目标反射回波检测算法及其FPGA实现之二:
互相关/卷积/FIR电路的实现
前段时间,接触了一个声呐目标反射回波检测的项目。声呐接收机要实现的核心功能是在含有大量噪声的反射回波中,识别出发射机发出的激励信号的回波。我会分几篇文章分享这个基于FPGA的回波识别算法的开发过程和原码,欢迎大家不吝赐教。以下原创内容欢迎网友转载,但请注明出处: https://www.cnblogs.com/helesheng。
在本系列博文的第一篇中,根据仿真结果,我认为采用“反射回波和激励信号互相关”来计算目标距离的算法具有较高性能和计算效率。作为系列文章的第二篇,本文将介绍算法的核心功能——互相关的FPGA实现方法。本文会以数据结构的实现方式为主线,综合考虑电路的计算实时性、灵活性和成本效率等方面问题。
要实现的互相关运算在连续域的描述方式为:
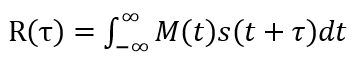 (1)
(1)
其中M(t)为激励信号,s(t)为反射回波信号。在FPGA中实现上式时必须将其离散化,并限制在有限的时间长度内。好在激励信号M(t)本来就是有限时长的,对其实施一个满足奈奎斯特采样定理的离散化后【注:作为算法的验证,我们在预备篇中使用了采样率仅为50KSPS的ADC:MCP3202,但这并不妨碍我们验证算法的正确性。实际的声呐系统中采样率可能远超过50KSPS】,可以将上式简化为FPGA能够实现的形式:
![]()
其中N为激励信号的长度(采样点数)。
一望便知,上式是数字信号处理的典型计算——乘加(MAC)运算的组合。将激励信号M[t]镜像翻转:

就可以将(2)式变为我们熟悉的卷积算法:
![]()
当上式中的h[k[视为系统的冲击响应时,上式还可以理解为更为常见的FIR滤波算法。
由于激励信号一般具有镜像对称性(或称左右对称),即(3)式中翻转前的M[k]和h[k]和完全相同。为了使设计的FPGA电路具有更好的通用性,接下来不妨直接讨论卷积/FIR滤波运算(4)式的实现方式。
一、总体电路结构
中高端FPGA一般集成了硬件MAC电路,如Xilinx公司的DSP48E模块和Altera(Intel)公司的Embedded multipliers模块。这些MAC模块不需要占用FPGA中的通用可编程资源,工作频率可高达大几百MHz,且大大降低开发难度。但声呐系统的采样率一般不会超过10MHz,为了使本算法能够在高、中、低档的各类FPGA上兼容,我选择通过EDA工具提供的MAC的IP核实现算法。验证算法使用的是,不具备硬件MAC模块的,常见低成本FPGA:Cyclone-I系列。
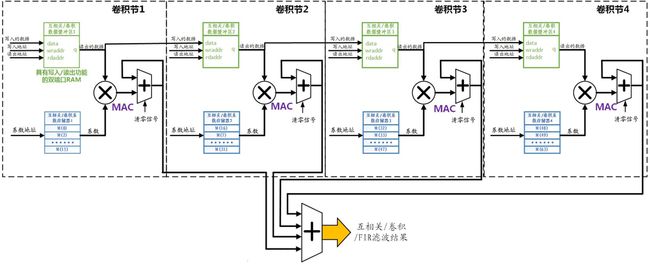
为保证算法的实时性,必须在一个A/D采样周期内实现(4)式中的N个点的乘加运算。最直接的方式是在FPGA中实现N个乘加器,全并行的完成(4)式的计算。但这样做将耗费大量的FPGA资源(Cyclone-I中,每个16*16bits的乘加器约需500个LE资源),且当N确定后电路结构就固定了,不太容易修改。为使设计的电路更具“通用性”和“灵活性”,以兼容更多的激励信号长度N值,我才用下图所示的“半并行”结构实现(4)式的卷积算法。
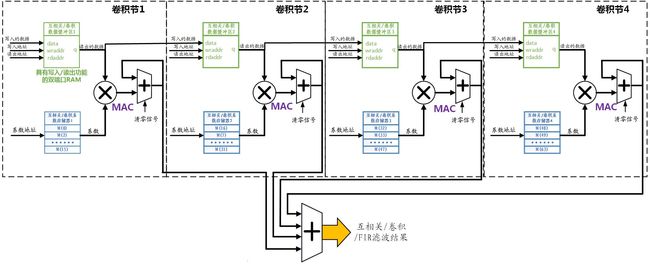
图1 半并行结构的互相关/卷积/FIR滤波器结构
这相当于将一段长度为N公里的“公路工程”,平均分配给L个“工程队”来实施。在每个工程队同时工作,且效率相同的前提下,工程耗时将降低为原来的1/L;当然L个工程队所需的“工资”也变为原来的L倍。实际使用时,可以根据总工程量N和FPGA的资源情况,灵活的调整L,从而在实时性和电路规模之间取得平衡。以下为方便讨论,且不失一般性,将以N=64,L=4为例讨论。
设计时虽然可以利用Verilog-HDL的泛化能力,将相同的功能模块例化为4个结构相同的“工程队”,以下简称为“卷积节”。在设计功能模块时,必须考虑输入数据s[k]和卷积模板h[k]存储的数据结构。必须满足以下要求:
1、在单个R[n]的计算中,每个卷积节需要遍历数据缓冲区中的所有s[k[数据,以及系数存储器中的所有卷积系数h[k]。
2、在完成一个R[n]的计算后,每个卷积节需要接收前一个卷积节或A/D采样得到的新缓冲数据,同时将缓冲中“最老”的数据传递给下一个卷积节。
我设计了图1所示“双存储器”结构实现上述两条数据结构功能,其物理载体都是Cyclone系列中的M4K存储块(M4K RAM blocks)。图中绿色部分是存储输入数据s[k]的缓冲区,是“简单双端口RAM”。它有两个数据端口:一个负责向缓冲区存入新数据,每个A/D采样周期存入一次;另一个负责读取乘加运算所需的数据,每个A/D采样周期读取16次(即N/L次)。其存取采用“环形队列”数据结构。图中蓝色部分是卷积系数h[k]的存储器,它每个A/D采样周期读取16次,数据不更新。
另外,当互相关/卷积的模板具备对称性时,也就是对应的FIR滤波器具有线性相位的情况下,图1所示的算法电路还能进一步简化,计算量降低为N/2次乘加MAC运算,这里就不讨论了。
二、卷积节控制电路的设计
通过上文的描述,相信读者可以感觉得到:整个卷积电路的重点在每个卷积节的实现,而卷积节实现的关键是能够正确的控制“数据缓冲区”、“系数存储器”和“乘加器(MAC)”的协调工作。其工作内容是在每个A/D采样结果到来,而下一个结果未到之前,完成:
1、产生一个写地址,将A/D结果存入缓冲区最老数据所在位置,同时将最老的数据输出给下一个卷积节;
2、同步产生两组、各16个读地址,分别从数据缓冲区和系数存储器读取一遍其中的所有数据;
3、将顺序读取的两组数据顺序乘加在一起。
实现上述功能的电路Verilog-HDL实现如下:
1 module conv_ctlr(rst_n,clk,start,coe_rom_addr,rd_data_dpram_addr,acc_clr,wren,wr_data_dpram_addr,flag,mac_en); 2 //卷积控制信号产生电路模块 3 //可以控制一个MAC电路,分多个时钟周期,实现多个数值的相加。 4 //这里实现的是控制16级卷积的功能 5 input rst_n;//低电平复位信号,可以复位首地址指针 6 input clk;//工作时钟信号 7 input start;//启动一次控制逻辑输出的启动信号,下降启动一轮操作 8 output[3:0] coe_rom_addr;//参与卷积的固定信号rom地址信号 9 output[3:0] rd_data_dpram_addr;//读取双口RAM缓冲中数据的地址信号 10 output acc_clr; //累加器清零信号,高电平用于清除MAC电路的结果,准备下一次卷积计算 11 output wren; //写使能信号,每个start周期向下一个DPRAM的缓冲(本级的缓冲区也可以使用这个写入信号)里写入一个新数据的使能信号 12 output[3:0] wr_data_dpram_addr;//写入DPRAM缓冲区的新数据的地址线 13 output flag;//标志信号,表示卷积电路在工作 14 output mac_en;//乘加器的使能信号,为1时每个上升沿执行乘加 15 wire flag;//状态标志,为1时表示正在进行卷积操作,否则表示没有操作 16 reg[9:0] flag_cnt;//状态计数器,start信号到来后还是计数,当其大于一定值后切换标志 17 reg[3:0] current_pt;//当前位置指针,会在每次start到来卷积后加一,以指向下一次数据缓冲器的首地址 18 assign acc_clr = start; 19 assign mac_en = ((flag_cnt[9:0]>=10'd3)&(flag_cnt[9:0]<=10'd20))? 1'b1 : 1'b0;//只有当flag_cnt等于3时系数和dpram才能读出所需的数据,注意读锁存器造成的一个周期的延迟。 20 ///////向后续卷积节传递最老的一个数据的控制信号 21 assign wren = (flag_cnt[9:0] == 10'd20)? 1'b1 : 1'b0;//这里要看仿真时序图才能明白,flag_cnt=20的周期刚好读出本轮以后不再使用的数据 22 assign wr_data_dpram_addr[3:0] = current_pt[3:0]; 23 always @ (posedge start or negedge rst_n) 24 begin 25 if(!rst_n) 26 current_pt[3:0] <= 4'b1111;//复位后为最大值,第一个start脉冲使其从0开始 27 else 28 current_pt[3:0] <= current_pt[3:0] + 4'd1;//首地址缓冲器,会在每次采样(或start)信号到来后加一,为下次输入新数据移动缓冲器做好准备 29 end 30 assign flag = ((flag_cnt[9:0]>=10'd2)&(flag_cnt[9:0]<=10'd20))? 1'b1 : 1'b0; 31 always @ (negedge clk or posedge start)//注意为了让flag从clk下降沿开始,以上升沿为每个周期的中心,这里用用flag的下降沿计数 32 begin 33 if(start) 34 begin 35 flag_cnt[9:0] <= 10'd0; 36 end 37 else begin 38 if(flag_cnt[9:0] <= (10'd16 + 10'd1 + 10'd3)) 39 //计到15再加1,则一共1-16个脉冲;加1是为了留出第一个时钟周期作为dpram的地址潜伏期;加2是为了等待乘法器的潜伏期(潜伏期为3,但最后一个不用乘加) 40 begin 41 flag_cnt[9:0] <= flag_cnt[9:0] +1'd1; 42 end 43 else 44 begin 45 flag_cnt[9:0] <= flag_cnt[9:0]; 46 end 47 end 48 end 49 pset_addr_cnt i_rd_addr_cnt(//例化读缓冲当前地址计数器 50 .rst_n(rst_n), 51 .load(!flag),//每产生一个启动信号,就要重新对首地址置新值 52 .clk(clk), 53 .pre_value(current_pt), 54 .addr_cnt(rd_data_dpram_addr) 55 ); 56 addr_cnt i_coe_rom_addr_cnt(//例化系数地址产生计数器 57 .en(flag), 58 .clk(clk), 59 .addr_cnt(coe_rom_addr) 60 ); 61 endmodule 62 63 module addr_cnt(en,clk,addr_cnt); 64 //本模块产生4位计数值,作为地址产生器 65 input en;//高电平有效 66 input clk; 67 output[3:0] addr_cnt; 68 reg[3:0] addr_cnt; 69 always @ (negedge clk or negedge en)//为了使地址再时钟下降沿产生,上升沿位于数据中央,clk使用了下降沿 70 begin 71 if(!en) 72 addr_cnt[3:0] <= 4'd0; 73 else 74 addr_cnt[3:0] <= addr_cnt[3:0] + 4'd1; 75 end 76 endmodule 77 78 //带预置功能的地址计数器,4位 79 module pset_addr_cnt(rst_n,load,clk,pre_value,addr_cnt); 80 input rst_n; 81 input load;//load高电平时同步加载初值 82 input clk; 83 input[3:0] pre_value;//输入的预置初值 84 output[3:0] addr_cnt;//计数输出 85 reg[3:0] addr_cnt; 86 always @(negedge clk or negedge rst_n)//为了使地址再时钟下降沿产生,上升沿位于数据中央,clk使用了下降沿 87 begin 88 if(!rst_n) 89 addr_cnt[3:0] <= 4'd0;//pre_value[3:0]; 90 else begin 91 if(load == 1'b1) 92 addr_cnt[3:0] <= pre_value[3:0]; 93 else 94 addr_cnt[3:0] <= addr_cnt[3:0] + 4'd1; 95 end 96 end 97 endmodule
上述代码中,需要特别注意的是数据缓冲区“当前地址寄存器”current_pt[3:0],它会在每个采样点的计算卷积运算开始之前,在启动信号start驱动下自动加一,随后current_pt[3:0]作为初值加载给数据缓冲区读地址寄存器/计数器“rd_data_dpram_addr”,从而起到了修正环形队列首地址的目的。这一操作保证了数据缓冲区的首地址指针总是指向环形队列数据结构中最新的数据。
另外,写使能信号wren是每个卷积节向后级的卷积节输出的控制信号——它在数据缓冲区读出最老数据的同时,使能后级卷积节数据缓冲区的写入功能,从而将前级卷积节中数据缓冲中最老数据作为最新信号存入后级卷积节数据缓冲区。
三、卷积节中的两个存储以及乘加电路的实现
正如我在本文第一部分“总体电路结构”中介绍的,每个卷积节中含有两个有M4K块实现的存储块:绿色部分是存储输入数据s[k]的缓冲区,和蓝色部分的卷积系数h[k]的存储器。分别采用Quartus-II中的MegaWizard实现,其结构如下图所示。

图2 双端口数据缓冲区的结构示意图
数据宽度为16位,是由ADC的位数12bits决定的。地址宽度为4位则是由16(即N/L的值)决定的。值得注意点是该双口RAM的输入和输出端各有一级D触发器构成的缓冲器,在规划控制时序时需要注意它们造成的数据潜伏期的增加。
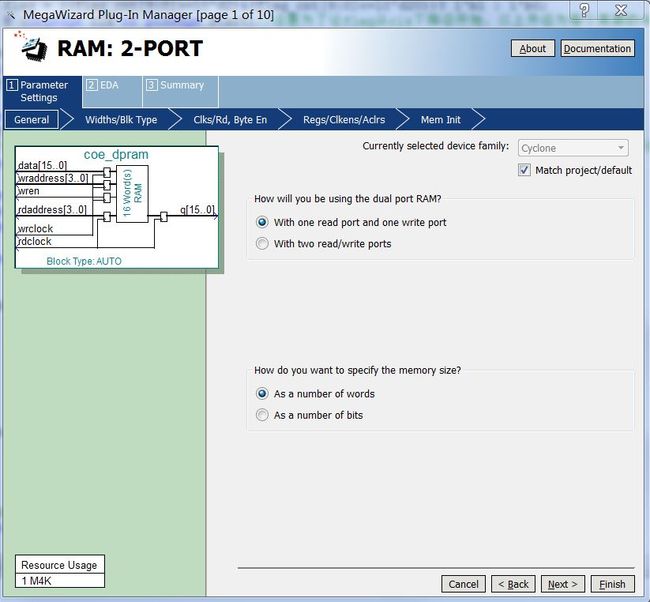
图3 系数存储器的结构示意图
系数存储器只要设计为单口ROM即可满足需要,但为了使系数的初始化更加方便,我将它设计为双口RAM结构。这将允许系统在FPGA上电后,执行一个系数存储器初始化过程,以将系数从双口RAM的写入端口分时写入各个卷积节中。系数初始化的过程和电路设计将在本博文的后面详述。
每个卷积节中的乘加器,将在两次采样间隔间实现16(即N/L的值)次MAC操作,采用MageWizard实现的MAC结构如下所示。
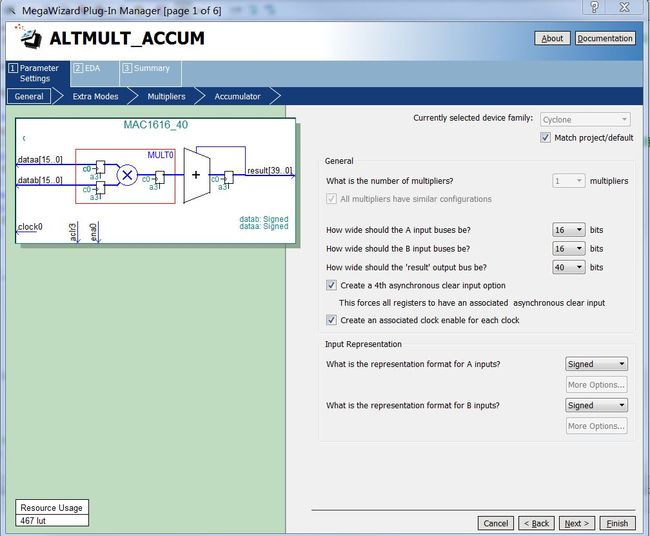
图4 乘加器结构示意图
为防止溢出,乘加器模块输出宽度取了40bits,实际上每个卷积节只执行16次乘加,只需36bits就可以保证不溢出。
四、卷积节的顶层连接
为了将上述卷积节控制电路、数据缓冲器、系数存储器和乘加器连接为图1中的一个完整卷积节,还需要一个顶层设计文件如下。
1 module CONV_SER16(clk,a,en,coe_data_in16,wr_coe_addr,wr_coe_clk,wr_coe_en,start,shft_out_dp_data,s_latch); 2 //本模块例化了一个乘加模块,采用串行方式实现16阶卷积/FIR运算, 3 //由start信号启动,持续时间约为20个clk周期。a为不断送入的被卷积数据流信号,s为卷积后输出的数据流,这两个流信号都被start同步 4 //在启动之前需要由系数配置模块向本节系数存储器配置系数,配置完成后通过en和start启动本模块滤波 5 input clk;//外部送入的100M左右时钟 6 input[15:0] a;//输入数据 7 input en;//高电平使能,由系数初始化模块控制,初始化完成后使能所有计算模块 8 input[15:0] coe_data_in16;//从本模块以外写入的配置系数 9 input[3:0] wr_coe_addr;//从本模块以外写入的配置系数地址 10 input wr_coe_clk;//从本模块以外输入的系数配置时钟 11 input wr_coe_en;//从本模块以外输入的系数配置使能端 12 input start; 13 output[39:0] s_latch;//经过锁存的卷积/FIR结果数据 14 output[15:0] shft_out_dp_data;//从DPRAM中读取的数,在本模块中参与MAC,同时输出给下一个卷积节作为输入 15 wire[39:0] s; 16 wire[3:0] coe_rom_addr;//参与卷积的固定信号rom地址信号 17 wire[3:0] rd_data_dpram_addr;//读取双口RAM缓冲中数据的地址信号 18 wire[3:0] wr_data_dpram_addr;//写入DPROM缓冲的地址信号 19 wire[15:0] coe_value;//读取系数值的连线 20 wire[15:0] dp_rd_data;//从DPRAM中读取的准备参与乘加的被卷积数 21 wire acc_clr; //累加器清零信号,高电平用于清除MAC电路的结果,准备下一次卷积计算 22 wire flag; //标志信号,表示卷积电路在工作 23 wire wren; //DPROM缓冲写使能,高电平使能 24 wire clk;//100M时钟 25 wire mac_en;//乘加器使能信号 26 assign shft_out_dp_data[15:0] = dp_rd_data[15:0];//从DPRAM中读取的数,在本模块中参与MAC,同时输出给下一个卷积节作为输入 27 28 conv_ctlr i_conv_ctlr( 29 .rst_n(en),//低电平复位信号,可以复位首地址指针 30 .clk(clk),//工作时钟信号 31 .start(start),//启动一次控制逻辑输出的启动信号,下降启动一轮操作 32 .coe_rom_addr(coe_rom_addr),//参与卷积的固定信号rom地址信号 33 .rd_data_dpram_addr(rd_data_dpram_addr),//读取双口RAM缓冲中数据的地址信号 34 .acc_clr(acc_clr), //累加器清零信号,高电平用于清除MAC电路的结果,准备下一次卷积计算 35 .wren(wren), //写使能信号,每个start周期向DPRAM的缓冲里写入一个新数据的使能信号 36 .wr_data_dpram_addr(wr_data_dpram_addr),//写入DPRAM缓冲区的新数据的地址线 37 .flag(flag),//标志信号,表示卷积电路在工作 38 .mac_en(mac_en) 39 ); 40 MAC1616_40 i_mac(//例化乘加模块 41 .aclr3(acc_clr), 42 .clock0(!clk),//让乘加发生在flag为高电平阶段的clk的下降沿,因为读出数值发生在上升沿 43 .dataa(dp_rd_data), 44 .datab(coe_value), 45 .ena0(mac_en),//乘加使能信号 46 .result(s) 47 ); 48 DUAL_PORT_BUFF i_dpram_buff(//例化存储缓冲区的PDRAOM 49 .data(a),//输入数据 50 .inclock(clk), 51 .outclock(clk), 52 .rdaddress(rd_data_dpram_addr), 53 .wraddress(wr_data_dpram_addr), 54 .wren(wren), 55 .q(dp_rd_data) 56 ); 57 coe_dpram i_coe_dpram (//例化每一节的系数dpram,它负责在复位后接收系数池中初始化的数据 58 //这个例化对象的写入侧外接,用初始化器写入数据,读出端接在本模块中,负责向乘加器输出系数 59 .data ( coe_data_in16 ),//从本模块外部写入系数的写入端 60 .rdaddress ( coe_rom_addr ),//本模块自己产生的读系数地址 61 .rdclock ( clk & flag ),//本模块自己的读时钟 62 .wraddress ( wr_coe_addr ),//外部配置模块产生的写入地址 63 .wrclock ( wr_coe_clk ),//外部配置模块产生的写系数时钟 64 .wren ( wr_coe_en ),//外部配置模块产生的写使能,由配置模块的高地址译码产生 65 .q ( coe_value )//本模块读取的系数值 66 ); 67 latch_40 i_latch_40(//例化40位锁存器,用以使计算结果在整个周期内保持不变 68 .din(s), 69 .dout(s_latch), 70 .clk(start) 71 ); 72 endmodule
由于代码中由详细注释,这里就不再一一解释了。
五、系数初始化器的设计
完成卷积节的设计后,可以将其例化为L个卷积节,并通过逐一级联它们来实现更高阶的卷积/互相关/FIR滤波功能。但我发现一个很不方便的地方:例化产生的所有实例的系数存储器具有相通的内容,无法分别赋值。苦恼多时之后,终于一咬牙决定再写一个系数初始化模块来实现系数的初始化。这也就有了前面所说的,将每个卷积节中的系数存储器配置为可写入的双口RAM的事情。如果有朋友有更好的办法解决这个问题烦请告知,欢迎交流。
系数初始化模块由控制逻辑、系数池ROM和译码电路三部分组成。其中系数池ROM负责存储所有的卷积/互相关模板h[k]或M[k]系数,FPGA上电后,控制逻辑部分会先阻止卷积部分电路的工作,先进行系数配置。系数配置时,控制电路会从系数池ROM中依次读出每个卷积节所需的系数,并在译码电路的控制下将其写入每个卷积节中的系数存储器中(双口RAM,结构如图3所示)。系数初始化模块的Verilog-HDL代码如下所示。
1 module init_coe_blk(clk,rst_n,ready,wr_blk_addr,data_bank,csh0,csh1,csh2,csh3);//,rd_blk_add2,blk_data2); 2 input clk; 3 input rst_n;//总的复位信号 4 output ready;//配置完成信号,高电平表示配置完成 5 output[7:0] wr_blk_addr;//系数blk的地址,比cnt_bank_addr延迟了一个时钟周期 6 output[15:0] data_bank;//从系数池读出的数据 7 output csh0,csh1,csh2,csh3;//用高电平选同各个系数blk 8 wire[7:0] cnt_bank_addr;//系数池地址 9 coe_init_addr i_coe_init_addr(//例化地址生成模块 10 .rst_n(rst_n), 11 .clk(clk), 12 .ready(ready), 13 .cnt_bank_addr(cnt_bank_addr),//给系数池的地址 14 .wr_blk_addr(wr_blk_addr)//给系数blk的地址,比cnt_bank_addr晚一个时钟。原因是系数池ROM有一个周期的读出延迟 15 ); 16 encode i_encode(//例化地址译码模块 17 .encode_adder(wr_blk_addr),//被译码的地址是经过延迟的地址,因为这个译码是为写入进行译码 18 .csh0(csh0), 19 .csh1(csh1), 20 .csh2(csh2), 21 .csh3(csh3) 22 ); 23 coe_bank_rom i_coe_bank_rom (//例化输出数据配置数据的rom bank 24 .address ( cnt_bank_addr ),//由计数器产生的地址 25 .clken ( rst_n ), 26 .clock ( clk ),//时钟 27 .q ( data_bank )//系数池读出的数据 28 ); 29 endmodule 30 31 module coe_init_addr(rst_n,clk,ready,cnt_bank_addr,wr_blk_addr); 32 input rst_n,clk; 33 output ready;//配置完成信号 34 output[7:0] cnt_bank_addr;//读系数池的地址信号 35 output[7:0] wr_blk_addr;//向被配置系数blk发送的地址信号,由于系数池有读出延迟,wr_blk_addr比cnt_bank_addr要多延迟一个周期,由级联的D触发器实现 36 reg ready; 37 reg[9:0] cnt_bank_addr10;//10位的计数器,其实只需要第8位,多余的位为更大的系数池预留的 38 reg[7:0] wr_blk_addr; 39 assign cnt_bank_addr[7:0] = cnt_bank_addr10[7:0]; 40 always @ (posedge clk or negedge rst_n) 41 begin 42 if(!rst_n) 43 begin 44 cnt_bank_addr10[9:0] <= 10'd0; 45 ready <= 1'b0; 46 end 47 else begin 48 if(cnt_bank_addr10[9:0] < 10'hff) 49 begin 50 cnt_bank_addr10[9:0] <= cnt_bank_addr10[9:0] + 10'd1; 51 ready <= 1'b0; 52 end 53 else begin 54 cnt_bank_addr10[9:0] <= cnt_bank_addr10[9:0]; 55 ready <= 1'b1; 56 end 57 end 58 end 59 //加一级D触发器,对地址延迟一个时钟周期,以对消系数池读取的延迟 60 always @ (posedge clk or negedge rst_n) 61 if(!rst_n) 62 begin 63 wr_blk_addr[7:0] <= 8'd0; 64 end 65 else begin 66 wr_blk_addr[7:0] <= cnt_bank_addr[7:0]; 67 end 68 endmodule 69 module encode(encode_adder,csh0,csh1,csh2,csh3);//地址译码模块,用于产生每个coe模块所需的片选信号,注意可以增加译码结果片选信号 70 input[7:0] encode_adder;//被译码地址,有8位,高4位参与译码 71 output csh0,csh1,csh2,csh3;//片选信号,注意,是高电平有效。 72 assign csh0=(encode_adder[7:4] == 4'd0)? 1'b1:1'b0; 73 assign csh1=(encode_adder[7:4] == 4'd1)? 1'b1:1'b0; 74 assign csh2=(encode_adder[7:4] == 4'd2)? 1'b1:1'b0; 75 assign csh3=(encode_adder[7:4] == 4'd3)? 1'b1:1'b0; 76 endmodule
系数池ROM就是一个简单的单端口ROM,其结构如下图所示。
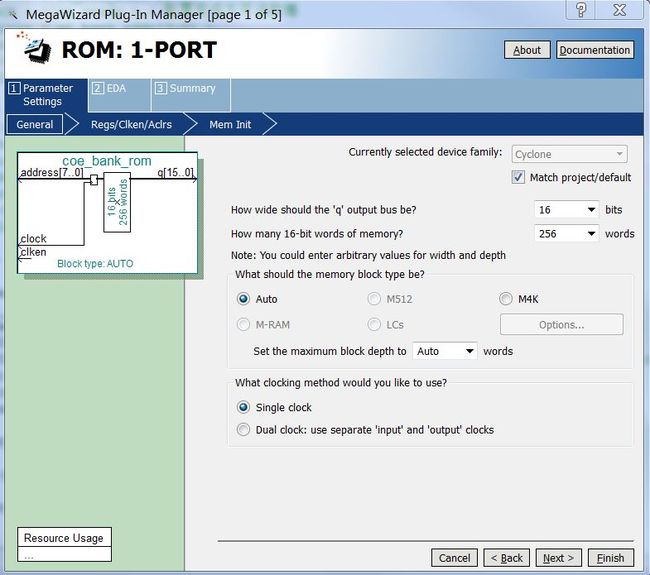
图5 系数池ROM的结构示意图
其大小为256个字,但由于N为64,我只是用了系数池ROM的1/4。
六、各卷积节求和电路的设计
如图1所示,还需要对L个卷积节的结果求和,才能得到半并行式互相关/卷积/FIR滤波器的最终结果。使用Quartus-II的MegaWizard调用PARALLEL_ADD这个IP,能实现最终求和。其结构如下图所示。
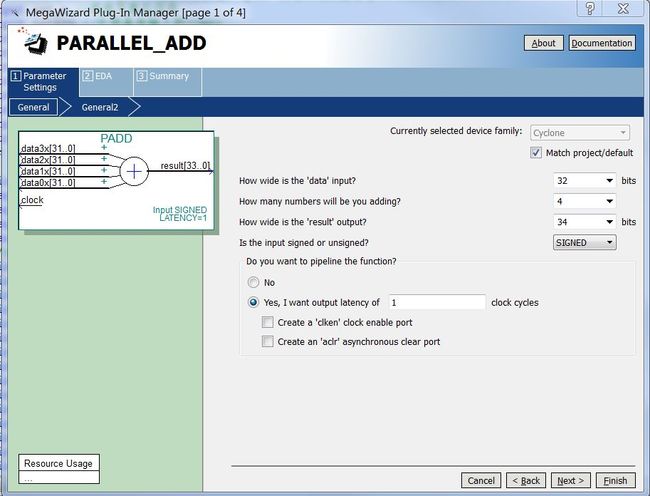
图6 并行加法器结构示意图
关于回波检测中功率(平方)计算、历史数据积分等算法在FPGA中的实际实现,请关注后续博文【目标反射回波检测算法及其FPGA实现之三:平方、积分电路及算法的顶层实现】。
关于目标回波检测算法原理和设计论证过程,请参看本人的上一篇博文【 目标反射回波检测算法及其FPGA实现 之一:算法概述 】。