1 导入sklearn的分类库
# 通用算法模型
from sklearn import svm, tree, linear_model, neighbors, naive_bayes, ensemble, discriminant_analysis, gaussian_process
from xgboost import XGBClassifier
# 通用帮助模型
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
from sklearn import feature_selection
from sklearn import model_selection
from sklearn import metrics
# 可视化模块
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.pylab as pylab
import seaborn as sns
from pandas.tools.plotting import scatter_matrix
# 数据操作
import numpy as np
import pandas as pd
color = sns.color_palette()
# 配置可视化的默认值
%matplotlib inline
mpl.style.use('ggplot')
sns.set_style('white')
pylab.rcParams['figure.figsize'] = 12, 8
pd.options.mode.chained_assignment = None
pd.options.display.max_columns = 999
2 数据读入
df1 = pd.read_csv("./data/20180506/1.dat")
df2 = pd.read_csv("./data/20180506/2.dat")
df3 = pd.read_csv("./data/20180506/3.dat")
df4 = pd.read_csv("./data/20180506/4.dat")
df5 = pd.read_csv("./data/20180506/5.dat")
data = df5.append(df4)
data = data.append(df3)
data = data.append(df2)
data = data.append(df1)
data.columns = ['c_num_pack', 's_num_pack', 'total_num_pack', 'c_pack_size_expec', 's_pack_size_expec', 'c_pack_per_sec','s_pack_per_sec', 'c_pack_size_var', 's_pack_size_var', 'total_c_bytes', 'total_s_bytes', 'c_bytes_per_sec','s_bytes_per_sec','down_to_up_ratio', 'protocal']
print(data.info())
查看一下数字

数据概述
3 数据整理
# Converting to categorical data
Target = ['protocal']
data1_x = ['c_num_pack', 's_num_pack', 'total_num_pack', 'c_pack_size_expec',
's_pack_size_expec', 'c_pack_per_sec', 's_pack_per_sec',
'c_pack_size_var', 's_pack_size_var', 'total_c_bytes',
'total_s_bytes', 'c_bytes_per_sec', 's_bytes_per_sec',
'down_to_up_ratio']
data1_xy = Target + data1_x
print('Original X Y', data1_xy, '\n')
train1_x, test1_x, train1_y, test1_y = model_selection.train_test_split(data[data1_x], data[Target], random_state=0)
print('Datal Shape: {}'.format(data.shape))
train1_x.head()

image.png
4 数据探索
# Important: Intentionally plotted different ways for learning purposes only
# optional plotting w/pandas
#
plt.figure(figsize=(16, 12))
plt.subplot(231)
plt.boxplot(x=data['c_num_pack'], showmeans=True, meanline=True)
plt.title('client_num_pack Boxplot')
plt.ylabel('nums (num)')
plt.subplot(232)
plt.boxplot(data['s_num_pack'], showmeans=True, meanline=True)
plt.title('server_num_packets Boxplot')
plt.ylabel('Packets (num)')
plt.subplot(233)
plt.boxplot(data['total_num_pack'],showmeans=True, meanline=True)
plt.ylabel('total num packets')
plt.subplot(234)
plt.hist(x=[data[data['protocal']==1]['total_num_pack'], data[data['protocal']==1]['down_to_up_ratio']], stacked=True, color=['g', 'r'], label=['packets', 'ratio'])
plt.title('protocal 1 ')
plt.xlabel('num {packets}')
plt.ylabel('ratio')
plt.legend()
'''
plt.subplot(235)
plt.hist(x=[data1[data1['Survived']==1]['Age'], data1[data1['Survived']==0]['Age']], stacked=True, color=['g', 'r'], label=['Survived', 'Dead'])
plt.title('Age Histogram by Survival')
plt.xlabel('Age (Years)')
plt.ylabel('# of Passengers')
plt.legend()
plt.subplot(236)
plt.hist(x=[data1[data1['Survived']==1]['FamilySize'], data1[data1['Survived']==0]['FamilySize']], stacked=True, color=['g', 'r'], label=['Survived', 'Dead'])
plt.title('Family Size Histogram by Survival')
plt.xlabel('Family Size(#)')
plt.ylabel('# of Passengers')
plt.legend()
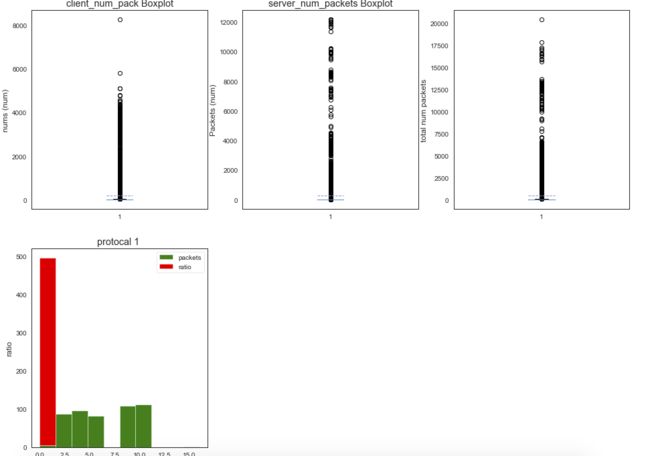
exploration
f, ax = plt.subplots(1, 2, figsize=(20, 10))
data1 = data.copy(deep=True)
data1['protocol_type'] = 'unkowntype'
for i, t in enumerate(['ICMP', 'UDP', 'SMTP', 'POP3', 'IMAP', 'HTTP', 'TCP-NC', 'FTP', 'SSH']):
data1.loc[data1.protocal == i+1, 'protocol_type'] = t
data1['protocol_type'].value_counts().plot.pie(autopct='%1.1f%%', ax=ax[0], shadow=True)
ax[0].set_title('protocal')
ax[0].set_ylabel('')
sns.countplot('protocol_type', data=data1, ax=ax[1])
ax[1].set_title('protocol')
plt.show()

image.png
f, ax = plt.subplots(1, 2, figsize=(20, 10))
sns.violinplot('total_num_pack', 'total_c_bytes', hue='protocol_type', data=data1, ax=ax[0])
sns.violinplot('total_num_pack', 'total_s_bytes', hue='protocol_type', data=data1, ax=ax[1])

image.png
5 开始跑模型
# Machine Learning Algorithm (MLA) Selection and Initialization
MLA = [
# Ensemble Methods
ensemble.AdaBoostClassifier(),
ensemble.BaggingClassifier(),
ensemble.ExtraTreesClassifier(),
ensemble.GradientBoostingClassifier(),
ensemble.RandomForestClassifier(),
# Gaussian Processes
# gaussian_process.GaussianProcessClassifier(),
#GLM
linear_model.LogisticRegressionCV(),
linear_model.PassiveAggressiveClassifier(),
linear_model.RidgeClassifierCV(),
linear_model.SGDClassifier(),
linear_model.Perceptron(),
#Navies Bayes
naive_bayes.BernoulliNB(),
naive_bayes.GaussianNB(),
#Nearest Neighbor
neighbors.KNeighborsClassifier(),
# SVM
svm.SVC(probability=True),
# svm.NuSVC(probability=True),
svm.LinearSVC(),
# Trees
tree.DecisionTreeClassifier(),
tree.ExtraTreeClassifier(),
#Discriminant Analysis
discriminant_analysis.LinearDiscriminantAnalysis(),
discriminant_analysis.QuadraticDiscriminantAnalysis(),
XGBClassifier()
]
cv_split = model_selection.ShuffleSplit(n_splits=10, test_size=.3, train_size=.6, random_state=0)
MLA_columns = ['MLA Name', 'MLA Parameters', 'MLA Train Accuracy Mean', 'MLA Test Accuracy Mean', 'MLA Test Accuracy 3*STD', 'MLA Time']
MLA_compare = pd.DataFrame(columns=MLA_columns)
MLA_predict = data[Target]
row_index = 0
for i, alg in enumerate(MLA):
print(i, alg.__class__.__name__)
MLA_name = alg.__class__.__name__
MLA_compare.loc[row_index, 'MLA Name'] = MLA_name
MLA_compare.loc[row_index, 'MLA Parameters'] = str(alg.get_params())
cv_results = model_selection.cross_validate(alg, data[data1_x], data[Target].values.ravel(), cv = cv_split, return_train_score=True)
MLA_compare.loc[row_index, 'MLA Time'] = cv_results['fit_time'].mean()
MLA_compare.loc[row_index, 'MLA Train Accuracy Mean'] = cv_results['train_score'].mean()
MLA_compare.loc[row_index, 'MLA Test Accuracy Mean'] = cv_results['test_score'].mean()
MLA_compare.loc[row_index, 'MLA Test Accuracy 3*STD'] = cv_results['test_score'].std()*3
alg.fit(data[data1_x], data[Target].values.ravel())
MLA_predict[MLA_name] = alg.predict(data[data1_x])
row_index += 1
MLA_compare.sort_values(by=['MLA Test Accuracy Mean'], ascending=False, inplace=True)
MLA_compare
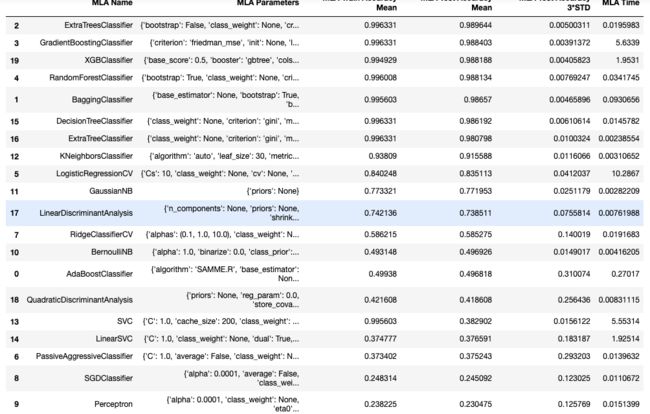
6 准确度排序

accurate
7 输入相关分析
def correlation_heatmap(df):
_, ax = plt.subplots(figsize=(14, 12))
colormap = sns.diverging_palette(220, 10, as_cmap=True)
_ = sns.heatmap(
df.corr(),
cmap=colormap,
square=True,
ax=ax,
annot=True,
linewidths=0.1,
vmax=1.0, linecolor='white',
annot_kws={'fontsize':12}
)
plt.title('Pearson Correlation of Feature', y=0.05, size=15)
correlation_heatmap(data)

relation