深度学习或者说神经网络中最让人头疼的问题也是最常见的问题,便是过拟合和欠拟合问题。过拟合体现在训练数据集中模型表现出很高的准确性,但是在测试集中表现缺很差,欠拟合体现在训练无论是训练数据集还是测试数据集模型准确率都很低。
一般情况下,我们会发现随着训练数据epoch的增加,模型验证(Validation)准确率开始升高然后出现peak,接下来开始下降。下降的那一刻开始就预示着模型已经过拟合了。
无论是Machine Learning还是Deep Learning,我们追求的是训练数据集高的准确率,这样我们会尝试接近模型的能力极限,但是对我们而言,更重要的是,模型对于从未见过的测试数据的预测能力,这决定了模型的生存能力和始应能力。正常来说,模型在训练数据集中容易实现高的准确率,但是在测试数据集中依然表现良好需要工程师去寻找一个平衡点,降低模型的训练精度,提高模型的测试精度。
欠拟合和过拟合就像是我们经常玩的跷跷板,我们需要找到一个平衡点,这也是一个trade-off的过程。生活中处处有这样的经历,我们去购物要去权衡商品的性价比和我们的经费关系,我们即使去趟机场到底是租车还是打车还是坐地铁坐公交,这些都是我们在考量一种最适合我们并且能满足我们需求的方案,这便是优化,人脑很难在复杂的关系中计算出最完美的决策,所以这里没有说是最优化。计算机相比人脑,强大的运算能力可以让最优化得以实现,我们用的导航提示我们的最快路线,淘宝里提示的怎样买最划算,等等都属于这类问题。
回过头,再来说欠拟合的原因。
欠拟合,顾名思义,没够,模型的学习程度还不够,一般有以下几个原因造成:
- 模型本身设计有缺陷
- over-regularized
- 训练数据集太少
- 训练程度不够
过拟合的原因就类似:
- 模型过于复杂(类似神经网络)
- no regularization
- epoch过大
- 数据量太小
常用的正则化方法是: 权重正则, dropout
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
NUM_WORDS = 10000
(train_data, train_labels), (test_data, test_labels) = keras.datasets.imdb.load_data(num_words=NUM_WORDS)
def multi_hot_sequences(sequences, dimension):
results = np.zeros((len(sequences),dimension))
for i, word_indices in enumerate(sequences):
results[i, word_indices] = 1.0
return results
train_data = multi_hot_sequences(train_data, dimension=NUM_WORDS)
test_data = multi_hot_sequences(test_data, dimension=NUM_WORDS)
证明过拟合
-
Baseline model
baseline_model = keras.Sequential([
keras.layers.Dense(16, activation=tf.nn.relu, input_shape=(NUM_WORDS,)),
keras.layers.Dense(16, activation=tf.nn.relu),
keras.layers.Dense(1, activation=tf.nn.sigmoid)
])
baseline_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy','binary_crossentropy'])
baseline_model.summary()

baseline_history = baseline_model.fit(train_data,
train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
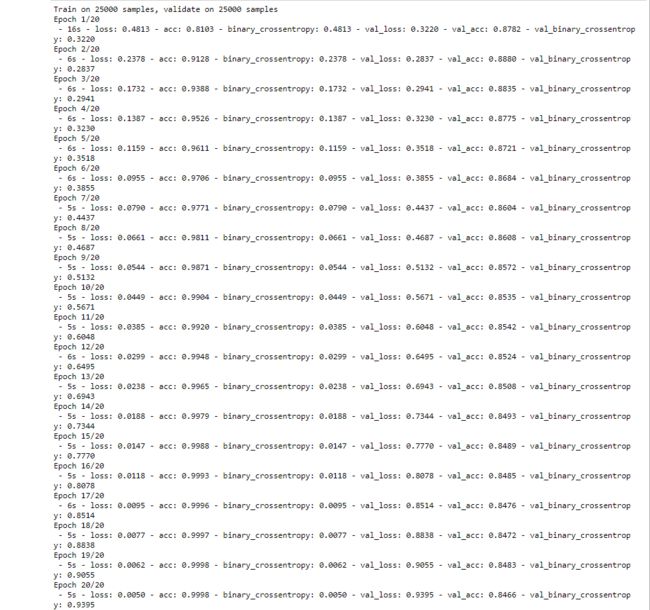
-
Smaller model
smaller_model = keras.Sequential([
keras.layers.Dense(4, activation=tf.nn.relu, input_shape=(NUM_WORDS,)),
keras.layers.Dense(4, activation=tf.nn.relu),
keras.layers.Dense(1, activation=tf.nn.sigmoid)
])
smaller_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy','binary_crossentropy'])
smaller_model.summary()

smaller_history = smaller_model.fit(train_data,
train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
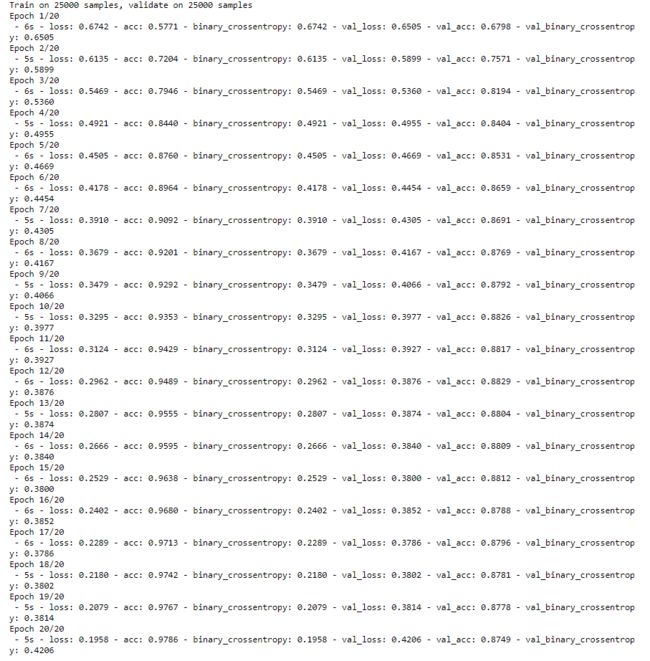
-
Bigger model
bigger_model = keras.models.Sequential([
keras.layers.Dense(512, activation=tf.nn.relu, input_shape=(NUM_WORDS,)),
keras.layers.Dense(512, activation=tf.nn.relu),
keras.layers.Dense(1, activation=tf.nn.sigmoid)
])
bigger_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy','binary_crossentropy'])
bigger_model.summary()

bigger_history = bigger_model.fit(train_data, train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
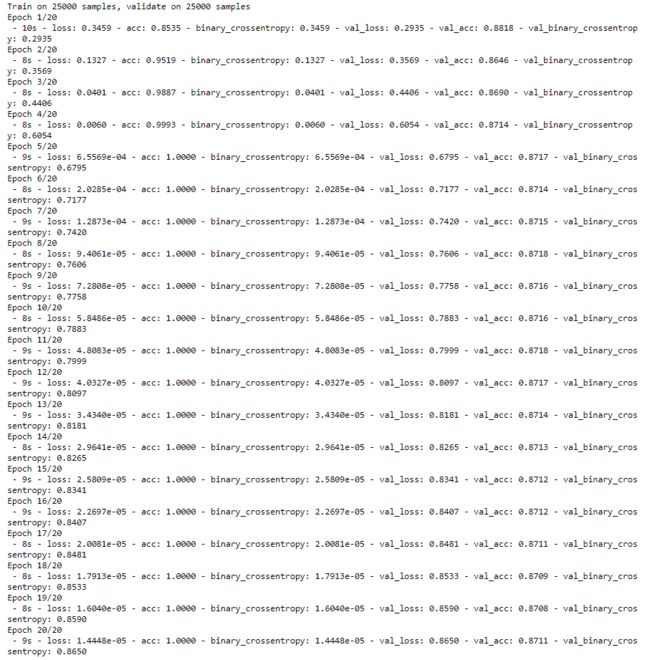
比较
def plot_history(histories, key = 'binary_crossentropy'):
plt.figure(figsize=(16,10))
for name, history in histories:
val = plt.plot(history.epoch, history.history['val_'+key],
'--', label=name.title()+' Val')
plt.plot(history.epoch, history.history[key], color=val[0].get_color(),
label=name.title()+' Train')
plt.xlabel('Epochs')
plt.ylabel(key.replace('_',' ').title())
plt.legend()
plt.xlim([0,max(history.epoch)])
plot_history([('baseline', baseline_history),
('smaller', smaller_history),
('bigger', bigger_history)])
plt.show()
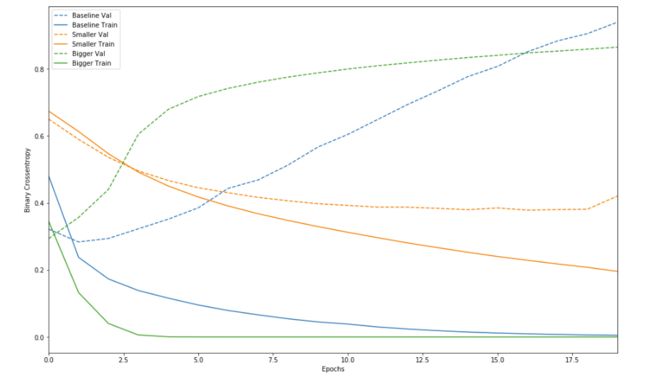
从上图可以看出,模型越复杂,模型收敛越快,同时对于过拟合越敏感。
避免过拟合的方法
增加权重正则
l2_model = keras.models.Sequential([
keras.layers.Dense(16, kernel_regularizer=keras.regularizers.l2(0.001), #l2(0.001)是0.001*weight_coefficient_value**2
activation=tf.nn.relu, input_shape=(NUM_WORDS,)),
keras.layers.Dense(16, kernel_regularizer=keras.regularizers.l2(0.001),
activation=tf.nn.relu),
keras.layers.Dense(1, activation=tf.nn.sigmoid)
])
l2_model.compile(optimizer='adam',
loss = 'binary_crossentropy',
metrics=['accuracy','binary_crossentropy'])
l2_model_history = l2_model.fit(train_data, train_labels,
epochs=20,
batch_size=512,
validation_data = (test_data, test_labels),
verbose=2)
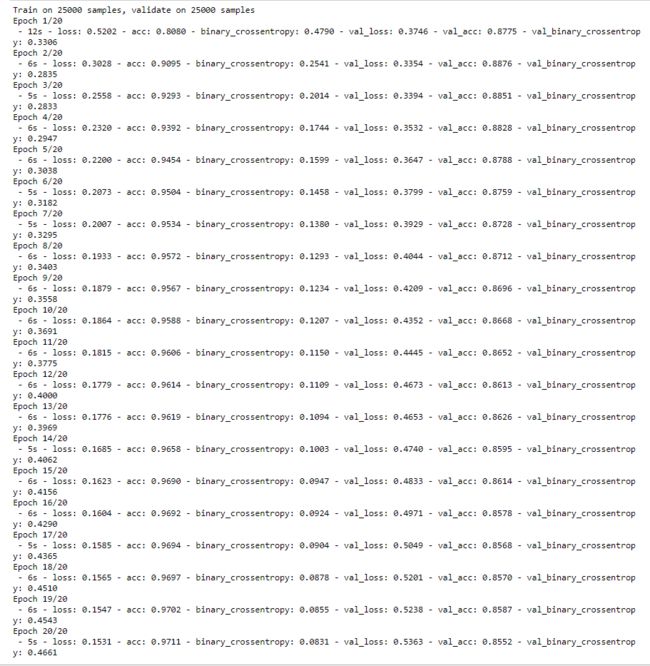
plot_history([('baseline', baseline_history),
('l2', l2_model_history)])
plt.show()
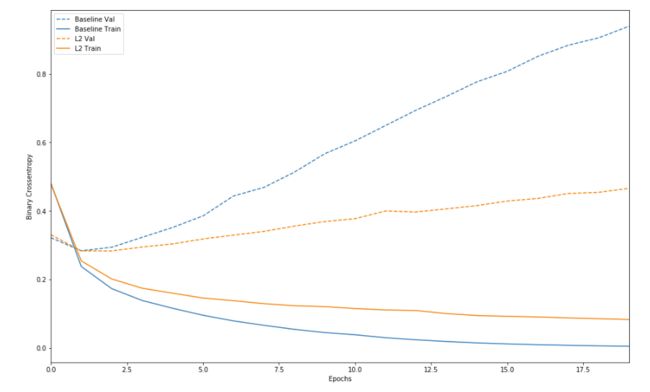
可以看出,引入L2正则以后,过拟合现象得到好转。
增加Dropout
dpt_model = keras.models.Sequential([
keras.layers.Dense(16, activation=tf.nn.relu, input_shape=(NUM_WORDS,)),
keras.layers.Dropout(0.5),
keras.layers.Dense(16, activation=tf.nn.relu),
keras.layers.Dropout(0.5),
keras.layers.Dense(1, activation=tf.nn.sigmoid)
])
dpt_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy','binary_crossentropy'])
dpt_model_history = dpt_model.fit(train_data, train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)

plot_history([('baseline', baseline_history),
('dropout',dpt_model_history)])
plt.show()

同样,可以发现,采用dropout,过拟合得到改善还是很明显的。