简介:SOFARegistry 是蚂蚁金服开源的具有承载海量服务注册和订阅能力的、高可用的服务注册中心,最早源自于淘宝的初版 ConfigServer,在支付宝/蚂蚁金服的业务发展驱动下,近十年间已经演进至第五代。
SOFAStack
ScalableOpenFinancialArchitecture Stack 是蚂蚁金服自主研发的金融级分布式架构,包含了构建金融级云原生架构所需的各个组件,是在金融场景里锤炼出来的最佳实践。
SOFARegistry 是蚂蚁金服开源的具有承载海量服务注册和订阅能力的、高可用的服务注册中心,最早源自于淘宝的初版 ConfigServer,在支付宝/蚂蚁金服的业务发展驱动下,近十年间已经演进至第五代。
GitHub 地址:https://github.com/sofastack/sofa-registry
3 月 31 日,蚂蚁金服正式开源了内部演进了近 10 年的注册中心产品-SOFARegistry。先前的文章介绍了 SOFARegistry 的演进之路,而本文主要对 SOFARegistry 整体架构设计进行剖析,并着重介绍一些关键的设计特点,期望能帮助读者对 SOFARegistry 有更直接的认识。
服务注册中心是什么
不可免俗地,先介绍一下服务注册中心的概念。对此概念已经了解的读者,可选择跳过本节。
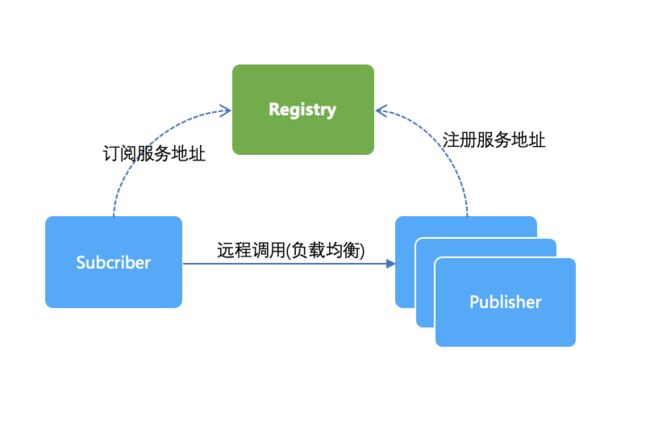
如上图,服务注册中心最常见的应用场景是用于 RPC 调用的服务寻址,在 RPC 远程过程调用中,存在 2 个角色,一个服务发布者(Publisher)、另一个是服务订阅者(Subscriber)。Publisher 需要把服务注册到服务注册中心(Registry),发布的内容通常是该 Publisher 的 IP 地址、端口、调用方式 (协议、序列化方式)等。而 Subscriber 在第一次调用服务时,会通过 Registry 找到相应的服务的 IP 地址列表,通过负载均衡算法从 IP 列表中取一个服务提供者的服务器调用服务。同时 Subscriber 会将 Publisher 的服务列表数据缓存到本地,供后续使用。当 Subscriber 后续再调用 Publisher 时,优先使用缓存的地址列表,不需要再去请求Registry。
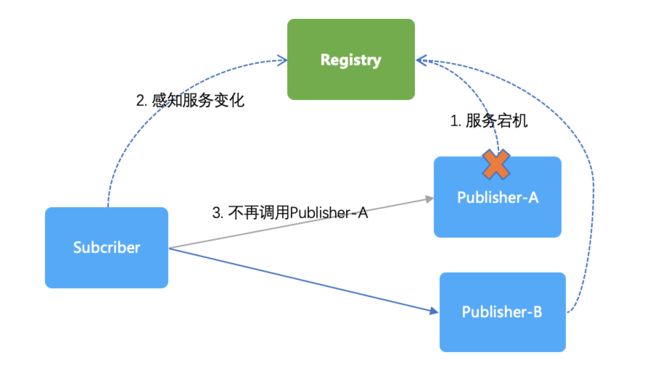
如上图,Subscriber 还需要能感知到 Publisher 的动态变化。比如当有 Publisher 服务下线时, Registry 会将其摘除,随后 Subscriber 感知到新的服务地址列表后,不会再调用该已下线的 Publisher。同理,当有新的 Publisher 上线时,Subscriber 也会感知到这个新的 Publisher。
初步认识
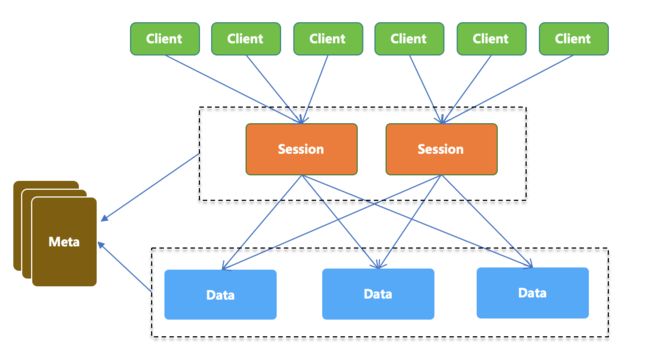
在理解了常见的服务注册中心的概念之后,我们来看看蚂蚁金服的 SOFARegistry 长什么样子。如上图,SOFARegistry 包含 4 个角色:
Client
提供应用接入服务注册中心的基本 API 能力,应用系统通过依赖客户端 JAR 包,通过编程方式调用服务注册中心的服务订阅和服务发布能力。
SessionServer
会话服务器,负责接受 Client 的服务发布和服务订阅请求,并作为一个中间层将写操作转发 DataServer 层。SessionServer 这一层可随业务机器数的规模的增长而扩容。
DataServer
数据服务器,负责存储具体的服务数据,数据按 dataInfoId 进行一致性 Hash 分片存储,支持多副本备份,保证数据高可用。这一层可随服务数据量的规模的增长而扩容。
MetaServer
元数据服务器,负责维护集群 SessionServer 和 DataServer 的一致列表,作为 SOFARegistry 集群内部的地址发现服务,在 SessionServer 或 DataServer 节点变更时可以通知到整个集群。
产品特点
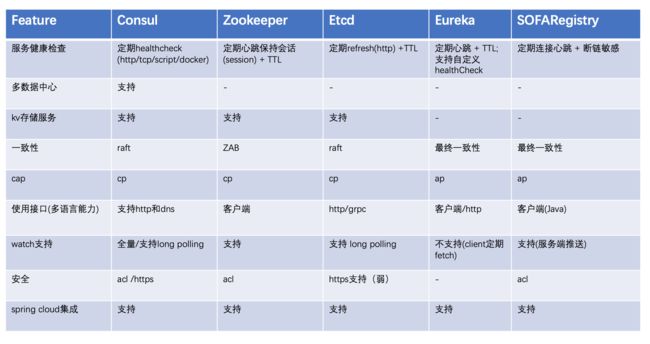
(图片改编自https://luyiisme.github.io/2017/04/22/spring-cloud-service-discovery-products)
首先放一张常见的服务注册中心的特性对比,可以看出,在这些 Feature 方面,SOFARegistry 并不占任何优势。那么,我们为什么还开源这样的一个系统?SOFARegistry 开源的优势是什么?下面将着重介绍 SOFARegistry 的特点。
支持海量数据
大部分的服务注册中心系统,每台服务器都是存储着全量的服务注册数据,服务器之间依靠一致性协议(如 Paxos/Raft/2PC 等)实现数据的复制,或者只保证最终一致性的异步数据复制。“每台服务器都存储着全量的服务注册数据”,在一般规模下是没问题的。但是在蚂蚁金服庞大的业务规模下,服务注册的数据总量早就超过了单台服务器的容量瓶颈。
SOFARegistry 基于一致性 Hash 做了数据分片,每台 DataServer 只存储一部分的分片数据,随数据规模的增长,只要扩容 DataServer 服务器即可。这是相对服务发现领域的其他竞品来说最大的特点,详细介绍见后面《如何支持海量数据》一节。
支持海量客户端
SOFARegistry 集群内部使用分层的架构,分别为连接会话层(SessionServer)和数据存储层(DataServer)。SessionServer 功能很纯粹,只负责跟 Client 打交道,SessionServer 之间没有任何通信或数据复制,所以随着业务规模(即 Client 数量)的增长,SessionServer 可以很轻量地扩容,不会对集群造成额外负担。
相比之下,其他大多数的服务发现组件,如 eureka,每台服务器都存储着全量的数据,依靠 eurekaServer 之间的数据复制来传播到整个集群,所以每扩容 1 台 eurekaServer,集群内部相互复制的数据量就会增多一份。再如 Zookeeper 和 Etcd 等强一致性的系统,它们的复制协议(Zab/Raft)要求所有写操作被复制到大多数服务器后才能返回成功,那么增加服务器还会影响写操作的效率。
秒级的服务上下线通知
对于服务的上下线变化,SOFARegistry 使用推送机制,快速地实现端到端的传达。详细介绍见后面《秒级服务上下线通知》一节。
接下来,我将围绕这些特点,讲解 SOFARegistry 的关键架构设计原理。
高可用
各个角色都有 failover 机制:
MetaServer 集群部署,内部基于 Raft 协议选举和复制,只要不超过 1/2 节点宕机,就可以对外服务。
DataServer 集群部署,基于一致性 Hash 承担不同的数据分片,数据分片拥有多个副本,一个主副本和多个备副本。如果 DataServer 宕机,MetaServer 能感知,并通知所有 DataServer 和 SessionServer,数据分片可 failover 到其他副本,同时 DataServer 集群内部会进行分片数据的迁移。
SessionServer 集群部署,任何一台 SessionServer 宕机时 Client 会自动 failover 到其他 SessionServer,并且 Client 会拿到最新的 SessionServer 列表,后续不会再连接这台宕机的 SessionServer。
数据模型
模型介绍
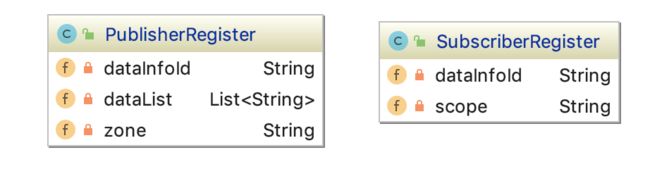
注意:这里只列出核心的模型和字段,实际的代码中不止这些字段,但对于读者来说,只要理解上述模型即可。
服务发布模型(PublisherRegister)
dataInfoId:服务唯一标识,由、<分组 group>和<租户 instanceId>构成,例如在 SOFARPC 的场景下,一个 dataInfoId 通常是 _com.sofastack.sofa.rpc.example.HelloService#@#SOFA#@#00001_,其中SOFA 是 group 名称,00001 是租户 id。group 和 instance 主要是方便对服务数据做逻辑上的切分,使不同 group 和 instance 的服务数据在逻辑上完全独立。模型里有 group 和 instanceId 字段,但这里不额外列出来,读者只要理解 dataInfoId 的含义即可。
zone:是一种单元化架构下的概念,代表一个机房内的逻辑单元,通常一个物理机房(Datacenter)包含多个逻辑单元(zone),更多内容可参考异地多活单元化架构解决方案。在服务发现场景下,发布服务时需指定逻辑单元(zone),而订阅服务者可以订阅逻辑单元(zone)维度的服务数据,也可以订阅物理机房(datacenter)维度的服务数据,即订阅该 datacenter 下的所有 zone 的服务数据。
dataList:服务注册数据,通常包含“协议”、“地址”和“额外的配置参数”,例如 SOFARPC 所发布的数据类似“_bolt://192.168.1.100:8080?timeout=2000_”。这里使用 dataList,表示一个 PublisherRegister 可以允许同时发布多个服务数据(但是通常我们只会发布一个)。
服务订阅模型(SubscriberRegister)
dataInfoId:服务唯一标识,上面已经解释过了。
scope: 订阅维度,共有 3 种订阅维度:zone、dataCenter 和 global。zone 和 datacenter 的意义,在上述有关“zone”的介绍里已经解释。global 维度涉及到机房间数据同步的特性,目前暂未开源。
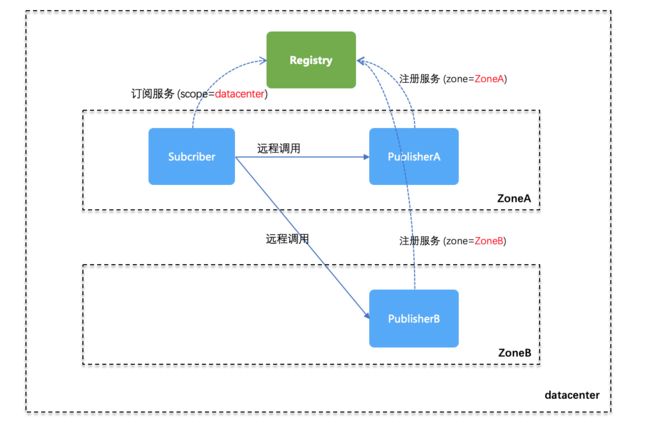
关于“zone”和“scope”的概念理解,这里再举个例子。如下图所示,物理机房内有 ZoneA 和 ZoneB 两个单元,PublisherA 处于 ZoneA 里,所以发布服务时指定了 zone=ZoneA,PublisherB 处于 ZoneB 里,所以发布服务时指定了 zone=ZoneB;此时 Subscriber 订阅时指定了 scope=datacenter 级别,因此它可以获取到 PublisherA 和 PublisherB (如果 Subscriber 订阅时指定了 scope=zone 级别,那么它只能获取到 PublisherA)。
服务注册和订阅的示例代码如下 (详细可参看官网的《客户端使用》文档):
// 构造发布者注册表,主要是指定dataInfoId和zone
PublisherRegistration registration = new PublisherRegistration("com.sofastack.test.demo.service");
registration.setZone("ZoneA");
// 发布服务数据,dataList内容是 "10.10.1.1:12200?xx=yy",即只有一个服务数据
registryClient.register(registration, "10.10.1.1:12200?xx=yy");
发布服务数据的代码示例
// 构造订阅者,主要是指定dataInfoId,并实现回调接口
SubscriberRegistration registration = new SubscriberRegistration("com.sofastack.test.demo.service",
(dataId, userData) -> System.out
.println("receive data success, dataId: " + dataId + ", data: " + userData));
// 设置订阅维度,ScopeEnum 共有三种级别 zone, dataCenter, global
registration.setScopeEnum(ScopeEnum.dataCenter);
// 将注册表注册进客户端并订阅数据,订阅到的数据会以回调的方式通知
registryClient.register(registration);
订阅服务数据的代码示例
SOFARegistry 服务端在接收到“服务发布(PublisherRegister)”和“服务订阅(SubscriberRegister)”之后,在内部会汇总成这样的一个逻辑视图。
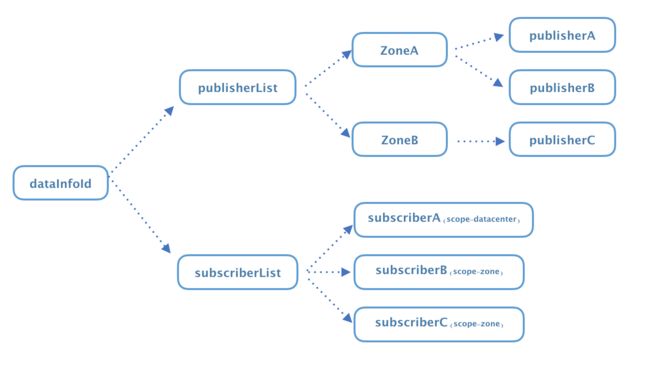
注意,这个树形图只是逻辑上存在,实际物理上 publisherList 和 subscriberList 并不是在同一台服务器上,publisherList 是存储在 DataServer 里,subscriberList 是存储在 SessionServer 里。
业界产品对比
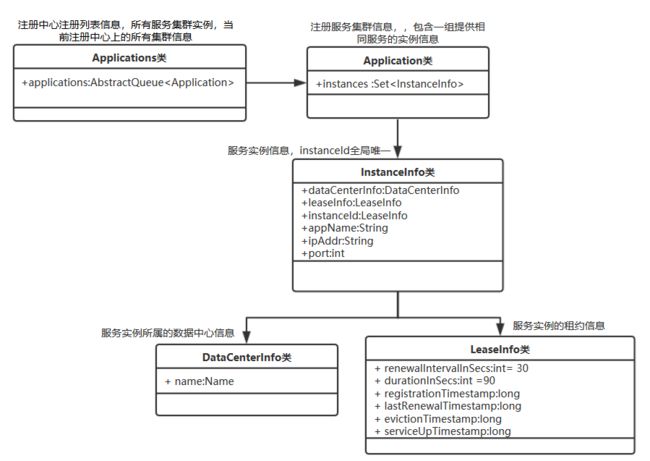
可以看出来,SOFARegistry 的模型是非常简单的,大部分服务注册中心产品的模型也就这么简单。比如 eureka 的核心模型是应用(Application)和实例(InstanceInfo),如下图,1 个 Application 可以包含多个 InstanceInfo。eureka 和 SOFARegistry 在模型上的主要区别是,eureka 在语义上是以应用(Application)粒度来定义服务的,而SOFARegistry 则是以 dataInfoId 为粒度,由于 dataInfoId 实际上没有强语义,粗粒度的话可以作为应用来使用,细粒度的话则可以作为 service 来使用。基于以上区别,SOFARegistry 能支持以接口为粒度的 SOFARPC 和 Dubbo,也支持以应用为粒度的 SpringCloud,而 eureka 由于主要面向应用粒度,因此最多的场景是在springCloud 中使用,而 Dubbo 和 SOFAPRC 目前均未支持 eureka。
另外,eureka 不支持 watch 机制(只能定期 fetch),因此不需要像 SOFARegistry 这样的 Subscriber 模型。
(图片摘自https://www.jianshu.com/p/0356b7e9bc42)
最后再展示一下 SOFARPC 基于 Zookeeper 作为服务注册中心时,在 Zookeeper 中的数据结构(如下图),Provider/Consumer 和 SOFARegistry 的 Publisher/Subscriber 类似,最大的区别是 SOFARegistry 在订阅的维度上支持 scope(zone/datacenter),即订阅范围。

如何支持海量客户端
从前面的架构介绍中我们知道,SOFARegistry 存在数据服务器(DataServer)和会话服务器(SessionServer)这 2 个角色。为了突破单机容量瓶颈,DataServer 基于一致性 Hash 存储着不同的数据分片,从而能支持蚂蚁金服海量的服务数据,这是易于理解的。但 SessionServer 存在的意义是什么?我们先来看看,如果没有SessionServer的话,SOFARegistry 的架构长什么样子:
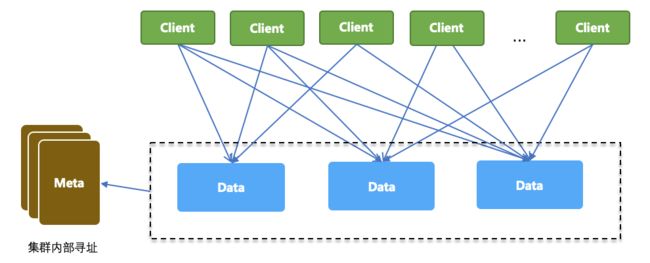
如上图,所有 Client 在注册和订阅数据时,根据 dataInfoId 做一致性 Hash,计算出应该访问哪一台 DataServer,然后与该 DataServer 建立长连接。由于每个 Client 通常都会注册和订阅比较多的 dataInfoId 数据,因此我们可以预见每个 Client 均会与好几台 DataServer 建立连接。这个架构存在的问题是:“每台 DataServer 承载的连接数会随 Client 数量的增长而增长,每台 Client 极端的情况下需要与每台 DataServer 都建连,因此通过 DataServer 的扩容并不能线性的分摊 Client 连接数”。
讲到这里读者们可能会想到,基于数据分片存储的系统有很多,比如 Memcached、Dynamo、Cassandra、Tair 等,这些系统都也是类似上述的架构,它们是怎么考虑连接数问题的?其实业界也给出了答案,比如 twemproxy,twitter 开发的一个 memcached/redis 的分片代理,目的是将分片逻辑放到 twemproxy 这一层,所有 Client 都直接和 twemproxy 连接,而 twemproxy 负责对接所有的 memcached/Redis,从而减少 Client 直接对memcached/redis 的连接数。twemproxy 官网也强调了这一点:“It was built primarily to reduce the number of connections to the caching servers on the backend”,如下图,展示的是基于 twemproxy 的 redis 集群部署架构。类似 twemproxy 的还有 codis,关于 twemproxy 和 codis 的区别,主要是分片机制不一样,下节会再谈及。
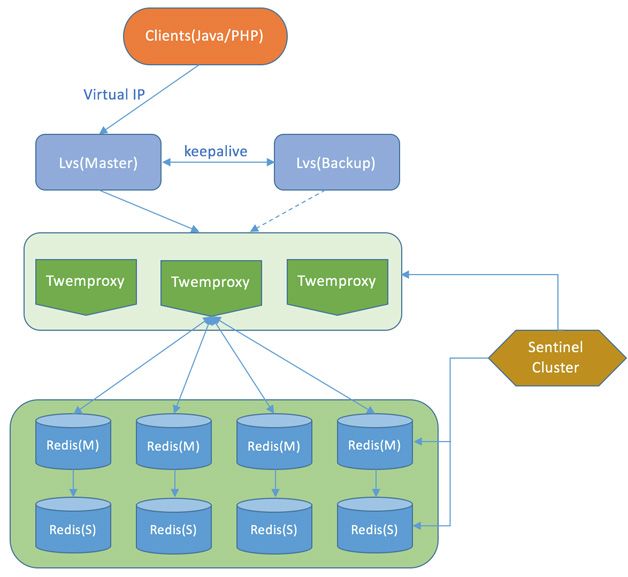
(图片摘自http://www.hanzhicaoa.com/1.php?s=twemproxy redis)
当然也有一些分布式 KV 存储系统,没有任何连接代理层。比如 Tair (Alibaba 开源的分布式 KV 存储系统),只有 Client、DataServer、ConfigServer 这 3 个角色,Client 直接根据数据分片连接多台 DataServer。但蚂蚁金服内部在使用 Tair 时本身会按业务功能垂直划分出不同的 Tair 集群,所部署的机器配置也比较高,而且 Tair 的 Client 与 data server 的长连接通常在空闲一段时间后会关闭,这些都有助于缓解连接数的问题。当然,即便如此,Tair 的运维团队也在时刻监控着连接数的总量。
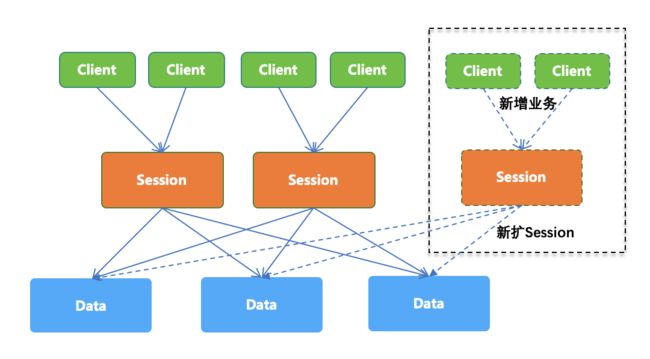
经过上面的分析,我们明白了为数据分片层(DataServer)专门设计一个连接代理层的重要性,所以 SOFARegistry 就有了 SessionServer 这一层。如图,随着 Client 数量的增长,可以通过扩容 SessionServer 就解决了单机的连接数瓶颈问题。
如何支持海量数据
面对海量数据,想突破单机的存储瓶颈,唯一的办法是将数据分片,接下来将介绍常见的有 2 种数据分片方式。
传统的一致性 Hash 分片
传统的一致性 Hash 算法,每台服务器被虚拟成 N 个节点,如下图所示(简单起见虚拟份数 N 设为 2 )。每个数据根据 Hash 算法计算出一个值,落到环上后顺时针命中的第一个虚拟节点,即负责存储该数据。业界使用一致性 Hash 的代表项目有 Memcached、Twemproxy 等。
想看完整文章内容:点击这里
原文出处:阿里云大学开发者社区
文中涉及到的相关链接
SOFARegistry:https://github.com/sofastack/sofa-registry
蚂蚁金服开源服务注册中心 SOFARegistry | SOFA 开源一周年献礼:https://mp.weixin.qq.com/s/NYq2iMU_GlP-4DnK7C8ynQ
异地多活单元化架构解决方案:https://tech.antfin.com/solutions/multiregionldc
Tair:https://github.com/alibaba/tair
SOFABolt:https://github.com/sofastack/sofa-bolt
欢迎加入,参与 SOFARegistry 源码解析

本文为 SOFARegistry 的架构介绍,希望大家对 SOFARegistry 有一个初步的认识和了解。同时,我们开启了《剖析 | SOFARegistry 实现原理》系列,会逐步详细介绍各个部分的代码设计和实现
如果有同学对以上某个主题特别感兴趣的,可以留言讨论,我们会适当根据大家的反馈调整文章的顺序,谢谢大家关注 SOFA ,关注 SOFARegistry,我们会一直与大家一起成长。
欢迎提交 issue 和 PR:
SOFARegistry:https://github.com/sofastack/sofa-registry