
1. 简介
1.1 Kylin概览
Apache Kylin是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力(可以把Kylin定义为OLAP on Hadoop)。Apache Kylin于2015年11月正式毕业成为Apache基金会(ASF) 顶级项目,是第一个由中国团队完整贡献到Apache的顶级项目。
Apache Kyiln构建在Hadoop等分布式计算平台之上,充分利用了MapReduce的并行处理能力和可扩展基础设施,高效地处理超大规模数据,可根据数据的规模实现架构的可伸缩。Apache Kylin作为OLAP引擎包含了从数据源(Hive/Kafka等)获取源数据,基于MapReduce构建多维立方体(Cube),并充分利用HBase的列式特性来分布式的存储立方体数据,提供标准SQL解析与查询优化,以及ODBC/JDBC驱动及REST API等多个模块。可插拔的灵活架构,允许支持更多的数据源接入Kylin,也支持采用其它技术作为存储引擎。
大多数的Hadoop分析工具和SQL是友好的,所以Apache Kylin拥有SQL接口这一点就显得尤为重要。Kylin用的SQL解析器是开源的Apache Calcite,支持几乎所有的SQL标准。Hive用的也是Calcite。
Kylin和其它SQL ON Hadoop的主要区别是预计算(离线计算)。用户在使用之前先选择一个Hive Table的集合,然后在这个基础上做一个离线的Cube构建,Cube构建完了之后就可以做SQL查询了。
用离线计算来代替在线计算,在离线过程当中把复杂的、计算量很大的工作做完,在线计算量就会变小,就可以更快的返回查询结果。通过这种方式,Kylin可以有更少的计算量,更高的吞吐量。
Apache Kylin开源一年左右的时间,已经在国内国际多个公司被采用作为大数据分析平台的关键组成部分,包括eBay、Expedia、Exponential、百度、京东、美团、明略数据、网易、中国移动、唯品会、58同城等。
1.2 Kylin架构
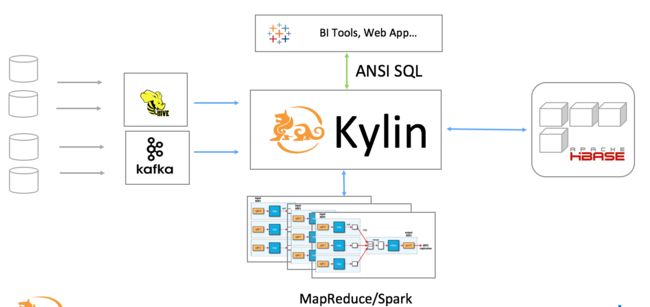
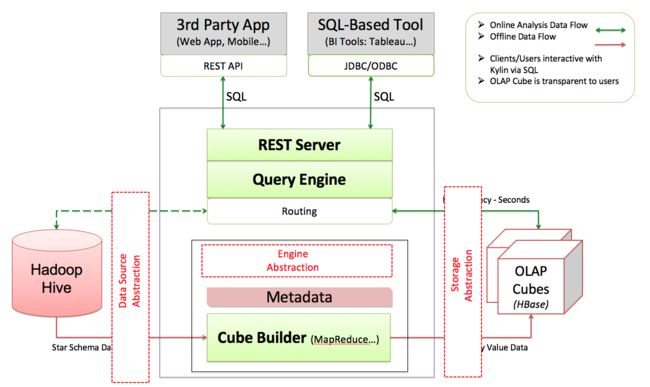
Apache Kylin包含以下核心组件:
元数据引擎:包含模型设计,Cube设计,表结构同步,数据采样分析等。支持层级维度、联合维度、可推导维度等维度降维优化技术,避免Cube数据膨胀。支持多种字典编码算法,实现数据高效压缩存储。
Job引擎:用于向Hadoop平台提交Cube构建任务,支持全表构建、增量构建、流式构建等多种构建机制,支持Cube自动合并等IO优化手段,内置多种Cube预计算算法以及数十个Job性能调优参数,充分发挥MapReduce的计算能力。
存储引擎:将关系型表的源数据,经过预计算,保存在支持高通量大并发快速读写的键值数据库HBase中,充分利用HBase高效的Fuzzy Key过滤技术和Coprocessor并行处理技术,以并行计算方式检索数据,支持查询逻辑下压存储节点,实现了数据检索问题由O(N)的计算复杂度降低为O(1)。
查询引擎:构建在Apache Calcite语法解析器之上,支持JDBC/ODBC/REST等多种协议和接口,支持ANSI SQL,包含绝大多数SQL函数,提供自定义计算函数机制,与Tableau等主流BI工具完美对接。
Web管理端:内置用户友好的交互界面,支持向导式的模型构建,直观的任务监控与告警,以及用户权限管理。
1.3 Kylin特点
**可扩展超快OLAP引擎: **
Kylin是为减少在Hadoop上百亿规模数据查询延迟而设计**Hadoop ANSI SQL 接口: **
Kylin为Hadoop提供标准SQL支持大部分查询功能**交互式查询能力: **
通过Kylin,用户可以与Hadoop数据进行亚秒级交互,在同样的数据集上提供比Hive更好的性能多维立方体(MOLAP Cube):
用户能够在Kylin里为百亿以上数据集定义数据模型并构建立方体与BI工具无缝整合:
Kylin提供与BI工具,如Tableau,的整合能力,即将提供对其他工具的整合-
其他特性:
- Job管理与监控
- 压缩与编码
- 增量更新
- 利用HBase Coprocessor
- 基于HyperLogLog的Dinstinc Count近似算法 - 友好的web界面以管理,监控和使用立方体
- 项目及立方体级别的访问控制安全
- 支持LDAP
1.4 Kylin生态圈

Kylin 核心: Kylin OLAP引擎基础框架,包括元数据(Metadata)引擎,查询引擎,Job引擎及存储引擎等,同时包括REST服务器以响应客户端请求
扩展: 支持额外功能和特性的插件
整合: 与调度系统,ETL,监控等生命周期管理系统的整合
用户界面: 在Kylin核心之上扩展的第三方用户界面
驱动: ODBC 和 JDBC 驱动以支持不同的工具和产品,比如Tableau
1.5 Kylin在各大公司的实践
- Apache Kylin在美团数十亿数据OLAP场景下的实践
- Apache Kylin在百度地图的实践
- Apache Kylin在京东云海的实践
- Apache Kylin 在电信运营商的实践和案例分享
- Apache Kylin在国美在线的应用
- Apache Kylin在魅族的实践

1.6 Kylin基础概念
- 星型模型

- Cube
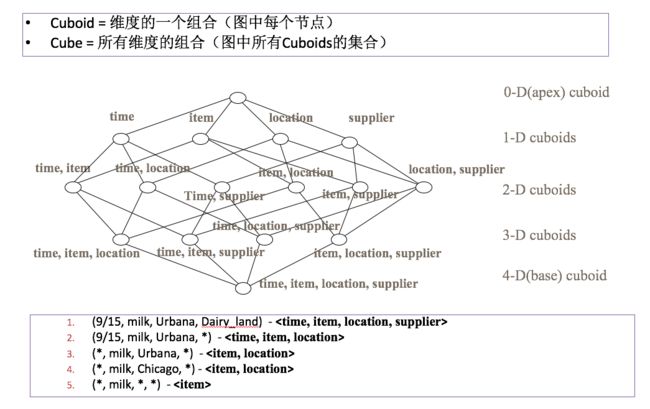 cube
cube
- 在HBase中存储
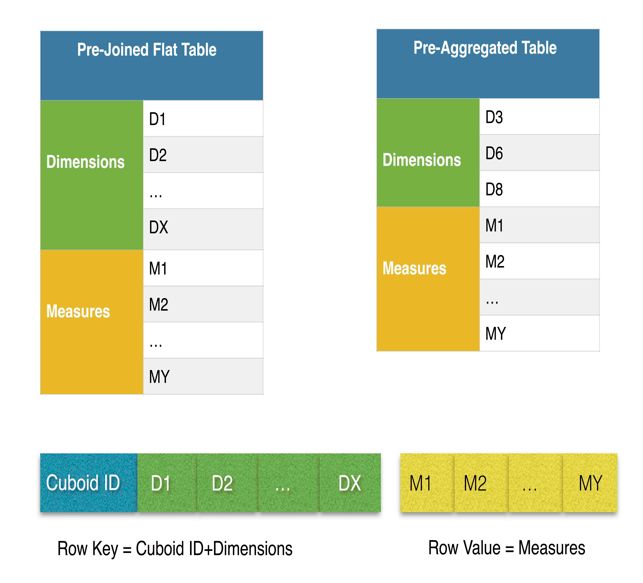
1.6.1 CUBE
Table - 表, 是Cube的数据源;在创建Cube之前,KAP需要从数据源(通常为Hive)同步表的元数据,包含表名、列名、列属性等。
Data Model - 数据模型,定义了由若干张表的一个连接关系。Kylin支持星型模型的多维分析;在创建Cube之前,用户需定义这么一个数据模型(目前Kylin只支持星型模型,未来会支持雪花模型)。
Cube - 数据立方体,是一种多维分析的技术,通过预计算,将计算结果存储在某多个维度值所映射的空间中;在运行时通过对Cube的再处理而快速获取结果。
Partition - 分区,用户可以定义一个分区日期或时间列,随后对Cube的构建按此列的值范围而进行,从而将Cube分成多个Segment。
Cube Segment - 每个Cube Segment是对特定时间范围的数据计算而成的Cube。每个Segment对应一张HBase表。
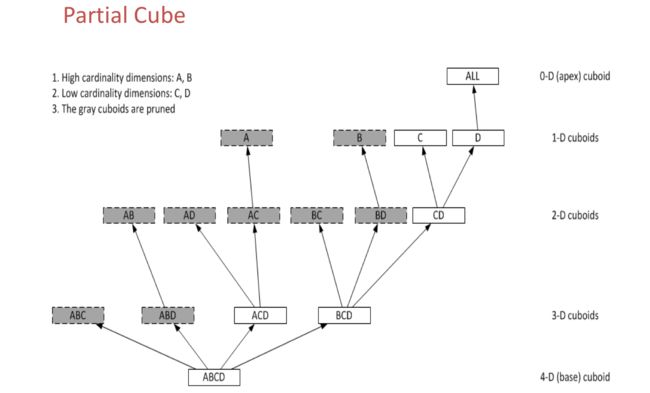
Aggregation Group - 聚合组,每个聚合组是全部维度的一个子集;通过将很多个维度分组,并把常一起使用的维度放在一起,可以有效降低Cube的组合数。
1.6.2 维度 & 度量
Mandotary - 必需的维度:这种类型用于对Cube生成树做剪枝:如果一个维度被标记为“Mandatory”,会认为所有的查询都会包含此维度,故所有不含此维度的组合,在Cube构建时都会被剪枝(不计算).
Hierarchy - 层级维度:如果多个维度之间有层级(或包含)的关系,通过设置为“Hierarchy”,那些不满足层级的组合会被剪枝。如果A, B, C是层级,并且A>B>C,那么只需要计算组合A, AB, ABC; 其它组合如B, C, BC, AC将不做预计算。
Derived - 衍生维度:维度表的列值,可以从它的主键值衍生而来,那么通过将这些列定义为衍生维度,可以仅将主键加入到Cube的预计算来,而在运行时通过使用维度表的快照,衍生出非PK列的值,从而起到降维的效果。
Count Distinct(HyperLogLog) - 基于HyperLogLog的Count Distint:快速、精确的COUNT DISTINCT是较难计算的, 一个近似的轻量级算法 - HyperLogLog 为此而发明, 能够在大规模数据集上做去重并保持较低的误差率.
Count Distinct(Bitmap) - 基于Bitmap的COUNT DISTINCT,可以精确去重,但是存储开销较大。目前只支持int的数据类型.
Top N - 预计算最top的某些记录的度量,如交易量最大的1000个卖家。
1.6.3 CUBE 操作
BUILD - 构建:给定一个时间范围,将源数据通过运算而生成一个新的Cube Segment。
REFRESH - 刷新:对某个已经构建过的Cube Segment,重新从数据源抽取数据并构建,从而获得更新。
MERGE - 合并:将多个Cube Segment合并为一个Segment。这个操作可以减少Segment的数量,同时减少Cube的存储空间。
PURGE - 清空:将Cube的所有Cube Segment删除。
1.6.4 JOB状态
NEW - 新任务,刚刚创建。
PENDING - 等待被调度执行的任务.
RUNNING - 正在运行的任务。
FINISHED - 正常完成的任务(终态)。
ERROR - 执行出错的任务。
DISCARDED - 丢弃的任务(终态)。
1.6.5 JOB 操作
RESUME - 恢复:处于ERROR状态的任务,用户在排查或解决问题后,通过此操作来重试执行。
DISCARD - 丢弃:放弃此任务,立即停止执行且不会再恢复。
2. 使用
2.1 样例数据集
二进制包中包含了一份用于测试的样例数据集,总共大小仅1MB左右,共计3张表,其中事实表有10000条数据。
Kylin仅支持星型数据模型,这里用到的样例数据集就是一个规范的星型模型结构,它总共包含了3个数据表:
KYLIN_SALES 该表是事实表,保存了销售订单的明细信息。每一列保存了卖家、商品分类、订单金额、商品数量等信息,每一行对应着一笔交易订单。
KYLIN_CATEGORY_GROUPINGS 该表是维表,保存了商品分类的详细介绍,例如商品分类名称等。
KYLIN_CAL_DT 该表是维表,保存了时间的扩展信息。如单个日期所在的年始、月始、周始、年份、月份等。这三张表一起构成了整个星型模型的结构,下图是实例-关系图(图中未列出表上的所有列):

数据表与关系
| 表 | 字段 | 意义 |
|---|---|---|
| KYLIN_SALES | PART_DT | 订单日期 |
| KYLIN_SALES | LEAF_CATEG_ID | 商品分类ID |
| KYLIN_SALES | SELLER_ID | 卖家ID |
| KYLIN_SALES | PRICE | 订单金额 |
| KYLIN_SALES | ITEM_COUNT | 购买商品个数 |
| KYLIN_SALES | LSTG_FORMAT_NAME | 订单交易类型 |
| KYLIN_CATEGORY_GROUPINGS | USER_DEFINED_FIELD1 | 用户定义字段1 |
| KYLIN_CATEGORY_GROUPINGS | USER_DEFINED_FIELD3 | 用户定义字段3 |
| KYLIN_CATEGORY_GROUPINGS | UPD_DATE | 更新日期 |
| KYLIN_CATEGORY_GROUPINGS | UPD_USER | 更新负责人 |
| KYLIN_CATEGORY_GROUPINGS | META_CATEG_NAME | 一级分类 |
| KYLIN_CATEGORY_GROUPINGS | CATEG_LVL2_NAME | 二级分类 |
| KYLIN_CATEGORY_GROUPINGS | CATEG_LVL3_NAME | 三级分类 |
| KYLIN_CAL_DT | CAL_DT | 日期 |
| KYLIN_CAL_DT | WEEK_BEG_DT | 周始日期 |
2.2 数据导入
2.2.1 导入Hive数据源
目前,Kylin支持Hive作为默认的输入数据源。为了使用Kylin中自带的样例数据,需要把数据表导入Hive中。在Kylin安装目录的bin文件夹中,有一个可执行脚本,可以把样例数据导入Hive:
$KYLIN_HOME/bin/sample.sh
脚本执行成功之后,进入Hive CLI,确认这些数据已经导入成功,命令如下:
hive
hive> show tables;
OK
kylin_cal_dt
kylin_category_groupings
kylin_sales
Time taken: 0.127 seconds, Fetched: 3 row(s)
hive> select count(*) from kylin_sales;
Query ID = root_20160707221515_b040318d-1f08-44ab-b337-d1f858c46d7d
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapreduce.job.reduces=
Starting Job = job_1467288198207_0129, Tracking URL = http://sandbox.hortonworks.com:8088/proxy/application_1467288198207_0129/
Kill Command = /usr/hdp/2.2.4.2-2/hadoop/bin/hadoop job -kill job_1467288198207_0129
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2016-07-07 22:15:11,897 Stage-1 map = 0%, reduce = 0%
2016-07-07 22:15:17,502 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.64 sec
2016-07-07 22:15:25,039 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 3.37 sec
MapReduce Total cumulative CPU time: 3 seconds 370 msec
Ended Job = job_1467288198207_0129
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 3.37 sec HDFS Read: 505033 HDFS Write: 6 SUCCESS
Total MapReduce CPU Time Spent: 3 seconds 370 msec
OK
10000
Time taken: 24.966 seconds, Fetched: 1 row(s)
2.2.2 创建项目
打开Kylin的Web UI(
在Web UI的左上角选择刚刚创建的项目,表示我们接下来的全部操作都在这个项目中,在当前项目的操作不会对其他项目产生影响。
2.2.3 同步Hive表
需要把Hive数据表同步到Kylin当中才能使用。
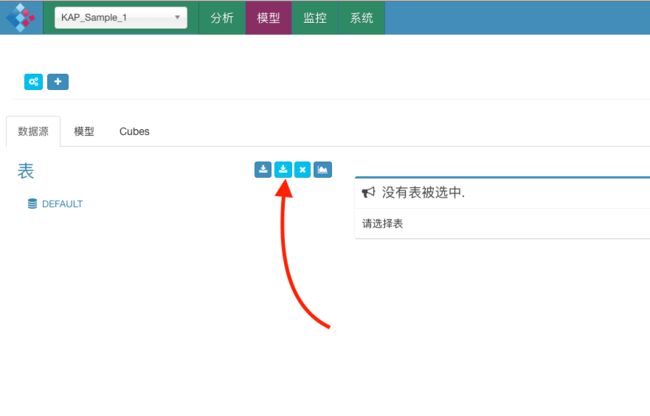
在弹出的对话框中展开default数据库,并选择需要的三张表,如图所示
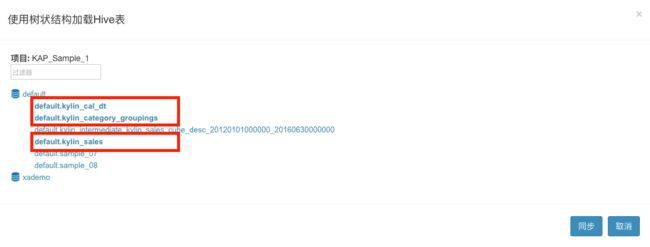
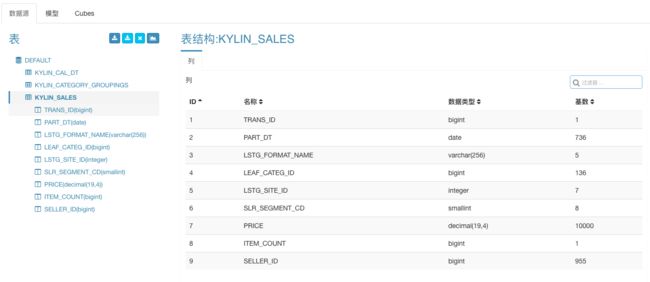
导入后系统会自动计算各表各列的维数,以掌握数据的基本情况。稍等几分钟后,我们可以通过数据源表的详情页查看这些信息。
2.3 创建数据模型(model)
在数据源就绪的基础之上,我们开始创建数据模型。以Kylin自带的数据集为例,该数据集的数据模型包含1个事实表和2个维表,表间通过外键进行关联。实际上,并不是表上所有的字段都有被分析的需要,因此我们可以有目的地仅选择所需字段添加到数据模型中;然后,根据具体的分析场景,把这些字段设置为维度或度量。
打开Kylin的Web UI,在左上角项目列表中选择刚刚创建的KAP_Sample_1项目,然后进入“模型”页面,并创建一个模型。
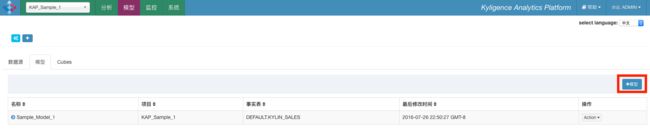
第一步,在基本信息页,输入模型名称为Sample_Model_1,然后单击下一步。
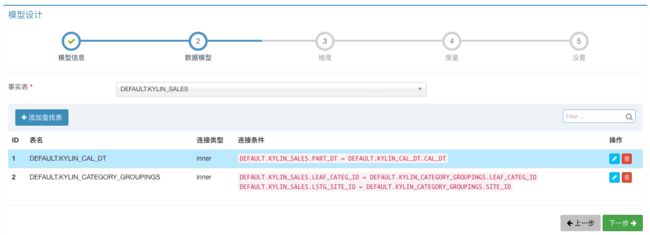
第二步,为模型选择事实表(Fact Table)和查找表(Lookup Table)。根据星型模型结构,选择KYLIN_SALES为事实表,然后添加KYLIN_CAL_DT和KYLIN_CATEGORY_GROUPINGS作为查找表,并设置好连接条件:
KYLIN_CAL_DT 连接类型:Inner 连接条件:
DEFAULT.KYLIN_SALES.PART_DT = DEFAULT.KYLIN_CAL_DT.CAL_DT
KYLIN_CATEGORY_GROUPINGS 连接类型:Inner 连接条件:
KYLIN_SALES.LEAF_CATEG_ID = KYLIN_CATEGORY_GROUPINGS.LEAF_CATEG_ID
KYLIN_SALES.LSTG_SITE_ID = KYLIN_CATEGORY_GROUPINGS.SITE_ID
下图是设置好之后的界面:
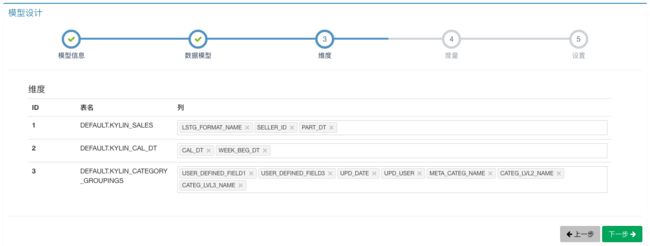
第三步,从上一步添加的事实表和查找表中选择需要作为维度的字段。一般的,时间经常用来作为过滤条件,所以我们首先添加时间字段。此外,我们再添加商品分类、卖家ID等字段为维度,具体情况如下图所示:
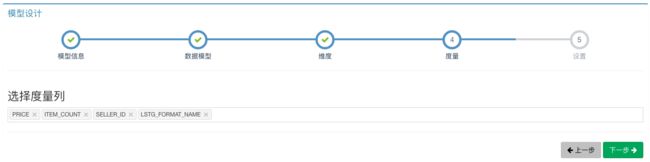
第四步,根据业务需要,从事实表上选择衡量指标的字段作为度量。例如,PRICE字段用来衡量销售额,ITEM_COUNT字段用来衡量商品销量,SELLER_ID用来衡量卖家的销售能力。最终结果如下图所示:
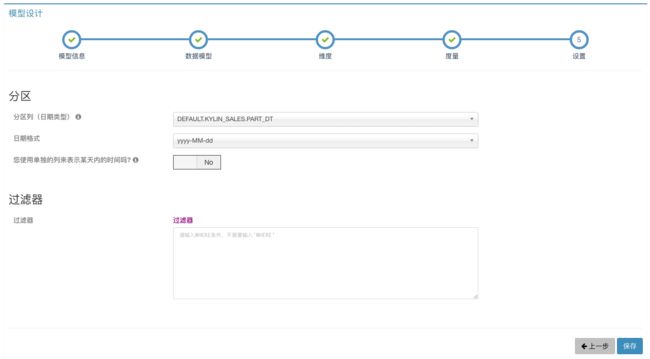
第五步,设置根据时间分段。一般来说,销售数据都是与日俱增的,每天都会有新数据通过ETL到达Hive中,需要选择增量构建方式构建Cube,所以需要选择用于分段的时间字段DEFAULT.KYLIN_SALES.PART_DT。根据样例数据可以看到,这一列时间的格式是yyyy-MM-dd,所以选择对应的日期格式。此外,我们既不需要设置单独的分区时间列,也不需要添加固定的过滤条件。设置效果如下图所示。
最终,单击“保存”按钮,到此数据模型就创建成功了。
2.4 创建Cube
在创建好数据模型的基础上,我们还需要根据查询需求定义度量的预计算类型、维度的组合等,这个过程就是Cube设计的过程。本文将以Kylin自带的样例数据为例,介绍Cube的创建过程。
打开Kylin的Web UI,首先选择KAP_Sample_1项目,跳转到模型页面,然后按照下图所示创建一个Cube。
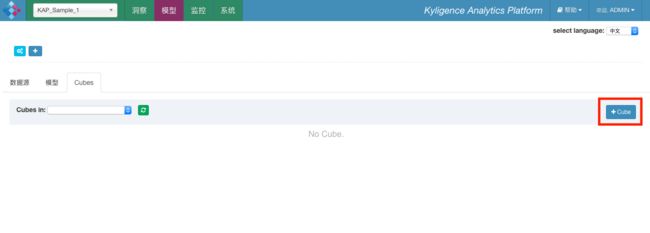
第一步,在“模型名称”中选择Sample_Model_1,输入新建Cube的名称Sample_Cube_1,其余字段保持默认,然后单击“下一步”。
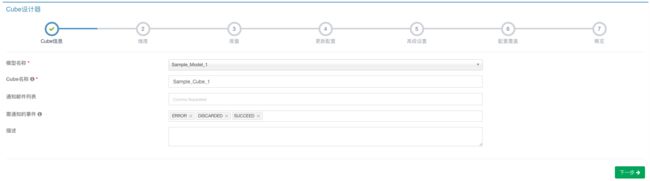
第二步,从数据模型的维度中选择一些列作为Cube的维度。这里的设置会影响到生成的Cuboid数量,进而影响Cube的数据量大小。 在KYLIN_CATEGORY_GROUPINGS表里,和商品分类相关的三个字段(META_CATEG_NAME、CATEG_LVL2_NAME、CATEG_LVL3_NAME)都可能出现在过滤条件中,我们先把他们添加为普通类型维度。因为从查询表上添加普通维度不能通过自动生成器(Auto Generator)生成,因此采用手动添加方式,过程如下:
单击“添加维度”按钮,然后选择“普通维度”。
针对每一个维度字段,首先在Name输入框中输入维度名称,在Table Name中选择KYLIN_CATEGORY_GROUPINGS表,然后在Column Name中选择相应的列名。
此外,在查询中还经常把时间作为过滤或聚合的条件,如按周过滤、按周聚合等。这里我们以按周为例,需要用到KYLIN_CAL_DT中的WEEK_BEG_DT字段,但是该字段实际上可以由PART_DT字段决定,即根据每一个PART_DT值可以对应出一个WEEK_BEG_DT字段,因此,我们添加WEEK_BEG_DT字段为可推倒维度。 同样的,KYLIN_CATEGORY_GROUPINGS表中还有一些可作为可推到维度的字段,如USER_DEFINED_FIELD1、USER_DEFINED_FIELD3、UPD_DATE、UPD_USER等。
在事实表上,表征交易类型的LSTG_FORMAT_NAME字段也会用于过滤或聚合条件,因此,我们再添加LSTG_FORMAT_NAME字段作为普通维度。 最终,维度的设置结果如下图所示:
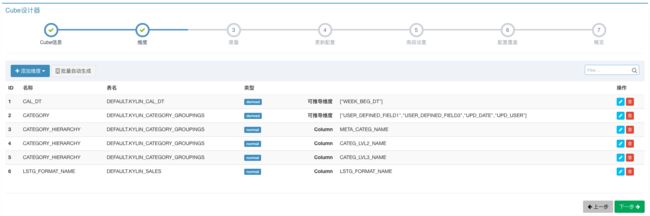
第三步,根据数据分析中的聚合需求,我们需要为Cube定义度量的聚合形式。默认的,根据数据类型,系统会自动创建好一些COUNT()聚合和SUM()聚合,用于考量交易订单的数量或者卖出商品的总量。默认建好的聚合仍然可以手动修改或删除。在这个案例中,我们还需要通过PRICE的不同聚合形式考量销售额,如总销售额为SUM(PRICE)、最高订单金额为MAX(PRICE)、最低订单金额为MIN(PRICE)。因此,我们手动创建三个度量,分别选择聚合表达式为SUM、MIN、MAX,并选择PRICE列作为目标列。
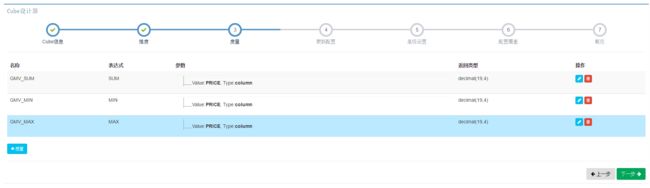
其次,我们还需要通过COUNT(DISTINCT SELLER_ID)考量卖家个数。根据前面章节的介绍,Kylin默认使用HyperLogLog算法进行COUNT_DISTINCT的计算,该算法是个近似算法,在创建度量时需要选择一个近似度,本案例对精确性要求不高,为了提升查询性能,我们选择精度较低的“Error Rate < 9.75%”。同样的,我们再创建一个COUNT(DISTINCT LSTG_FORMAT_NAME)的度量考量不同条件下的交易类型。
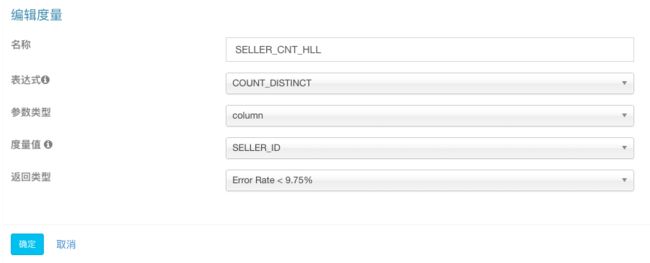
在销售业务分析的场景中,往往需要挑选出销售业绩最好的商家,这时候就需要TOP-N的度量了。在这个例子中,我们会选出SUM(PRICE)最高的一些SELLER_ID,实际上就是执行如下的SQL语句:
SELECT SELLER_ID, SUM(PRICE) FROM KYLIN_SALES GROUP BY SELLER_ID ORDER BY SUM(PRICE)
因此,我们创建一个TOP-N的度量,选择PRICE字段作为SUM/OPDER BY字段,选择SELLER_ID字段作为GROUP BY字段,并选择TOPN(100)作为度量的精度。
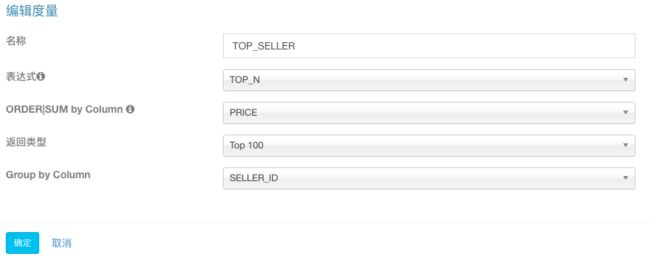
最终添加的度量如下图所示:

第四步,我们对Cube的构建和维护进行配置。一般的,一个销售统计的SQL查询往往会按月、周进行过滤和聚合,所以我们可以设置Cube自动按周、月进行自动合并,即每7天进行一次合并,每4周(28天)进行一次合并,设置“触发自动合并的时间阈值”如下所示:

因为存在对于历史订单的查询需求,我们在此不对Cube做自动清理,所以需要设置“保留时间阈值”为0。
在创建数据模型的时候我们提到,我们希望采用增量构建方式对Cube进行构建,并选择了PART_DT字段作为分区时间列。在创建Cube时,我们需要指定Cube构建的起始时间,在这个例子中,根据样例数据中的时间条件,我们选择2012-01-01 00:00:00作为分区起始时间。
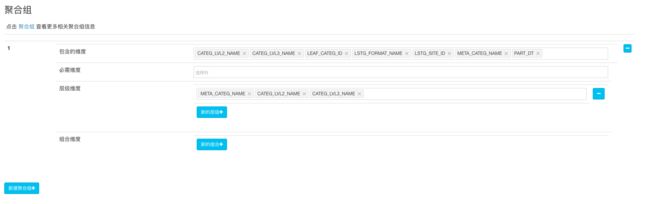
第五步,通过对Cube进行高级设置优化Cube的存储大小和查询速度,主要包括聚合组和Rowkey。在前文我们提到,添加聚合组可以利用字段间的层级关系和包含关系有效地降低Cuboid的数量。在这个案例当中,与商品分类相关的三个字段(META_CATEG_NAME、CATEG_LVL2_NAME、CATEG_LVL3_NAME)实际上具有层级关系,如一级类别(META_CATEG_NAME)包含多个二级类别(CATEG_LVL2_NAME),二级类别又包含多个三级类别(CATEG_LVL3_NAME),所以,我们可以为它们创建层级结构的组合(Hierarchy Dimensions)。最终,聚合组的设计如下图所示:
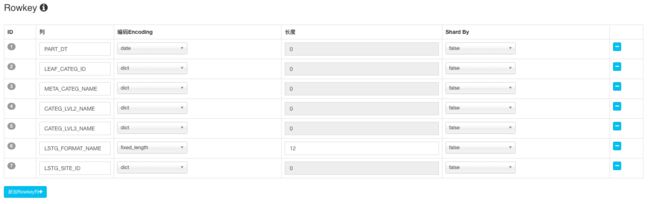
由于参与Cuboid生成的维度都会作为Rowkey,因此我们需要把这些列添加为Rowkey当中。在这个案例中,总共需要添加7个Rowkey。在每个Rowkey上,还需要为列值设置编码方法。在这个案例中,我们除了把LSTG_FORMAT_NAME设置为fixed_length类型(长度为12)外,将其余的Rowkey都设置为dict编码。 Rowkey的顺序对于查询性能来说至关重要,如第六章所讲,一般把最经常出现在过滤条件中的列放置在Rowkey的前面,在这个案例中,我们首先把PART_DT放在Rowkey的第一位。接下来,按照层级把商品分类的字段跟随其后。最终,Rowkey的设置如下图所示:
对Plus版本:Raw Table是Plus版本的特有功能。如果启用,Kylin将在构建Cube之外也保存所有的原始记录,支持高速的明细查询。Raw Table还处于beta测试阶段,仅支持最简单的启用或者不启用。其他的Raw Table配置参数暂时不起作用。
第六步,设置Cube的配置覆盖。在这里添加的配置项可以在Cube级别覆盖从kylin.properties配置文件读取出来的全局配置。在这个案例中,我们可以直接采用默认配置,在此不做任何修改。 第七步,对Cube的信息进行概览。请读者仔细确认这些基本信息,包括数据模型名称、事实表以及维度和度量个数。确认无误后单击“保存”按钮,并在弹出的确认提示框中选择“Yes”。 最终,Cube的创建就完成了。我们可以刷新Model页面,在Cube列表中就可以看到新创建的Cube了。因为新创建的Cube没有被构建过,是不能被查询的,所以状态仍然是“禁用”。

2.5 构建Cube
在创建好Cube之后,只有对Cube进行构建,才能利用它执行SQL查询。本文以Kylin样例数据为例,介绍Cube构建的过程。
初次构建
首先打开Kylin的Web UI,并选择Kylin_Sample_1项目,然后跳转到模型页面,找到Cube列表。 第一步,在Cube列表中找到Kylin_Sample_Cube_1。单击右侧的Action按钮,在弹出的菜单中选择“构建”。

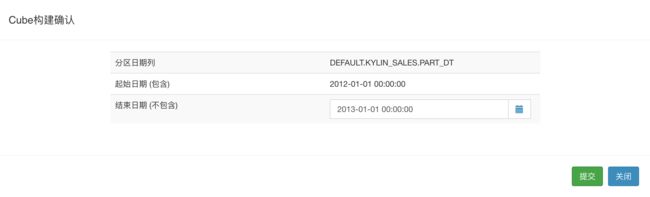
第二步,在弹出的Cube构建确认对话框中确认Cube的分段时间列(Partition Date Column)是DEFAULT.KYLIN_SALES.PART_DT,以及起始时间是2012-01-01 00:00:00。在KAP中,一次构建会为Cube产生一个新的Segment,每次的SQL查询都会访问一个或多个符合条件的Segment;我们需要尽可能地让一个Segment更好地适用于查询条件,因此我们可以按年构建,即每个年份构建一个Segment。在这个例子中,我们输入结束日期(End Date)为2013-01-01 00:00:00。设置完成后单击Submit按钮。
注意:增量构建是具体按年构建还是按月构建应该根据实际的业务需求、ETL时效及数据量大小而定。如果一次构建的数据量过大,可能导致构建时间过长,或出现内存溢出等异常。在当前的样例数据中,数据量较小,按年构建是可以顺利完成的。
当任务成功提交之后,切换到Monitor页面,这里会列出所有的任务列表。我们找到列表最上面的一个任务(名称是:Kylin_Sample_Cube_1 - 20120101000000_20130101000000),这就是我们刚刚提交的任务。在这一行双击或单击右侧的箭头图标,页面右侧会显示当前任务的详细信息。 待构建任务完成,可以在Monitor页面看到该任务状态已被置为完成(Finished)。这时候,第一个Segment就构建完成了。前往Cube列表中查看,会发现该Cube的状态已被置为“就绪(Ready)”了。
增量构建
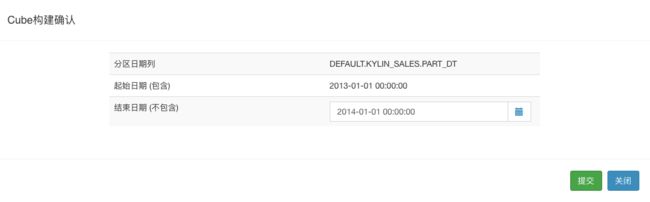
在第一个Segment构建完成之后,我们开始构建第二个Segment。首先在Model页面的Cube列表中找到该Cube,单击右侧的Actions按钮,然后选择“Build”,打开Cube构建确认对话框。 在这个对话框中,首先确认起始时间(Start Date)是2013-01-01 00:00:00,因为这是上次构建的结束日期,为保障所构建数据的连续性,Apache Kylin自动为新一次构建的起始时间更新为上次构建的结束日期。同样的,在结束时间(End Date)里输入2014-01-01 00:00:00,然后单击Submit按钮,开始构建下一年的Segment。
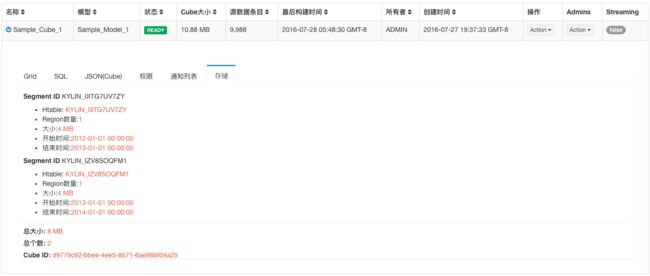
待构建完成,我们可以在Cube的详情页中查看,发现Cube的两个Segment都已就绪。
参考资料
- http://kylin.apache.org/cn/
- https://kyligence.gitbooks.io/kap-manual/content/zh-cn/introduction/concepts.cn.html
- http://webdataanalysis.net/web-data-warehouse/multidimensional-data-model/
- http://www.cnblogs.com/mq0036/p/4155832.html

欢迎关注公众号: FullStackPlan 获取更多干货哦~