Actors are a fundamental model for concurrency(协程、真正的OO、whatever总之actor是高并发无阻塞架构下实体对象的表现形式), but there are common patterns where their use requires the user to implement the same pattern over and over. Very common is the scenario where a chain, or graph, of actors, need to process a potentially large, or infinite, stream of sequential events and properly coordinate resource usage so that faster processing stages do not overwhelm slower ones in the chain or graph. Streams provide a higher-level abstraction on top of actors that simplifies writing such processing networks. 集群的消息分两种一是管理类的集群协调消息二是海量业务消息,gossip+CRDT专用于前者,分布式发布订阅(拉式)可用于后者、流式(推式)更适合于后者。

actor威力来源之一是对象级别的深度解耦Deep Decouple,我们知道c++对解耦的努力是头文件+dll、Java的努力是Spring+jar,均属于面向接口编程路线,接口即对象之间的调用协议,面向接口编程可以促进开发时解耦(但未解决运行时耦合),开发时耦合即依赖、运行时耦合可以说是方法调用栈Call Stack,所谓解耦并非斩断耦合而是改变耦合方向(Spring好莱坞原则),面向接口编程使得对象的依赖方向从硬耦合另一个对象改为在编译时统一依赖一个接口层、在运行时依赖Ioc容器做DI,按照Spring思路,越抽象越稳定,抽象接口层可以作为稳定的基础设施(一厢情愿)、由Ioc容器在运行时去自动装配程序、DI主动注入依赖将接口实体化,Spring成也OO败也OO,面向接口编程路线只是表面上解耦了编译时耦合,并未改变运行时耦合而只是将其延后、希望利用bean容器屏蔽它,运行时对象结构仍然是Call Stack传统调用栈,对象之间的方法层层嵌套、方法逐层入栈、穿糖葫芦式运行时线程对象结构、对象之间硬耦合,导致硬性直接的互相影响:一个方法阻塞上层调用方法全部阻塞;一个方法异常则逐层上抛影响上层、如果整个堆栈没有方法正确处理异常则抛出到当前线程之外、线程Shut down;异常即使捕获,也形同鸡肋,因为当前对象缺乏处理异常的知识和能力,捕获和不捕获结果都一样:懵逼。对象也无法重启自己,更表讲前面还有一长串的调用对象根本不受控、不可替换。
actor通过消息caseClass替代了接口,消息即协议、消息替代了接口的作用但在重量级上只相当于接口函数的参数,由于caseClass十分轻量、故而对协议的变更做到了极其方便、超低成本的随需应变,因此将开发时的耦合消弭无形。至于运行时耦合,actor解的更彻底:actor在实体对象之间增加了非阻塞队列(mailBox),使系统骨干实体对象彻底解耦,这改变了运行时线程对象结构,真正解耦了运行时依赖,使实体对象拥有独立之思想。当然与Spring类似的,实体总有出处,这个出处就是Akka的统一线程调度 + actor托管(相当于Ioc容器的位置)及通讯层:
Millions of actors can be efficiently scheduled on a dozen of threads
并不是说要消灭Call Stack,Call Stack是程序基本调用单元,但是它很僵硬,任何东西都有它应该处在的层次位置。OO也是一个较高层次上的架构模型,在底层工具类、需要做一些很明确具体工作的类中比如Service,没有必要再去遵循OO,直接过程式编码就是了,而Actor所处层次甚至比OO还高一点:应在业务实体对象层次及其上层开始遵循actor style,业务实体对象应该是actor,下层继续保持传统Call Stack程序运行时结构,这里的实体应该怎么识别界定呢?我们说实体也叫作 concurrent entity 并发实体,也就是说按照需求可以抽象出来一批中间层业务对象,这些业务对象要并发、要分布、要弹性伸缩、要有状态,O了,这些业务对象就可以识别为实体了,应用Actor就在这一层切入,这一层之上全是actor style、之下可以继续OO、再往下到了方法体内则是过程式代码。可称之为:
协作实体模型 model of cooperative entities
由于actor之间从传统方法堆栈变为了异步非阻塞队列,带来了actor/O之间的彻底解耦,再有actor监管体系的加持,使得actor具备了let it Crash的底气和一系列开脑洞应用:第一个最佳实践模式是worker模式:上层的监管者actor不做具体业务只做worker actor的创建监管以及任务的分发(注意worker actor的创建是在运行时,全动态的),所以上层actor十分稳固,而任务执行都是有风险的,比如可能需要IO、需要做一些计算、更有甚者大数据平台还要经常执行外来代码,这全是风险,有可能随时异常,如果worker actor抛出异常,上层actor具备任务背景知识,是最适合恢复任务的角色,它也有能力重启worker actor;所以,第二个最佳实践:一个纯粹稳固的监管层也是actor的最佳设计实践之一,这里要强调纯粹,做监管的就只做监管,其代码十分简单、十分纯粹、十分安全:
不必拘泥于一些名词,比如说普通的方法参数,其实它不就是一个对象发给另一个对象的消息吗?只不过我们习惯于一说到消息好像就应该是MQ领域的远程、异步的才叫消息,没人给出这个规定,其实方法参数也是消息,只不过传统Call Stack是同步处理方式而已,即使是传统调用栈,当方法A正要调用方法B时,如果此时线程时间片用完,线程需要退出CPU,方法调用栈连同线程上下文保存下来、下次可能会由另一条线程再执行,这和异步线程间消息一样。
基于我们都熟悉的生产者消费者视角去理解actor其实是很明白的:生产者生产任务、如果直接调用消费者的方法去执行任务那么生产者和消费者会互相阻塞,要匹配二者的生产消费速率就可以在调用环节做文章,比如加入一个非阻塞队列,这就已经很接近actor模型了,方法调用会传递线程(行为)控制权、但是消息传递不会。
基于actor设计系统:DDD
Akka HTTP从头到脚都是流式的(不只是请求req、响应res、连HttpEntity也是流式的):A socket binding is represented as a stream of incoming connections.,现在的HTTP远不仅用于web,HTTP1.1就可以单条传输几百M数据、gRPC以长连接双工HTTP2作为传输协议表明HTTP已不是原来那个一次性请求响应,AkkaHTTP客户端还可以维护、重用一个到服务端的TCP连接池。流式的好处一是可以用固定的内存用量处理很大的请求响应数据、二是可以做流控,用简单的curl --limit-rate 50b 127.0.0.1:8080/random客户端就可以。要流式处理HTTP连接得用low-level API来做,该API轻量、单一、有专用依赖包akka-http-core.jar、专注于实现 HTTP/1.1 server的核心功能:
1、Connection management 连接管理,这里的连接指一个成功绑定的socket,会表达为一个stream of incoming connections. 你的应用代码从中pulls connections from this stream source、可以for each处理它们,用一个Flow[HttpRequest, HttpResponse, _]来将请求“translate”翻译为响应。
2、Parsing and rendering of messages and headers
3、Timeout management (for requests and connections)
4、Response ordering (for transparent pipelining support)
如果不需要控制这些核心功能,只是对http的常规业务处理(request routing, file serving, compression, etc.) 那么请点招牌菜high-level API(akka-http.jar依赖),它的标准用法是基于一系列Directive的Routing DSL,代码的可读性、组合能力更好、对HTTP的两个关注点:路由和Mashall处理起来行云流水。由于是全流式的,正常情况下服务端必须要把HttpEntity“消费干净”,最简单的方式是用RoutingDSL Unmarshall方法:entity(as[...])“耗尽”流式HttpEntity,as类型可以是String当然也可以是你的domain object.,使用RoutingDSL这种high-level API大部分时候不用管流的事。
用low-level API的时候没有RoutingDSL可用,直接处理connection,有三种方法可用:handleWith、handleWithSyncHandler、handleWithAsyncHandler
AkkaStream实现了Reactive Streams specification,实现了其三个主要功能:
backpressure反压;async异步;non-blocking boundaries非阻塞边界(等价于mailBox)
AkkaStream的运行引擎是ActorMaterializer、ActorMaterializer基于actor
AkkaStream具备三个主要building blocks(它们组合成Graph):

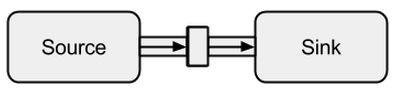
AkkaStream本身就是actor chain,所以也可以很简单的使用actor给流feed数据:
def run(actor: ActorRef) = {
Future { Thread.sleep(300); actor !1 }
Future { Thread.sleep(200); actor !2 }
Future { Thread.sleep(100); actor !3 }
}
val s = Source
.actorRef[Int]( bufferSize =0, OverflowStrategy.fail )
.mapMaterializedValue( run )
s runForeach println
Reactive Streams are lazy and asynchronous by default. This means one explicitly has to request the evaluation of the stream. In Akka Streams this can be done through the run* methods.
Source可以看做非阻塞队列,从中获取数据是“拉”方式,所有run开头的方法就相当于去poll
Akka流也可以是打开文件或者socket连接 etc. 估计是由于actor消息是无类型的Any,而JVM底层对于集合(流也类似集合)的元素类型是擦除的,所以在构建流过程中还需要对消息的类型做额外的指定:在环节当中指定Keep.left、Keep.right.
Akka Streams一大口号是:一切皆蓝图、一切皆可重用,包括Source、Flow、Sink;举个栗子:直接“预先装配”一个写文件的Sink并把它作为一个可重用片段,对它的描述是:输入字符串、包装出来ByteString元素。描述流的语言类似英语,从左到右读,元素的流动也是,所以会有Keep.right这种鬼样子代码,直接描述Sink,我们需要一个起点,有点像一个源Source,但是它必须有“左侧开口“(open input.),这种起点就是Flow:
def lineSink(filename: String): Sink[String, Future[IOResult]] = Flow[String]
.map(s ⇒ ByteString(s + "\n")) //把String转为ByteString
.toMat( FileIO.toPath(Paths.get(filename)) ) (Keep.right)
lineSink是个生产Sink的方法,接收文件名产出Sink[String, Future[IOResult]]:这个Sink有像偏函数一样的类型参数格式,第一个是接收参数的类型、第二个是返回类型。
FileIO.toPath实际创建了一个FileSink. 这个Sink输入ByteString 输出Future[IOResult]
toMat方法是专用于把Flow附加到Sink上去的组合mini小方法、这个方法挺有意思虽然是Flow的方法但产出却是Sink,其实就是附加了Flow功能的新的Sink,这个新Sink在写文件落盘之前自动转换string为ByteString(It is possible to attach a Flow to a Source resulting in a composite source, and it is also possible to prepend a Flow to a Sink to get a new sink.)可以将上节提过的阶乘Source直接和这个Sink对接:
val factorials = source.scan( 1 )( (acc, next) ⇒ acc * next )
factorials.map(_.toString).runWith( lineSink("factorial2.txt") )
scan是类似scala集合操作构造阶乘“集合”Source、runWith方法是直连Source/Flow和Sink的专用小方法(attach the Flow to a Sink that will get the Flow running. The simplest way to do this is to call runWith(sink) on a Source. Source与Flow类似,拥有共同父特质FlowOpsMat)
再一次看到集合操作泛化,以无限的、懒求值的、元素有序的Seq序列观点来看待流也蛮合适:
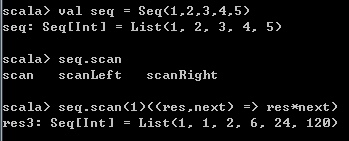
scala语言库自带一个collection.immutable.Stream,可以说就是个tail元素懒求值的List,类似List的::操作符它有一个#::,类似List的Nil它有一个Stream.empty:
在Akka的Source和Flow上可以调用这样的方法:throttle(1, 1.second)限制消息流动速率不超过每秒一条(throttle定义在Source和Flow共同父特质FlowOpsMat),throttle限流方法是个对发往下游的消息速率最大值做限制的方法(set the maximum rate for emitting messages.)AkkaStream所有的operators 算子都是天生具备限流能力:
Akka Streams implicitly implement pervasive flow control, all operators respect back-pressure. This allows the throttle operator to signal to all its upstream sources of data that it can only accept elements at a certain rate—when the incoming rate is higher than one per second the throttle operator will assert back-pressure upstream. 所有的方法像map/filter以及Source、Flow、Sink都是算子,方法都是类集合操作的(The operations should look familiar to anyone who has used the Scala Collections library),比如Sink伴生对象定义了很多像foreach这样的快捷方法,但是也有只与流语义相关而与集合无关的如ignore,对于foreach、fold这些最常用的方法,在Flow里定义了更快捷的语法糖如runForeach.
流的物化
Materialization实体化会被所谓的“terminal operations”所触发,最常见的就是各种run方法,这些方法在Source和Flow中都有定义,也有少量语法糖比如Source.runForeach(el => ...),实际上就是Source.runWith(Sink.foreach(el => ...)) 的别名,这些操作是直接对接了Source和Sink,因为没有什么对消息的中间处理也可以不用Flow,还可以用Source.via来连接Flow,用Source.to连接Sink,via和to分别是viaMat和toMat的简写,分别固定了Keep.left(最终结果当中的消息类型与最左侧Source一致)。三大件Source -> Flow -> Sink:
// An source that can be signalled explicitly from the outside
val source: Source[Int, Promise[Option[Int]]] = Source.maybe[Int]
// A sink that returns the first element of a stream in the returned Future
val sink: Sink[Int, Future[Int]] = Sink.head[Int]
// A flow that internally throttles elements to 1/second, and returns a Cancellable
// which can be used to shut down the stream
val flow: Flow[Int, Int, Cancellable] = throttler
// By default, the materialized value of the leftmost stage is preserved
val r1: RunnableGraph[Promise[Option[Int]]] = source.via(flow).to(sink) //最终类型靠左也就是和soure一致
// Simple selection of materialized values by using Keep.right
val r2: RunnableGraph[Cancellable] = source.viaMat(flow)(Keep.right).to(sink) //和flow一致
val r3: RunnableGraph[Future[Int]] = source.via(flow).toMat(sink)(Keep.right) //和sink一致
其他实例
Operator Fusion算子融合
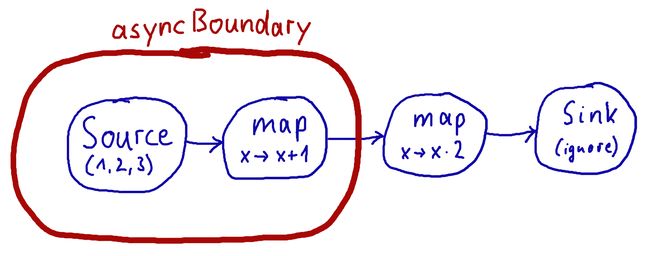
Akka Streams默认情况下会融合流operators算子/操作符,也就是说一个flow 流或者 stream graph图全部由一个 Actor执行,这样由于避免了异步消息传递,速度可以快很多(应该是仅仅对单条消息而言);同时融合的流操作符不会并行执行,意味着每次运行只会使用一个CPU core,要支持异步运行你需要手动插入asynchronous boundaries异步边界:在Source、Sink和Flow上调用async,这样会添加Attributes.asyncBoundary.
Source(List(1, 2, 3)) .map(_ + 1)
.async //此处将前后划分为两个异步过程,可以同时进行,如下图示:
.map(_ * 2) .to(Sink.ignore)
组合实体化值
通过上例我们看到,Akka Streams的所有操作符在实体化之后都会产出一个materialized value实体化值,所以需要明确这些值如何组合出最终结果值,此为上述Keep.left、Keep.right的作用。
我们看到由于scala对以java为基础的集合库做了卓有成效的扩展,FP风格的集合操作有扩展到其他类型上去的趋势,小的比如Option、Future类型;大点的如Stream库;更大的如类似hibernate做ORM的做FRM的slick框架。
来看看Source,Flow,Sink的类型参数:
Source[+Out, +Mat]//Out代表元素类型,Mat为运算结果类型
Flow[-In, +Out, +Mat]//In,Out为数据流元素类型,Mat是运算结果类型
Sink[-In, +Mat]//In是数据元素类型,Mat是运算结果类型
参考:https://www.cnblogs.com/tiger-xc/p/7364500.html
待译:http://blog.colinbreck.com/integrating-akka-streams-and-akka-actors-part-i/