实验目的
- 通过实验掌握基本的MapReduce编程方法。
- 掌握用MapReduce解决一些常见的数据处理问题,包括数据去重、数据排序和数据挖掘等。
- 通过操作MapReduce的实验,模仿实验内容,深入理解MapReduce的过程,熟悉MapReduce程序的编程方式。
实验平台
- 操作系统:Ubuntu-16.04
- Hadoop版本:2.6.0
- JDK版本:1.8
- IDE:Eclipse
实验内容和要求
一,编程实现文件合并和去重操作:
-
对于两个输入文件,即文件A和文件B,请编写MapReduce程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件C。下面是输入文件和输出文件的一个样例供参考。
- 输入文件f1.txt的样例如下:
20150101 x
20150102 y
20150103 x
20150104 y
20150105 z
20150106 x
- 输入文件f2.txt的样例如下:
20150101 y
20150102 y
20150103 x
20150104 z
20150105 y
- 根据输入文件f1和f2合并得到的输出文件的样例如下:
20150101 x
20150101 y
20150102 y
20150103 x
20150104 y
20150104 z
20150105 y
20150105 z
20150106 x
实验过程:
-
创建文件f1.txt和f2.txt
 将上面样例内容复制进去
将上面样例内容复制进去 -
在HDFS建立input文件夹(执行这步之前要开启hadoop相关进程)

-
上传样例到HDFS中的input文件夹

- 接着打开eclipse
Eclipse的使用-
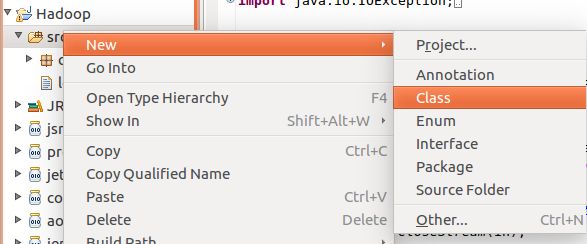
点开项目,找到 src 文件夹,右键选择 New -> Class
-
输入 Package 和 Name,然后Finish

-
写好Java代码(给的代码里要修改HDFS和本地路径),右键选择 Run As -> Run on Hadoop,结果在HDFS系统中查看

-
实验代码:
package cn.edu.zucc.mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Merge {
public static class Map extends Mapper {
private static Text text = new Text();
@Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
text = value;
context.write(text, new Text(""));
}
}
public static class Reduce extends Reducer {
@Override
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
context.write(key, new Text(""));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
String[] otherArgs = new String[]{"input", "output"};
if (otherArgs.length != 2) {
System.err.println("Usage: Merge and duplicate removal ");
System.exit(2);
}
Job job = Job.getInstance(conf, "Merge");
job.setJarByClass(Merge.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
模仿上题完成以下内容:对于两个输入文件,即文件A和文件B,请编写MapReduce程序,对两个文件进行统计单词数量,得到一个新的输出文件C。下面是输入文件和输出文件的一个样例供参考。
- 输入文件a.txt的样例如下:
hello world
wordcount java
android hbase
hive pig
- 输入文件b.txt的样例如下:
hello hadoop
spring mybatis
hive hbase
pig android
- 输出文件的结果为:
android 2
hadoop 1
hbase 2
hello 2
hive 2
java 1
mybatis 1
pig 2
spring 1
wordcount 1
world 1
实验代码:
package cn.edu.zucc.mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class Map extends Mapper {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String lineValue = value.toString();
String[] words = lineValue.split(" ");
for (String singleWord : words) {
word.set(singleWord);
context.write(word, one);
}
}
}
public static class Reduce extends Reducer {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
String[] otherArgs = new String[]{"input_1", "output_1"};
if (otherArgs.length != 2) {
System.err.println("Usage: Wordcount ");
System.exit(2);
}
Job job = Job.getInstance(conf, "Wordcount");
job.setJarByClass(WordCount.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
二,编写程序实现对输入文件的排序:
-
现在有多个输入文件,每个文件中的每行内容均为一个整数。要求读取所有文件中的整数,进行升序排序后,输出到一个新的文件中,输出的数据格式为每行两个整数,第一个数字为第二个整数的排序位次,第二个整数为原待排列的整数。下面是输入文件和输出文件的一个样例供参考。
- 输入文件file1.txt的样例如下:
33
37
12
40
- 输入文件file2.txt的样例如下:
4
16
39
5
- 输入文件file3.txt的样例如下:
1
45
25
- 根据输入文件file1.txt、file2.txt和file3.txt得到的输出文件如下:
1 1
2 4
3 5
4 12
5 16
6 25
7 33
8 37
9 39
10 40
11 45
实验过程:
-
创建文件file1.txt、file2.txt和file3.txt
 将上面样例内容复制进去
将上面样例内容复制进去 -
在HDFS建立input2文件夹

-
上传样例到HDFS中的input2文件夹

- 到eclipse上执行代码
实验代码:
package cn.edu.zucc.mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class ContentSort {
public static class Map extends Mapper {
private static IntWritable data = new IntWritable();
@Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
data.set(Integer.parseInt(line));
context.write(data, new IntWritable(1));
}
}
public static class Reduce extends Reducer {
private static IntWritable linenum = new IntWritable(1);
@Override
public void reduce(IntWritable key, Iterable values, Context context) throws IOException, InterruptedException {
for (IntWritable val : values) {
context.write(linenum, key);
linenum = new IntWritable(linenum.get() + 1);
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
String[] otherArgs = new String[]{"input2", "output2"};
if (otherArgs.length != 2) {
System.err.println("Usage: ContentSort ");
System.exit(2);
}
Job job = Job.getInstance(conf, "ContentSort");
job.setJarByClass(ContentSort.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
模仿上题完成以下内容:对于三个输入文件,即文件math、文件china和文件english,请编写MapReduce程序,对三个文件进行统计平均分,得到一个新的输出文件。下面是输入文件和输出文件的一个样例供参考。
- 输入文件math.txt的样例如下:
张三 88
李四 99
王五 66
赵六 77
- 输入文件algs.txt的样例如下:
张三 78
李四 89
王五 96
赵六 67
- 输入文件english.txt的样例如下:
张三 80
李四 82
王五 84
赵六 86
- 输出文件结果为:
张三 82
李四 90
王五 82
赵六 76
实验代码:
package cn.edu.zucc.mapreduce;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class AvgScore {
public static class Map extends Mapper {
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] nameAndScore = line.split(" ");
List list = new ArrayList<>(2);
for (String nameOrScore : nameAndScore) {
if (!"".equals(nameOrScore)) {
list.add(nameOrScore);
}
}
context.write(new Text(list.get(0)), new IntWritable(Integer.parseInt(list.get(1))));
}
}
public static class Reduce extends Reducer {
@Override
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int sum = 0;
int count = 0;
for (IntWritable value : values) {
sum += Integer.parseInt(value.toString());
count++;
}
int average = sum / count;
context.write(key, new IntWritable(average));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
String[] otherArgs = new String[]{"input_2", "output_2"};
if (otherArgs.length != 2) {
System.err.println("Usage: AvgScore ");
System.exit(2);
}
Job job = Job.getInstance(conf, "AvgScore");
job.setJarByClass(AvgScore.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
三,对给定的表格进行信息挖掘:
-
下面给出一个child-parent的表格,要求挖掘其中的父子辈关系,给出祖孙辈关系的表格。
- 输入文件table.txt内容如下:
child parent
Steven Lucy
Steven Jack
Jone Lucy
Jone Jack
Lucy Mary
Lucy Frank
Jack Alice
Jack Jesse
David Alice
David Jesse
Philip David
Philip Alma
Mark David
Mark Alma
- 输出文件内容如下:
grandchild grandparent
Mark Jesse
Mark Alice
Philip Jesse
Philip Alice
Jone Jesse
Jone Alice
Steven Jesse
Steven Alice
Steven Frank
Steven Mary
Jone Frank
Jone Mary
实验过程:
-
创建文件table
 将上面样例内容复制进去
将上面样例内容复制进去 -
在HDFS建立input3文件夹

-
上传样例到HDFS中的input3文件夹

- 到eclipse上执行代码
实验代码:
package cn.edu.zucc.mapreduce;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class STJoin {
public static int time = 0;
public static class Map extends Mapper {
@Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] childAndParent = line.split(" ");
List list = new ArrayList<>(2);
for (String childOrParent : childAndParent) {
if (!"".equals(childOrParent)) {
list.add(childOrParent);
}
}
if (!"child".equals(list.get(0))) {
String childName = list.get(0);
String parentName = list.get(1);
String relationType = "1";
context.write(new Text(parentName), new Text(relationType + "+"
+ childName + "+" + parentName));
relationType = "2";
context.write(new Text(childName), new Text(relationType + "+"
+ childName + "+" + parentName));
}
}
}
public static class Reduce extends Reducer {
@Override
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
if (time == 0) {
context.write(new Text("grand_child"), new Text("grand_parent"));
time++;
}
List grandChild = new ArrayList<>();
List grandParent = new ArrayList<>();
for (Text text : values) {
String s = text.toString();
String[] relation = s.split("\\+");
String relationType = relation[0];
String childName = relation[1];
String parentName = relation[2];
if ("1".equals(relationType)) {
grandChild.add(childName);
} else {
grandParent.add(parentName);
}
}
int grandParentNum = grandParent.size();
int grandChildNum = grandChild.size();
if (grandParentNum != 0 && grandChildNum != 0) {
for (int m = 0; m < grandChildNum; m++) {
for (int n = 0; n < grandParentNum; n++) {
context.write(new Text(grandChild.get(m)), new Text(
grandParent.get(n)));
}
}
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
String[] otherArgs = new String[]{"input3", "output3"};
if (otherArgs.length != 2) {
System.err.println("Usage: Single Table Join ");
System.exit(2);
}
Job job = Job.getInstance(conf, "Single table Join ");
job.setJarByClass(STJoin.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
模仿上题完成以下内容:现有两个输入文件两个文件,一个是工厂名与地址编号的对应关系;另一个是地址编号和地址名的对应关系。要求从输入数据中找出工厂名和地址名的对应关系,输出"工厂名——地址名"表。
- 输入文件factory.txt:
factoryname addressID
Beijing Red Star 1
Shenzhen Thunder 3
Guangzhou Honda 2
Beijing Rising 1
Guangzhou Development Bank 2
Tencent 3
Bank of Beijing 1
- 输入文件address.txt:
addressID addressname
1 Beijing
2 Guangzhou
3 Shenzhen
4 Xian
- 输出文件内容如下:
factoryname addressname
Back of Beijing Beijing
Beijing Rising Beijing
Beijing Red Star Beijing
Guangzhou Development Bank Guangzhou
Guangzhou Honda Guangzhou
Tencent Shenzhen
Shenzhen Thunder Shenzhen
实验代码:
package cn.edu.zucc.mapreduce;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class MTJoin {
public static int time = 0;
public static class Map extends Mapper {
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
if (line.contains("factoryname") || line.contains("addressID")) {
return;
}
String[] strings = line.split(" ");
List list = new ArrayList<>();
for (String information : strings) {
if (!"".equals(information)) {
list.add(information);
}
}
String addressID;
StringBuilder stringBuilder = new StringBuilder();
if (StringUtils.isNumeric(list.get(0))) {
addressID = list.get(0);
for (int i = 1; i < list.size(); i++) {
if (i != 1) {
stringBuilder.append(" ");
}
stringBuilder.append(list.get(i));
}
context.write(new Text(addressID), new Text("1+" + stringBuilder.toString()));
} else {
addressID = list.get(list.size() - 1);
for (int i = 0; i < list.size() - 1; i++) {
if (i != 0) {
stringBuilder.append(" ");
}
stringBuilder.append(list.get(i));
}
context.write(new Text(addressID), new Text("2+" + stringBuilder.toString()));
}
}
}
public static class Reduce extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
if (time == 0) {
context.write(new Text("factoryname"), new Text("addressname"));
time++;
}
List factory = new ArrayList<>();
List address = new ArrayList<>();
for (Text text : values) {
String s = text.toString();
String[] relation = s.split("\\+");
if ("1".equals(relation[0])) {
address.add(relation[1]);
} else {
factory.add(relation[1]);
}
}
int factoryNum = factory.size();
int addressNum = address.size();
if (factoryNum != 0 && addressNum != 0) {
for (int m = 0; m < factoryNum; m++) {
for (int n = 0; n < addressNum; n++) {
context.write(new Text(factory.get(m)),
new Text(address.get(n)));
}
}
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
String[] ioArgs = new String[]{"input_3", "output_3"};
String[] otherArgs = new GenericOptionsParser(conf, ioArgs)
.getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: Multiple Table Join ");
System.exit(2);
}
Job job = Job.getInstance(conf, "Mutiple table join ");
job.setJarByClass(MTJoin.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}