第一、Python
本人跟随廖雪峰的Python3教程学习的,在这里总能看到一起学习的小伙伴们积极交作业,回答问题。
心得:(1).学习python语法;(2).学python就是在学库
1.在python IDE中执行print('hello, world')输出语句,就能打印出hello,world
2.输入的操作是name = input()
3.Python语法简单,采用缩进(4个空格)方式,如下:
# print absolute value of an integer
a =100
if a >= 0:
print(a)
else:
print(-a)
4.数据类型有:整型(100)、浮点型(1.11)、字符串(字符串是以单引号'或双引号"括起来的任意文本,如'abc',"xyz")、布尔型(True,False)、空值(None)、变量(大小写英文、数字和_的组合,且不能用数字开头)、常量(PI=3.14159265359,“//”称为地板除,两个整数的除法仍然是整数,如10// 3=3)
5.字符串和编码部分,建议仔细看看该教程,对你帮助一定很大
6.使用list和tuple。list是一种有序的集合,可以随时添加和删除其中的元素。
比如,列出班里所有同学的名字,就可以用一个list表示:classmates = ['Michael','Bob','Tracy'],然后通过下标索引classmates[0] -> 'Michael'。可使用追加append(‘追加内容’),插入insert(索引号,‘插入内容’),删除list末尾元素pop()方法。
tuple和list非常类似,但是tuple一旦初始化就不能修改,比如同样是列出同学的名字:classmates = ('Michael','Bob','Tracy'),可以索引到具体的值,但不能更改。
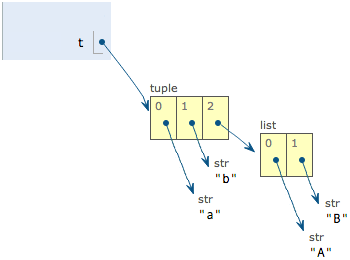
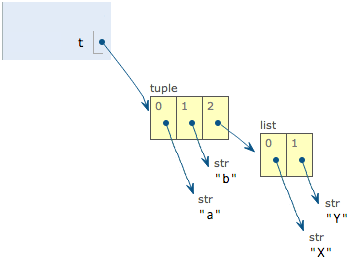
list和tuple举例:
>>>t = ('a','b', ['A','B'])
>>>t[2][0] ='X'
>>>t[2][1] ='Y'
>>>t('a','b', ['X','Y'])
7.条件判断
age =3
if age >=18:
print('adult')
elif age >=6:
print('teenager')
else:
print('kid')
8.循环
sum =0
for x in [1,2,3,4,5,6,7,8,9,10]:
sum = sum + x
print(sum)
9.dict全称dictionary,在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度。
>>>d = {'Michael':95,'Bob':75,'Tracy':85}
>>>d['Michael']
95
get(key)、pop(key)方法
请务必注意,dict内部存放的顺序和key放入的顺序是没有关系的。
dict特点:
查找和插入的速度极快,不会随着key的增加而变慢;
需要占用大量的内存,内存浪费多。
list特点:
查找和插入的时间随着元素的增加而增加;
占用空间小,浪费内存很少。
所以,dict是用空间来换取时间的一种方法。
dict可以用在需要高速查找的很多地方,在Python代码中几乎无处不在,正确使用dict非常重要,需要牢记的第一条就是dict的key必须是不可变对象。
10.set
set和dict类似,也是一组key的集合,但不存储value。由于key不能重复,所以,在set中,没有重复的key
>>>s = set([1,1,2,2,3,3])
>>>s
{1,2,3}
add(key)、remove(key)方法。
11.函数:abs(),max(),int('123'),float('12.34'),str(1.23),bool(1)
def my_abs(x):
if not isinstance(x, (int, float)):
raise TypeError('bad operand type')
if x >= 0:
return x
else:
return -x
设置默认参数函数:
def power(x, n=2):
s =1
while n > 0:
n = n -1
s = s * x
return s
12.传入函数
def add(x, y, f):
return f(x) + f(y)
>>>add(-5,6, abs) #验证add函数
11
13.map reduce方法
map()函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。
>>>def f(x):
...return x * x
...
>>>r = map(f, [1,2,3,4,5,6,7,8,9])
>>>list(r)
[1,4,9,16,25,36,49,64,81]
reduce把一个函数作用在一个序列[x1, x2, x3, ...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算,其效果就是:
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
>>>from functools import reduce
>>>def fn(x, y):
...return x *10+ y
...
>>>reduce(fn, [1,3,5,7,9])
13579
14.filter方法
filter()也接收一个函数和一个序列。和map()不同的是,filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素
例如,在一个list中,删掉偶数,只保留奇数,可以这么写:
def is_odd(n):
return n %2==1
list(filter(is_odd, [1,2,4,5,6,9,10,15]))
# 结果: [1, 5, 9, 15]
15.sorted方法
将一下list按忽略大小写,反序排列:
>>>sorted(['bob','about','Zoo','Credit'], key=str.lower, reverse=True)['Zoo','Credit','bob','about']
16.使用模块
Python本身就内置了很多非常有用的模块,以内建的sys模块为例,编写一个hello的模块:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
' a test module '
__author__ = 'Michael Liao'
import sys
def test():
args = sys.argv
if len(args)==1:
print('Hello, world!')
elif len(args)==2:
print('Hello, %s!' % args[1])
else:
print('Too many arguments!')
if __name__=='__main__':
test()
第1行和第2行是标准注释,第1行注释可以让这个hello.py文件直接在Unix/Linux/Mac上运行,第2行注释表示.py文件本身使用标准UTF-8编码;
第4行是一个字符串,表示模块的文档注释,任何模块代码的第一个字符串都被视为模块的文档注释;
第6行使用__author__变量把作者写进去,这样当你公开源代码后别人就可以瞻仰你的大名;
当我们在命令行运行hello模块文件时,Python解释器把一个特殊变量__name__置为__main__,而如果在其他地方导入该hello模块时,if判断将失败,因此,这种if测试可以让一个模块通过命令行运行时执行一些额外的代码,最常见的就是运行测试。
17.面向对象编程
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
def print_score(self):
print('%s: %s' % (self.name, self.score))
使用方法:
bart = Student('Bart Simpson', 59)
lisa = Student('Lisa Simpson', 87)
bart.print_score()
lisa.print_score()
第二、编程工具
强烈推荐sublime,可以设置python shell交互和run功能。
预告:
下周开始学习TensorFlow搭建环境,并试验运行手写体识别MNIST实验(MNIST机器学习入门)。