000 000 010
帧2=1 000 000 000 020
…
然后在你获取完整的 CSV 报告后,可以按自己需要将数据合计在一起。
结语
可以看到,也不是很难。但如果你运行程序的话会发现这项解决方案也算不上完美,前景会出现物体重叠的问题,而且也无法按类型将车辆分类(在实际分析中肯定会需要这个)。但如果有高质量的摄像头(设在马路上方),程序还是有很高的准确率。这也告诉我们,如果是正确使用,即便是很小很简单的算法也能得到好结果。