第三章的requests库阶段性demo,爬取好听音乐网的榜上歌曲。
此网站没有js混淆,音乐资源链接有规律,适合爬虫新手上手。
首先观察首页和音乐榜的url链接关系,我们先手动模拟下载,chrome f12获取response,可探查到url规律如下:
1.

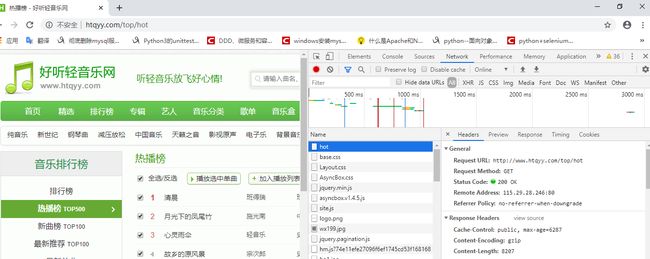
热播榜url为:
http://www.htqyy.com/top/hot
新曲榜url为:
http://www.htqyy.com/top/new
由此可知hot、new、recommend、latest、gedan分别为各榜二级网址
2.再分析hot榜单内页码网址规律
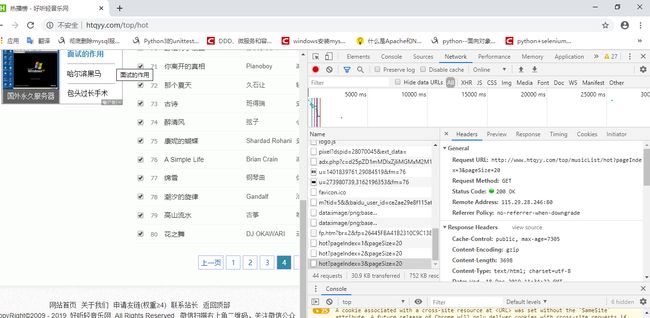
可得url规律为:{index}榜第 i 页网址为 http://www.htqyy.com/top/musicList/{index}?pageIndex=(i-1)&pageSize=20
3.接着找下载链接规律
在试听界面点击试听按钮,f12刷新 network media会获得media音频response,statu code显示为206,说明歌曲get请求已缓存到disk,验证url规律为http://f2.htqyy.com/play7/sid/mp3/12,试听和下载url的关联关系,其中sid,也就是歌曲名为主键,所以我们从音乐榜页码页获得的sid可以传入下载地址中,拼接获得下载地址,/mp3/12为固定字符串
其后我在运行爬虫的时候发现部分资源会401,找到对应的sid页面,f12排查,发现下载地址并不唯一,按mp3和m4a文件类型分别有两个地址:
http://f2.htqyy.com/play7/{sid}/mp3/12 和 http://f2.htqyy.com/play7/{sid}/m4a/12

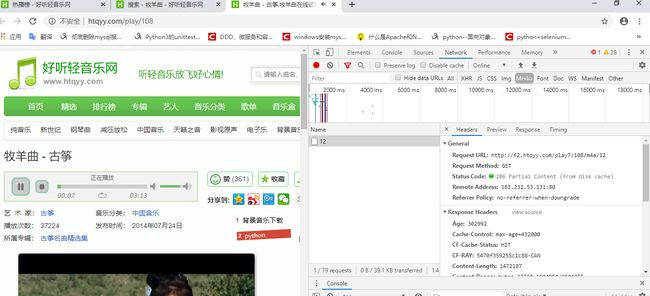
实际运行爬虫的时候,我们会发现经常有歌曲无法200正常下载,或者401或者抛出异常我自己分析的话,这有两种原因,
1.mp3格式url网址无效,需切换m4a网址下载
2.请求时间间隔太短,应设置1-2s,以防因为延迟和服务器原因无法正常爬取。
此demo主要考察python和程序设计基本功,requests库的应用较少,由此也发现异常处理、网址拼接、f12工具的使用、性能和代码质量考核等因素在爬虫设计时是非常重要的,由此也看出一个设计优异的爬虫框架对实际业务来说是非常重要的,连续爬取、防封、分布式爬取,提高性能门槛也是必须的业务要求,爬虫随便几个demo写完看似很简单,但是简单的事如何做的有质量也是不简单的。
具体代码如下:
# SweetLightSpider import re # python 的正则库 import requests # python 的requests库 import time import random # 随机选择 from requests import exceptions # requests 内置exception class SweetLightMusicSpider: def __init__(self, page): self.page = page # 随机获取音乐榜单的网页信息text数据,取得songID准备为后续url拼接,获得songName获得歌曲名 def __getSong(self): songID = [] songName = [] keyword = ["hot", "new", "recommend", "latest", "gedan"] rankform = random.choice(keyword) print(rankform) for i in range(0, self.page): url = "http://www.htqyy.com/top/musicList/"+str(rankform)+"?pageIndex="+str(i)+"&pageSize=20" # 获得带有音乐id和name的信息的html文本 html = requests.get(url) strr = html.text #正则匹配筛选信息 pat1 = r'title="(.*?)" sid' pat2 = r'sid="(.*?)"' id_list = re.findall(pat2, strr) title_list = re.findall(pat1, strr) # 获得songID/Name数组 songID.extend(id_list) songName.extend(title_list) return songID, songName def __songdownload(self): song_list = SweetLightMusicSpider.__getSong(self) for x in range(0, len(song_list[0])): song_url = "http://f2.htqyy.com/play7/"+str(song_list[0][x])+"/"+"mp3"+"/12" song_name = song_list[1][x] response = requests.get(song_url) print(response.status_code) data = response.content if response.status_code == 200: print("正在下载第{0}首, 歌曲名为:《{1}》".format(x+1, song_name)) with open("E:\\music\\{}.mp3".format(song_name), "wb") as f: f.write(data) print("第{0}首: 《{1}》 已下载完毕".format(x+1, song_name)) elif response.status_code == 401: time.sleep(2) print("重定向资源中") song_url2 = "http://f2.htqyy.com/play7/"+str(song_list[0][x])+"/"+"m4a"+"/12" response2 = requests.get(song_url2) print(response2.status_code) try: assert response2.status_code == 200 except exceptions.HTTPError as e: print(e) continue else: data2 = response2.content print("正在下载第{0}首, 歌曲名为:《{1}》".format(x + 1, song_name)) with open("E:\\music\\{}.mp3".format(song_name), "wb") as f: f.write(data2) print("第{0}首: 《{1}》 已下载完毕".format(x + 1, song_name)) time.sleep(1) def music_Spider(self): SweetLightMusicSpider.__songdownload(self) if __name__ == '__main__': i = SweetLightMusicSpider(10) i.music_Spider()
设置两个请求间隔为1s,重定向url为2s,调试如下,基本杜绝了
1.无法获取到的歌曲 2.下载错误为十几KB无法打开的歌曲 这两个运行异常bug
最后牺牲了部分爬取效率获得了爬取质量的提高:

最后检查E盘的音乐下载情况,没有下载错误,文件大小均在1-3mb,不存在音乐无法打开的情况

随便打开一首网易云播放器验证下:

没有问题,bingo。因为是轻音乐网站嘛,faded的纯乐器版。。。。。。i am faded >_<